
- Ultralytics tung YOLOE-26 — mô hình mở rộng YOLO26 với khả năng instance segmentation theo text prompt, visual prompt hoặc prompt-free, chạy 161 FPS trên T4 GPU.
- Đây là đối thủ trực tiếp của YOLO-World, Grounding DINO nhưng nhẹ hơn hàng chục lần và giữ nguyên ưu điểm NMS-free của YOLO26.
TL;DR
YOLOE-26 là mô hình mới do Ultralytics công bố, tích hợp kiến trúc NMS-free của YOLO26 (ra mắt 14/01/2026) với paradigm open-vocabulary của YOLOE. Kết quả: segment được bất kỳ object nào chỉ bằng câu mô tả ("red apple", "bird scooter"), ảnh tham chiếu, hoặc chế độ prompt-free tự quét 4,585 lớp có sẵn. Bản L đạt 36.8% mAP LVIS ở 161 FPS trên T4 GPU — nhanh hơn GLIP/Grounding DINO cả bậc độ lớn trong khi duy trì flexibility của vision-language foundation model.

Có gì mới
YOLOE-26 không phải task hay feature mới, mà là một family model chuyên biệt mở rộng task segmentation hiện có. Ba đóng góp cốt lõi:
- Object embedding head thay thế class logits cố định: mọi anchor point xuất ra embedding vector, phân loại trở thành phép similarity-match với prompt embeddings trong không gian ngữ nghĩa chung.
- Tri-modal prompting trong cùng một network: text (natural language), visual (bounding box/mask tham chiếu), prompt-free (tự khám phá từ vocabulary 4,585 lớp RAM++).
- Zero-overhead: ba module (RepRTA, SAVPE, LRPC) được re-parameterize vào head chính sau training — không thêm chi phí inference nào so với YOLO26 gốc.
Paper kỹ thuật do Ranjan Sapkota & Manoj Karkee (Cornell) nộp arXiv ngày 29/01/2026, 9 ngày sau khi YOLO26 launch.
Vì sao quan trọng
Trước YOLOE-26, developer phải chọn một trong hai:
- YOLO classic (v8, 11, 26) — nhanh, chạy edge tốt, nhưng closed-set: muốn phát hiện class mới phải thu data + retrain.
- Open-vocabulary model (GLIP, Grounding DINO, OWL-ViT, YOLO-World) — linh hoạt với text prompt, nhưng transformer-heavy: chậm, tốn memory, khó deploy lên Jetson hay CPU.
YOLOE-26 phá thế lưỡng nan đó. Cùng một model, cùng 6.2 ms latency, bạn có thể prompt "crack on pipe", "damaged crop leaf", "unfamiliar drone" — và segment ngay không retrain. Đây là lý do team nghiên cứu gọi thiết kế này là "no free lunch trade-off".
Thông số kỹ thuật
Năm kích thước (N/S/M/L/X), mỗi kích thước có hai biến thể: chuẩn (text/visual prompt) và -pf (prompt-free). Benchmark trên LVIS minival, ảnh 640×640, end-to-end metrics:
| Variant | Params | FLOPs | mAP50–95 (text) | mAP50–95 (visual) |
|---|---|---|---|---|
| YOLOE-26n-seg | 4.8M | 6.0B | 23.7 | 20.9 |
| YOLOE-26s-seg | 13.1M | 21.7B | 29.9 | 27.1 |
| YOLOE-26m-seg | 27.9M | 70.1B | 35.4 | 31.3 |
| YOLOE-26l-seg | 32.3M | 88.3B | 36.8 | 33.7 |
| YOLOE-26x-seg | 69.9M | 196.7B | 39.5 | 36.2 |
YOLOE-26L xử lý ảnh 640×640 ở 6.2 ms (161 FPS) trên NVIDIA T4 GPU. Training dùng Objects365v1 (9.6M box), GQA (3.68M box) và Flickr30k (641K box). Prompt-free mode dựa vào vocabulary 4,585 lớp lấy từ tag set RAM++.
