
- Google vừa open-source Magika — model deep learning 1MB phát hiện 200+ loại file với F1 99%, nhanh 5ms/file chỉ trên CPU.
- Đang chạy scan hàng trăm tỷ file/tuần trên Gmail, Drive, Safe Browsing và VirusTotal.
- Version 1.0 vừa ra mắt với engine Rust mới.
TL;DR
Magika là tool phát hiện loại file dùng deep learning do Google mở mã, Apache 2.0. Model chỉ ~1MB, F1 99% trên 200+ content types, inference 5.77ms/file chạy trên single CPU, không cần GPU. Đã deploy nội bộ Google trên Gmail, Drive, Safe Browsing xử lý hàng trăm tỷ file mỗi tuần, cải thiện độ chính xác phát hiện file type lên 50% so với hệ rule-based cũ. Version 1.0 vừa ra mắt ngày 7/11/2025 với engine viết lại bằng Rust, gấp đôi số content types so với bản cũ. Cài 1 dòng: pip install magika.

Có gì mới
Magika không phải là một tool "magic bytes" truyền thống. Thay vì đọc vài byte đầu file rồi match signature, nó chạy một neural network được train trên dataset cực lớn để hiểu nội dung thực của file.
- Thời điểm: Google open-source Magika lần đầu 15/2/2024. Bản ổn định 1.0 ra mắt 7/11/2025 — viết lại core bằng Rust, tăng số content types hỗ trợ từ ~113 lên hơn 200.
- Model rất nhẹ: qua quantization + pruning, weights chỉ còn ~1MB. Training làm bằng Keras/TensorFlow, inference runtime dùng ONNX Runtime (nhanh hơn TF ~15 lần khi load model).
- Kiến trúc input thú vị: model đọc 3 block 512 byte từ đầu, giữa và cuối file, one-hot encode rồi đưa qua 2 Dense layer (256-dim, GeLU) + global max pooling + softmax. Không cần unpack DOCX, APK, JAR — đọc thẳng byte là đủ.
- Bindings đầy đủ: CLI Rust, Python API, JavaScript/TypeScript (npm), Go (WIP). Có web demo chạy 100% trong browser.
Vì sao đáng chú ý
Content-type detection tưởng là bài toán "đã giải" từ 50 năm nay với libmagic và lệnh file. Nhưng thực tế, mọi pipeline upload, malware scanner, email filter đều dựa vào bước này — và sai ở đây nghĩa là file .exe giả dạng .jpg lọt qua cửa.
Các tool cũ dựa vào magic bytes — vài byte đầu file. JavaScript bị minify, binary bị pack, malware bị obfuscate, extension bị đổi tay → signature fail. Magika bỏ qua signature hoàn toàn, nhìn vào toàn bộ "hình dạng" byte của file.
Con số ấn tượng nhất: sau khi thay hệ rule-based bằng Magika nội bộ Google, độ chính xác phát hiện file type tăng 50%, số file được route vào AI malware scanner chuyên dụng tăng 11%, và tỷ lệ file "không xác định" giảm xuống còn 3%.
Con số kỹ thuật
| Thông số | Giá trị |
|---|---|
| Training dataset | ~100M file, 200+ content types |
| F1 score trung bình | 99% (binary: 100%, text: 99%) |
| Model size | ~1 MB (quantized, pruned) |
| Inference bulk | 5.77 ms/file (single CPU) |
| Inference 8 CPUs | 1.39 ms/file |
| Init overhead | ~86 ms (1 lần khi load model) |
| Framework train | Keras + TensorFlow |
| Framework infer | ONNX Runtime |
Điểm mà Magika bẻ gãy các tool cũ là trên text — nơi magic bytes gần như vô dụng: ini +52% F1, vba +49%, markdown +45%, xml +35%, batch +32%. json và sql đạt 99% F1, trong khi TrID chỉ làm được 9% và 6% tương ứng cho chính 2 loại đó.
