
- AC/DC coevolves a population of LLMs with an archive of AI-generated tasks.
- A task force of 8 small evolved models beats a 72B baseline and closes the GPT-4o best-of-N gap from -3.17 to -1.02.
- Sakana's new ICLR 2026 paper argues collective intelligence beats monolithic scaling.
TL;DR
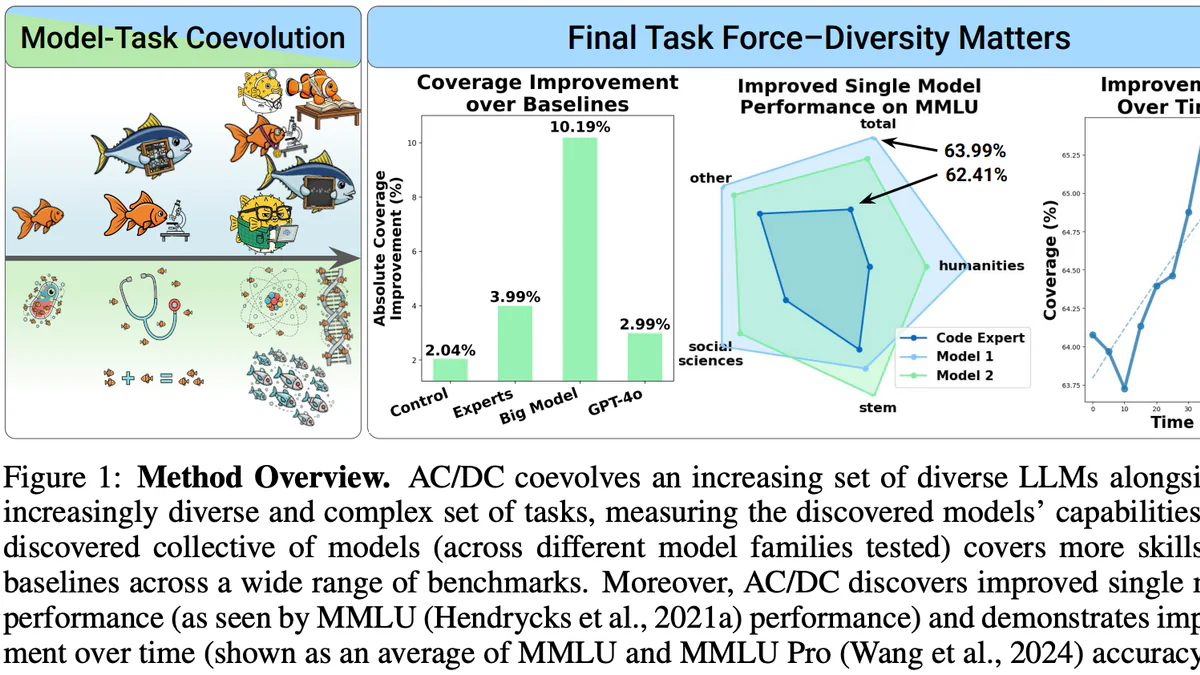
Sakana AI just dropped AC/DC — Assessment Coevolving with Diverse Capabilities — at ICLR 2026. Instead of training one ever-larger monolith, AC/DC coevolves a population of small LLMs alongside an archive of synthetic tasks written by an AI-scientist model. Quality-Diversity selection keeps models that solve different problems, not just models with the highest average score. Headline claim: a task force of 8 small evolved models outperforms a single 72B baseline, with coverage improvement of 10.19% versus 2.99% for GPT-4o and 2.04% for the control. Code is Apache 2.0.
What's new
The current frontier-model paradigm is: collect a static dataset, run one giant training job, ship. To extend capability, you start over with a bigger dataset and a bigger model. AC/DC attacks that assumption directly. Authors Andrew Dai, Boris Meinardus, Ciaran Regan, Yingtao Tian, and Yujin Tang argue that open-endedness — the coevolution of models and tasks in a single run — can surface novel skills without hand-authored datasets or reward functions.
Concretely, AC/DC runs two evolutionary loops in parallel:
- Model loop: evolutionary model merging. New candidates are produced by crossover over the weights of existing models in the archive, plus a weight-noising mutation.
- Task loop: a "scientist" LLM mutates existing task descriptions into new, increasingly novel and complex natural-language tasks.
Both archives grow together, so difficulty keeps pace with capability.