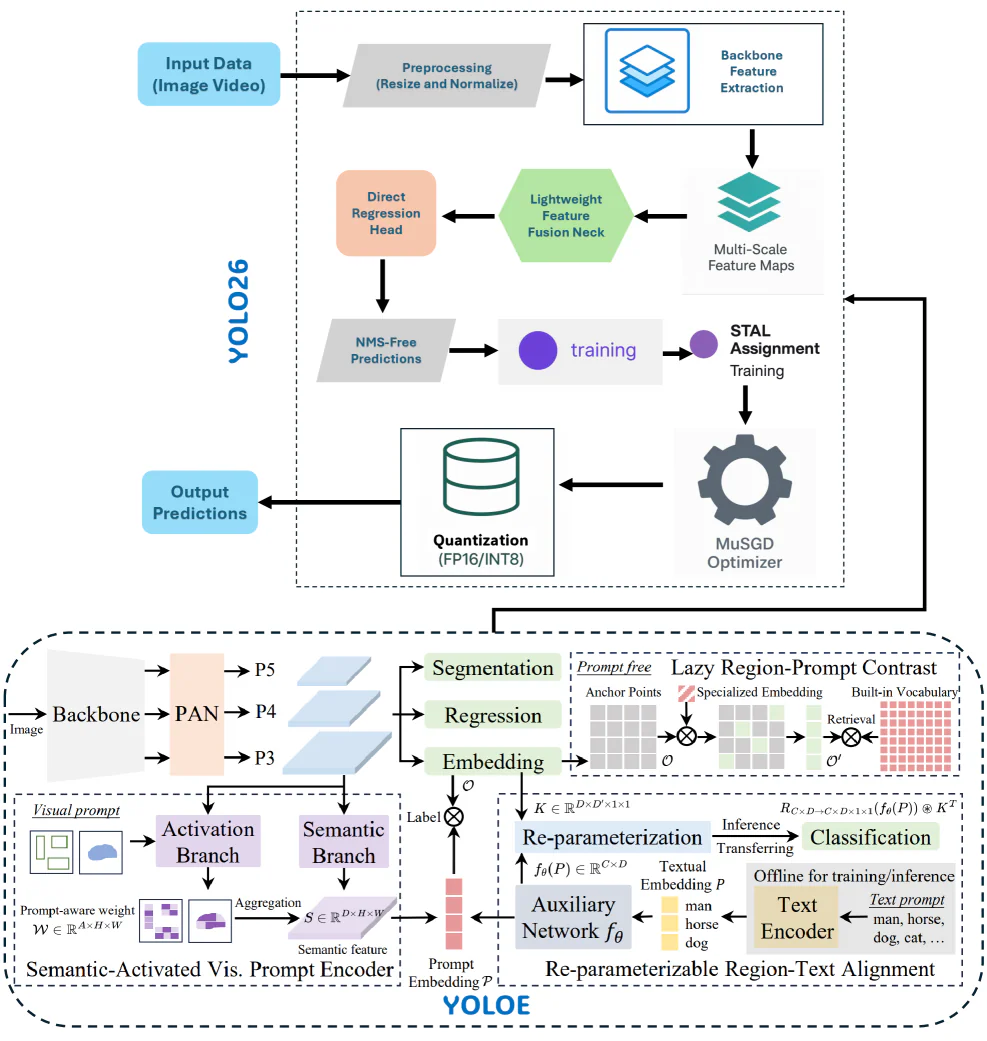
Ba module cốt lõi
- RepRTA (Re-Parameterizable Region-Text Alignment) — refine CLIP text embeddings bằng một auxiliary network lúc train; khi inference, network này được fold thẳng vào embedding head → chi phí zero.
- SAVPE (Semantic-Activated Visual Prompt Encoder) — hai nhánh nhẹ (semantic + activation), cho phép one-shot detection từ một box tham chiếu duy nhất, không transformer.
