
- Allen Institute for AI vừa release đầy đủ training + inference code của WildDet3D — model monocular 3D detection 1.2B params, đánh bại mọi baseline trên Omni3D (34.2 AP text, 36.4 AP box), xử lý 13.499 category ngoài đời thực chỉ với 12 epoch thay vì 80–120 như trước.
TL;DR
Ngày 21/4/2026, Ai2 release training code + updated inference code + data-prep scripts cho WildDet3D — biến model monocular 3D detection 1.2B params của họ thành một trong những release 3D perception mở nhất từ trước đến nay. Chỉ cần 1 tấm ảnh RGB, WildDet3D trả về 3D bounding box (vị trí, kích thước, hướng metric) cho bất kỳ object nào bạn mô tả bằng text, point click, hoặc 2D box, trên 13.499 category khác nhau. Khi có depth phụ (LiDAR, ToF, stereo), nó tự nuốt và tăng trung bình +20.7 AP.

Có gì mới trong drop 21/4?
Bản release đầu (7/4/2026) đã mở model weights, dataset, iOS app và web demo. Drop mới đây bổ sung mảnh ghép quan trọng nhất cho cộng đồng nghiên cứu:
- Full training code — pipeline 3 stage dùng
vis4d fit, global batch 128 (4/GPU × 8 GPU × 4 node) - Updated inference code — gọn hơn, hỗ trợ cả trường hợp không có camera intrinsic (auto-predict) và có sparse depth
- Data-prep scripts — pipeline sinh 3D box từ annotation 2D của COCO / LVIS / Objects365 / V3Det rồi verify bằng human
Thông báo đến từ tweet của @weikaih04, một trong các core contributor.
Vì sao đáng chú ý?
Spatial intelligence — hiểu object ở đâu trong không gian 3D, không chỉ là gì — là khối bài toán còn bị bỏ ngỏ. Hầu hết 3D detector cũ bị nhốt trong 3 cái hố:
- Chỉ hoạt động trên 1 domain hẹp (driving dataset hoặc indoor)
- Chỉ nhận 1 loại prompt (text hoặc box, không đồng thời)
- Giả định một cấu hình hardware cụ thể, không ingest được depth tuỳ chọn
WildDet3D giải cả 3 trong một kiến trúc thống nhất, và làm điều đó ở quy mô 1 triệu ảnh, 13.5K category — xa hơn mọi dataset 3D public từng có.
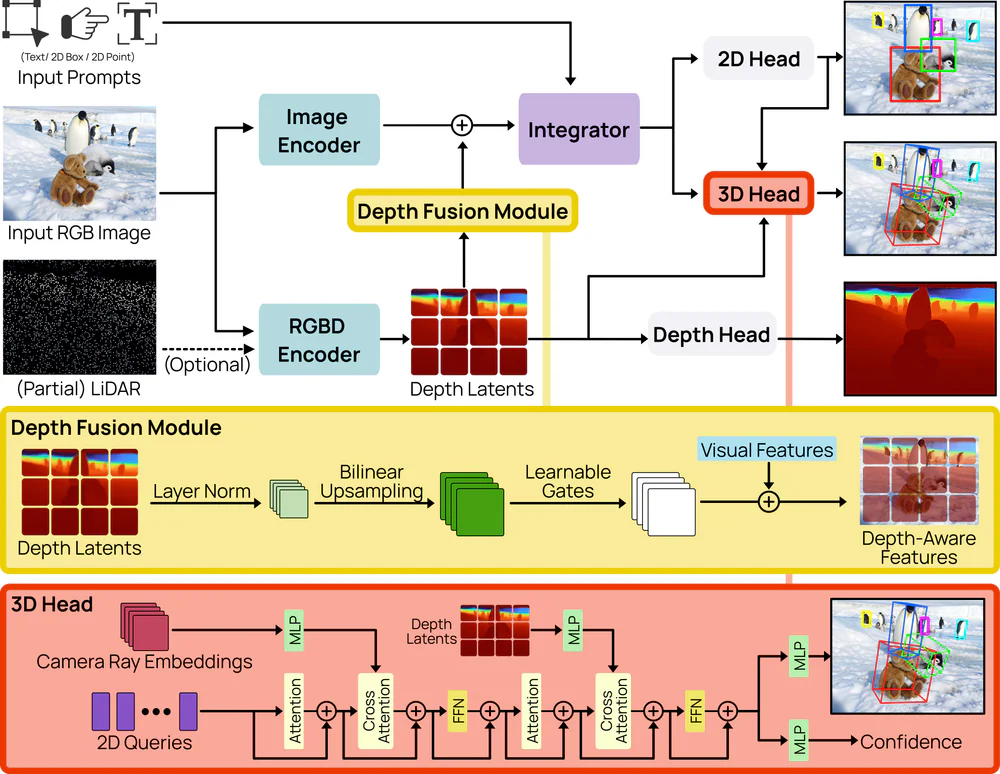
Kiến trúc & con số kỹ thuật
Dưới capo có 3 khối chạy song song:
- 2D detector trên SAM3 ViT backbone (1024-dim, 32 block, patch 14) — nhận cả 3 prompt type
- Geometry backend LingBot-Depth trên DINOv2 ViT-L/14 frozen — ước lượng depth per-pixel, dùng ray-aware decoder với spherical-harmonic encoding của camera ray, nên không cần nhánh calibration riêng
- 3D detection head — cross-attention fuse 2D evidence với depth feature, xuất đầy đủ 6-DoF box
| Property | Value |
|---|---|
| Params | ~1.2B |
| Backbone / Depth | SAM3 ViT + DINOv2 ViT-L/14 |
| Training epochs | 12 (vs 80–120 prior) |
| Dataset ảnh | 1.003.886 |
| 3D annotation (verified) | 3.910.855 |
| Category | 13.499 |
| Prompt types | Text · 2D point · 2D box |