How it works
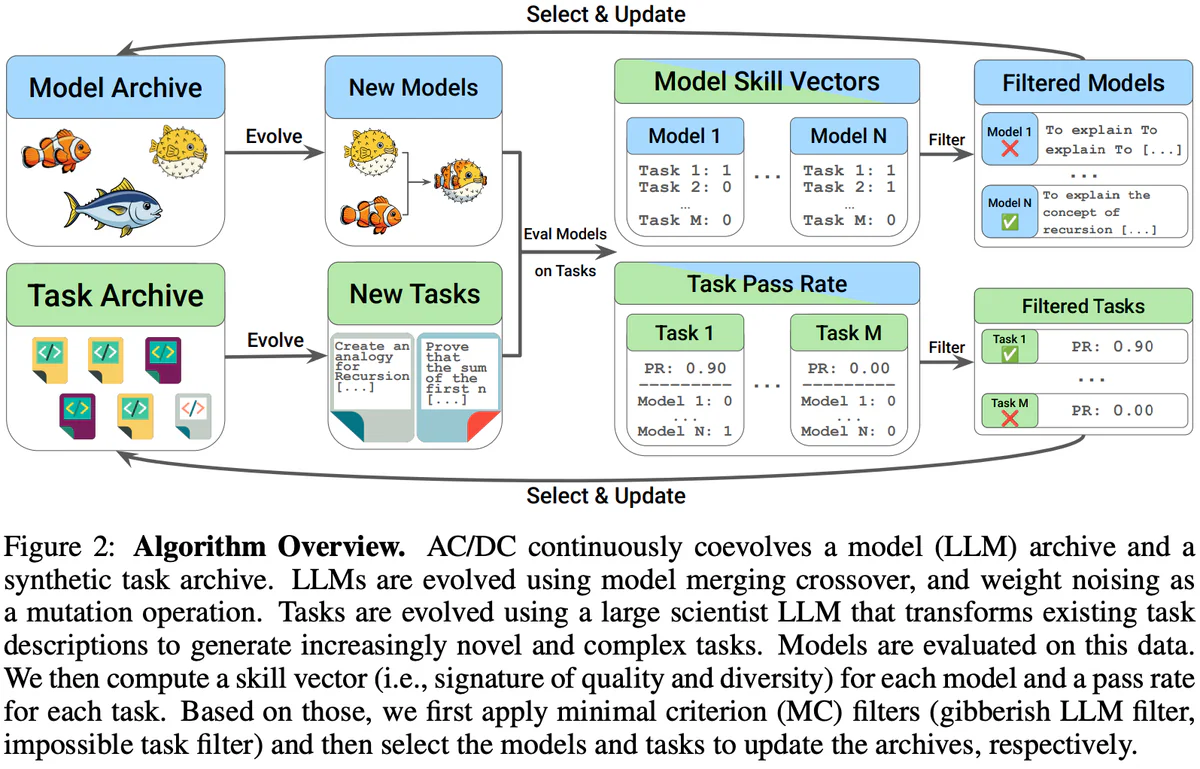
Every generation, models are evaluated on the current task archive. For each model you get a skill vector (per-task signal of quality + diversity); for each task you get a pass rate. Minimal-criterion filters drop gibberish outputs and impossible tasks. Then Dominated Novelty Search (DNS) — a Quality-Diversity selector — picks which models and tasks update their respective archives. Crucially, a model is kept not because it scores high on average, but because it is non-dominated in the (performance × novelty) space: it solves problems no one else in the archive can.
Under the hood: Hydra configs, vLLM servers for the scientist and embedding models, Celery distributed workers for evaluation, fractional-GPU scheduling, and W&B logging. Standard recipe, unusual objective.
Results
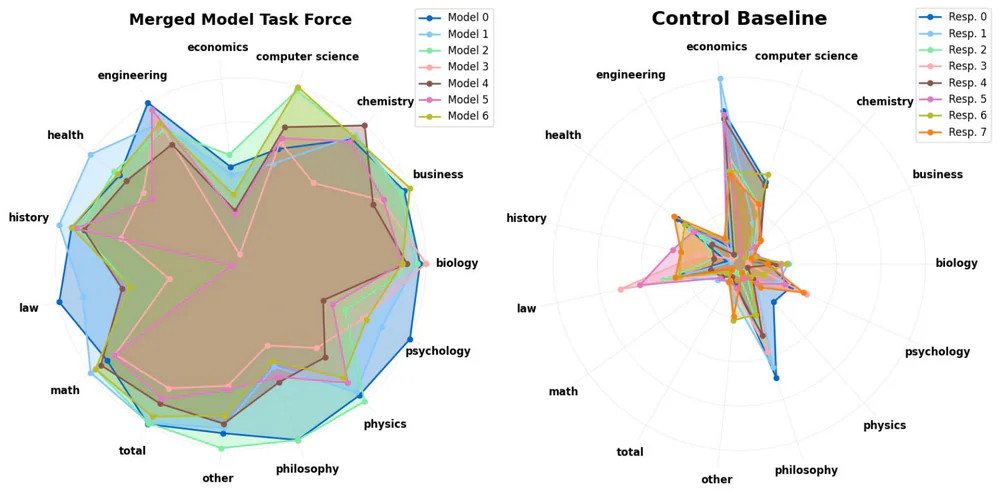
On MMLU-Pro per-subject coverage, the AC/DC task force (left) sweeps outward across economics, computer science, chemistry, biology, history, law, math, philosophy — almost every axis. The control baseline (right) collapses to a few spikes. AC/DC's big-model variant hits 10.19% absolute coverage improvement over the weakest baseline, compared to:
- Control: +2.04%
- Curated expert set: +3.99%
- GPT-4o: +2.99%
Single-model gains are real too: evolved Model 1 reaches 63.99% on MMLU total vs 62.41% for Model 2 — and both improve over time as the task archive keeps mutating. No benchmark optimization was used in the loop.