- LRPC (Lazy Region-Prompt Contrast) — ở chế độ prompt-free, một objectness embedding lọc anchor trước, rồi mới match phần filtered với vocabulary 4,585 lớp → cắt mạnh chi phí so với dense matching.
So sánh trực tiếp
| Model | LVIS mAP | Params | Latency T4 | Open-vocab? |
|---|---|---|---|---|
| YOLO11-L | — | 26.2M | 6.2 ms | Không |
| YOLOE-L (YOLO11) | 35.2% | 26.2M | 6.2 ms | Có |
| YOLOE26-L | 36.8% | 32.3M | 6.2 ms | Có, NMS-free |
| YOLO-World-L | 26.8% (*) | >50M | Chậm hơn | Có |
Cụ thể hơn: YOLOE26-S vượt YOLO-World-S +11.4 AP, YOLOE26-L vượt YOLO-World-L +10.0 AP trên LVIS. So với YOLO-Worldv2, YOLOE đạt +3.5 AP, nhanh hơn 1.4× và chỉ cần 1/3 chi phí training. Còn các model transformer-based như GLIP, Grounding DINO, OWL-ViT? Team nghiên cứu mô tả thẳng: "orders-of-magnitude faster inference" — tức nhanh hơn cả bậc độ lớn.
Use case thực tế
- Robotics & autonomous — robot gặp object lạ trong kho, chỉ cần thêm text prompt là nhận dạng ngay, không cần data collection + retrain pipeline.
- Precision agriculture — phát hiện crop anomaly, sâu bệnh hiếm qua mô tả ngôn ngữ thay vì bộ label cố định.
- Industrial inspection — một ảnh tham chiếu defect duy nhất (visual prompt) là đủ để line sản xuất detect lỗi trong ngày.
- Smart city / surveillance — camera adapt với threat mới (vật cấm, phương tiện lạ) bằng prompt, không retrain trọn hệ.
- Medical imaging — segment cấu trúc giải phẫu bất kỳ theo mô tả, không cần model chuyên dụng mỗi bệnh lý.
- Auto-labeling — sinh bounding box + instance mask cho dataset khổng lồ, cắt giờ annotation thủ công.

Giới hạn & pricing
- Prompt-free luôn thấp hơn prompted — ví dụ YOLOE-26x-seg-pf chỉ 29.9 mAP50–95 so với 39.5 khi có text prompt. Unconstrained open-world vẫn là bài toán khó.
- Training dùng pseudo-mask (sinh bằng SAM) → boundary không sắc với cấu trúc mảnh, object bị occlude, hoặc class fine-grained.
- Sensitivity với prompt phrasing: "red car" vs "crimson automobile" có thể ra kết quả khác — long-tail semantics và dataset bias còn là vấn đề mở.
- Quantization INT8/FP8 và confidence calibration cho safety-critical (autonomous driving, medical) còn trong roadmap.
- License: AGPL-3.0 (open-source, copyleft) + Enterprise License (Ultralytics) cho ai không thể tuân thủ AGPL. Weight miễn phí qua Hugging Face.
Sắp tới
Roadmap YOLOE-26 công bố trong paper tập trung ba hướng:
- Edge-efficient open-vocab seg — quantization-aware training (INT8/FP8), prompt caching, ANN vocabulary indexing, distill xuống N/S, temporal mask propagation cho streaming video.
- Robust prompting — xử lý synonym/paraphrase, uncertainty thresholding, long-tail calibration, domain shift (low-light, blur, weather).
- Agentic perception — perception agent tự discover → refine prompt, active vision (reframe, zoom), prompt memory cache, continual learning không quên class cũ.
Muốn thử luôn? pip install ultralytics, load yoloe-26l-seg.pt, truyền set_classes(["your", "classes"]) và predict. Documentation tại docs.ultralytics.com/models/yoloe.
Nguồn: arXiv 2602.00168, Ultralytics Docs, Ultralytics Blog, Roboflow.