| Aux input | Sparse / dense depth (LiDAR, ToF, stereo) |
So kè với state-of-the-art
WildDet3D set SOTA mới trên mọi benchmark được đánh giá. Đặc biệt gap khổng lồ trên novel category — nơi model cũ gần như không tổng quát hoá được.
| Benchmark | Prior best | WildDet3D | + Depth |
|---|---|---|---|
| Omni3D · text AP | 3D-MOOD Swin-B 30.0 | 34.2 | 41.6 |
| Omni3D · box AP | DetAny3D 34.4 | 36.4 | 45.8 |
| WildDet3D-Bench · text | 3D-MOOD 2.3 | 22.6 | 41.6 |
| WildDet3D-Bench · box | DetAny3D 7.8 | 24.8 | 47.2 |
| Argoverse 2 zero-shot · ODS | 23.8 | 40.3 | — |
| ScanNet zero-shot · ODS | 31.5 | 48.9 | — |
| Stereo4D · box AP | — | 7.5 | 27.7 |
Thú vị: trên novel category (không có trong training), WildDet3D đạt 38.6 ODS trên Argoverse 2 so với 14.8 của baseline tốt nhất — tức là gần gấp 2.6 lần. Cùng lúc, training rút từ 80–120 epoch xuống 12 epoch nhờ pretrained representation từ SAM3 + DINOv2.
Dùng để làm gì?
- Robot manipulation: generate zero-shot grasp pose cho Franka Emika Panda bằng cách transform 3D box dự đoán vào frame của robot.
- AR / VR: passthrough AR trên Meta Quest 3 — query "chair" bằng text, thấy 3D box metric neo đúng vị trí vật lý.
- iOS on-device: app demo dùng ARKit + LiDAR, vẽ AR overlay real-time cho text prompt và 2D box.
- VLM spatial reasoner: ghép với Molmo 2 — VLM lý luận, xuất 2D box, WildDet3D nâng lên 3D.
- Zero-shot 3D tracking: nhận output từ bất kỳ 2D tracker upstream nào, lift sang 3D frame-by-frame, không cần training tracking riêng.
- Autonomous driving: general street-scene 3D understanding, không bị nhốt trong 26 category của Argoverse.

Limitations & pricing
- License: Code và weights theo SAM License — research & educational use theo Ai2 Responsible Use Guidelines. Annotation của WildDet3D-Data thoáng hơn, CC BY 4.0.
- Compute: 1.2B params. iOS real-time chạy được nhờ ARKit offload; trên wearable như smart glasses vẫn phải server-side hoặc optimize thêm.
- Inference provider: chưa có HF provider deploy sẵn — phải tự host.
- Giá: Model, dataset, code đều free. Cost = GPU của bạn.
Next on the roadmap
TODO list trên repo cho thấy nhóm đã tick xong inference code, WildDet3D-Bench evaluation, training code. Hạng mục còn lại: evaluation code cho Omni3D, Argoverse 2, ScanNet để cộng đồng reproduce đủ các con số SOTA trong paper.
Với việc dataset + weights + training pipeline đều đã open, WildDet3D có thể trở thành "SAM của 3D detection" trong 2026 — một foundation model mà mọi ứng dụng spatial AI (robot, AR, xe tự lái, VLM agent) bắt đầu xây từ đó thay vì tự train từ 0.
Nguồn: Ai2 blog, project page, GitHub, Hugging Face.