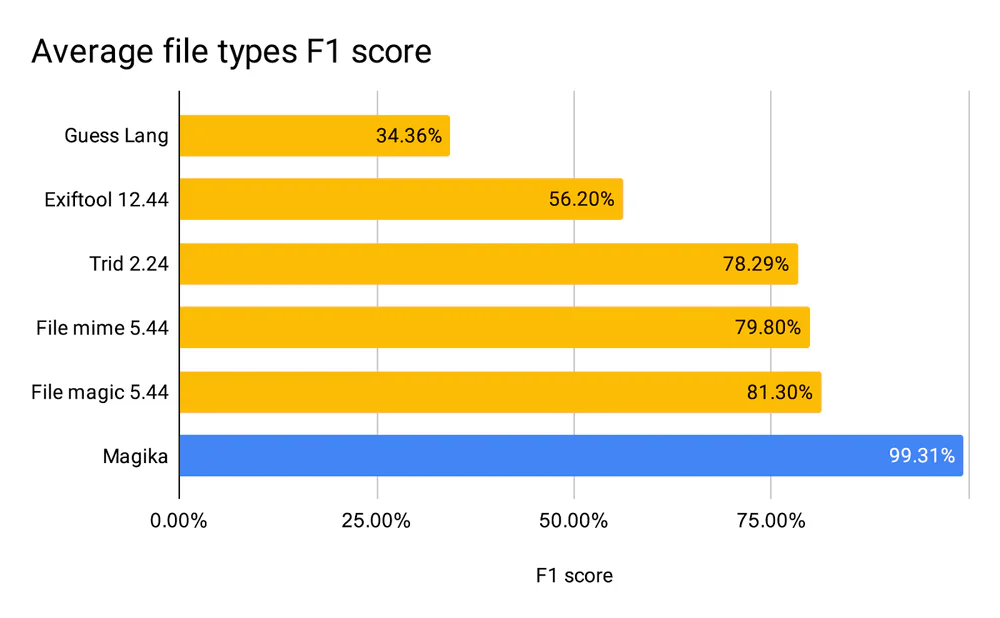
So với libmagic, TrID, guesslang
| Tool | F1 (supported) | F1 (all types) | Bulk speed |
|---|---|---|---|
| Magika | 99% | 99% | 5.77 ms |
| file | 88% | 70% | 0.75 ms |
| file-mime | 88% | 70% | 0.67 ms |
| exiftool | 87% | 39% | 6.36 ms |
| trid | 87% | 70% | 51.57 ms |
| guesslang | 77% | 19% | 307.66 ms |
file vẫn nhanh nhất cho single-shot vì không có model phải load. Nhưng ngay khi scan hàng loạt, Magika ngang ngửa tốc độ trong khi ăn đứt về độ chính xác, đặc biệt với text và code. guesslang — tool ML duy nhất cạnh tranh — bị Magika vượt xa cả tốc độ (53×) lẫn độ chính xác vì Magika dùng ONNX thay vì TensorFlowJS.
Ai dùng, dùng vào đâu
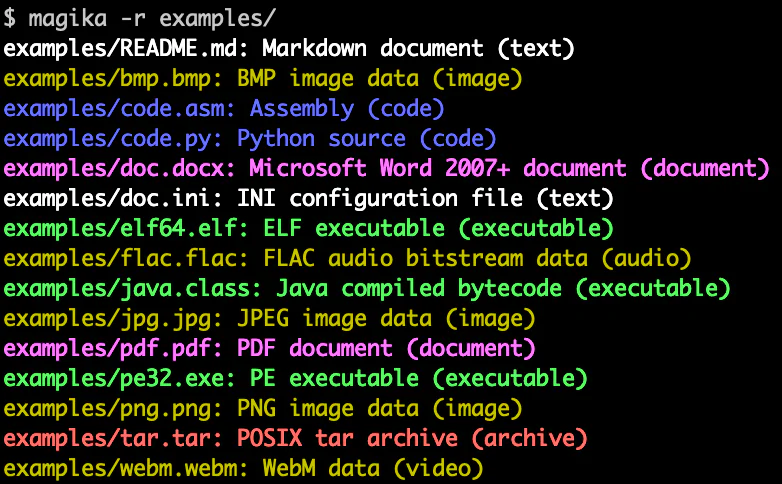
Trong Google: Gmail (đã chạy production hơn 6 tháng tính từ thời điểm paper), Drive, Safe Browsing — tổng cộng hàng trăm tỷ file/tuần. VirusTotal dùng Magika làm pre-filter trước khi đưa vào Code Insight (analyze bằng generative AI). Gmail dùng để chặn executable đính kèm bị đổi tên và route MS Office đáng nghi vào scanner chuyên dụng.
Ngoài Google:
- Malware scanner + email filter: chặn
.exegiả.jpg, PowerShell script bị obfuscate. - Cloud storage: auto-categorize file sau khi upload, áp compression/ACL theo đúng loại.
- Web app upload: validate file người dùng upload, tránh tin mù extension.
- IDE: Google đang thương thảo với VS Code để Magika thay
guesslanglàm tool phát hiện ngôn ngữ. - CI/CD security: pre-filter 5ms trước khi đưa file vào heavy scanner.
Dùng thử trong Python:
pip install magikafrom magika import Magika
m = Magika()
res = m.identify_path("example.js")
print(res.output.ct_label) # javascriptGiới hạn & giá
- Init cost ~86 ms: chậm hơn
filecho 1 file đơn. Magika chỉ thắng khi scan bulk. - File < 100 byte: không đủ dữ liệu, model trả về label chung chung như
txthoặcunknown. - Polyglot file: model chỉ trả về 1 content type. File được cố tình design valid nhiều format cùng lúc (Python + PHP + bash) là điểm yếu đã biết.
- Adversarial ML: model mở → attacker có thể thêm nhiễu cực nhỏ để làm model misclassify mà vẫn giữ payload chạy được.
- Bias dataset: training từ GitHub + VirusTotal. Format hiếm trong môi trường enterprise đặc thù có thể không nằm trong 200+ types.
- Giá: miễn phí 100%, Apache 2.0. Repo
google/magikahiện 15.3k stars, 831 forks, 43 contributors. Không cần GPU.
Roadmap tiếp theo
- Go binding (đang work-in-progress).
- Phân biệt fine-grained: C vs C++, JavaScript vs TypeScript, INI vs TOML — nhu cầu từ phía VS Code.
- Thêm content types mới: cộng đồng có thể đóng góp 10K+ sample để retrain model cho format mới.
- Paper "Magika: AI-Powered Content-Type Detection" đã publish tại ICSE 2025 (IEEE/ACM International Conference on Software Engineering).
Nguồn: Google Open Source Blog, github.com/google/magika, ICSE 2025 paper, Linuxiac (Magika 1.0 release).
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