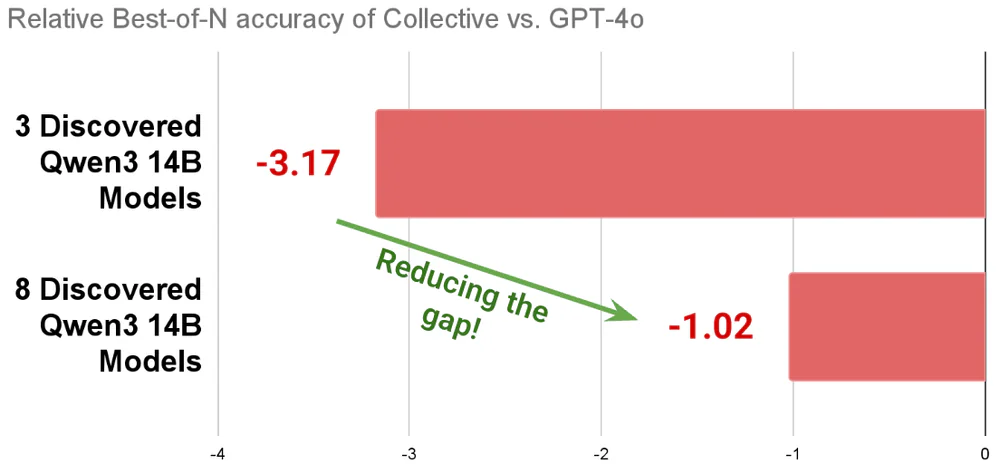
The best-of-N chart is the clearest story. Relative to GPT-4o on a best-of-N oracle, 3 discovered Qwen3-14B experts sit at -3.17. Scale the collective to 8 experts and the gap collapses to -1.02. The experts genuinely specialize — same question, different correct approaches — which is exactly what best-of-N rewards.
Comparison
| Approach | What evolves | Task set | Selection |
|---|---|---|---|
| Evolutionary Model Merge (2024) | Models only | Static | Performance |
| CycleQD | Agentic experts | Static | Quality-Diversity |
| M2N2 | Models (niches) | Static | Attraction & diversity |
| AC/DC | Models + tasks | Coevolved | DNS (QD) |
The structural novelty is the second evolving archive. Everything Sakana shipped before froze the tasks. AC/DC lets the curriculum write itself.
Use cases
- Parameter-efficient deployment: run an ensemble of small experts on commodity GPUs instead of provisioning one 70B+ monolith.
- Multi-agent best-of-N: complementary experts propose genuinely different correct solutions, improving oracle selection pipelines.
- Open-ended capability discovery: useful for labs and teams that want to surface new skills without hand-authoring datasets or reward functions.
- Breadth without brute force: code + reasoning + knowledge coverage from an evolved population, not from one giant model.
Limitations & pricing
AC/DC is open source under Apache 2.0, so there is no pricing — but it still wants real compute. Two parallel evolutionary loops plus distributed evaluation is not a laptop workload. The public project page is light on absolute SOTA numbers; the headline is coverage, not single-metric leadership. You also need a capable scientist LLM to author tasks, so AC/DC bootstraps on top of an already-strong model rather than from scratch. Finally, human-authored benchmarks like MMLU-Pro are still used for cross-checks — AC/DC avoids optimizing against them, it does not replace them.
What's next
AC/DC will be presented at ICLR 2026 on Saturday April 25, 15:15 BRT, Pavilion 3, Booth #607. The paper is on arXiv as 2604.14969 and the code is live at SakanaAI/AC-DC. The obvious next moves, implied by the method: bigger populations, richer scientist-LLM task generators, and wiring AC/DC archives into inference-time collective systems like Sakana's AB-MCTS. If you believe the collective-intelligence thesis, the ceiling here is higher than one more generation of monoliths.
Nguồn: acdc-llm.github.io, arXiv:2604.14969, OpenReview, GitHub.



