
- Tencent vừa công bố trọn bộ code, dataset 1.4M ảnh và hai pretrained model cho MegaStyle — hệ thống style transfer dựa trên FLUX vượt 7 baseline SOTA, đưa style transfer đến cột mốc quy mô giống ImageNet ngày xưa.
TL;DR
Ngày 2026-04-21, nhóm tác giả tại AIPD, Tencent (dẫn đầu bởi Junyao Gao) công bố trọn bộ code, dataset và model của MegaStyle — và gọi đây là "khoảnh khắc ImageNet cho style transfer". Gồm 1,389,424 ảnh trải trên 8,355 phong cách nghệ thuật, kèm encoder đạt mAP@1 88.46 (baseline CLIP chỉ 9.29) và một model FLUX vượt bảy phương pháp SOTA. Tất cả mở nguồn trên GitHub, HuggingFace dataset và HuggingFace models.

Có gì mới
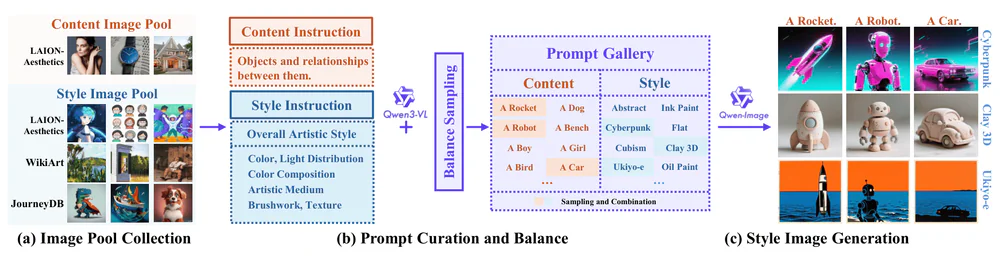
Style transfer lâu nay thiếu một dataset đủ lớn và đủ sạch để train encoder học được phong cách thuần tuý tách khỏi nội dung. Các dataset cũ như JourneyDB hay OmniStyle-150K đều quá nhỏ hoặc trộn lẫn content–style. MegaStyle giải quyết bằng một pipeline curate hoàn toàn mới:
- 170K style prompt × 400K content prompt → tối đa 68B tổ hợp khả thi.
- Sinh ảnh bằng T2I nhất quán (ví dụ Qwen-Image) để cùng style prompt tạo ra nhiều content khác nhau nhưng giữ style đồng nhất — đây là chìa khoá cho intra-style consistency.
- Kết quả: MegaStyle-1.4M — 1.4 triệu ảnh 512×512, 45 GB, parquet, hơn 8,355 phong cách riêng biệt từ film noir, cyberpunk, impressionism đến paper art.
- Hai model đi kèm: MegaStyle-Encoder (ViT-L & SoViT variants, train bằng style-supervised contrastive learning) và MegaStyle-FLUX (style transfer trên nền FLUX.1-dev).
Vì sao đáng chú ý
Cái tên "ImageNet moment" không phải cường điệu: trước ImageNet 2012, mọi model vision đều loay hoay với dataset vài chục nghìn ảnh. Style transfer cũng đang ở đúng trạng thái đó — thiếu dữ liệu quy mô lớn khiến các encoder không học được biểu diễn phong cách tốt. Bằng chứng rõ nhất nằm trong ablation: cùng một kiến trúc model, chỉ swap dataset, style score nhảy từ 34.56 (JourneyDB) lên 76.16 (MegaStyle-1.4M) — tức +120% thuần do dữ liệu. Đây là tín hiệu data > model mạnh đến mức khó bỏ qua.
Thêm nữa, OmniStyle-150K — dataset gần nhất cùng hướng — chỉ bằng khoảng 1/10 quy mô MegaStyle-1.4M và thiếu intra-style consistency ở mức prompt. Với MegaStyle, mỗi style prompt sinh ra nhiều nội dung giữ nguyên phong cách, encoder học được "style embedding" rõ ràng hơn, không bị content làm nhiễu. Đây là lý do trực tiếp cho việc MegaStyle-Encoder đạt mAP@1 88.46 trong khi CSD — baseline chuyên biệt cho style — chỉ ở 45.60.
Số liệu kỹ thuật
StyleRetrieval benchmark — chất lượng encoder (mAP@1 càng cao càng tốt):
| Model | mAP@1 |
|---|---|
| CLIP baseline | 9.29 |
| CSD baseline | 45.60 |
| MegaStyle-Encoder (ViT-L) | 87.26 |
| MegaStyle-Encoder (SoViT) | 88.46 |
Cross-dataset: StyleBench 85.00, OmniStyle-150K 78.89, FLUX-Retrieval 22.70 — cho thấy encoder generalise tốt ngoài domain train.
Stack dependency để chạy: Python 3.10, conda, diffsynth==1.1.8, SigLIP (google/siglip-so400m-patch14-384) và weights FLUX.1-dev. Inference thực tế cần GPU ≥24 GB VRAM.
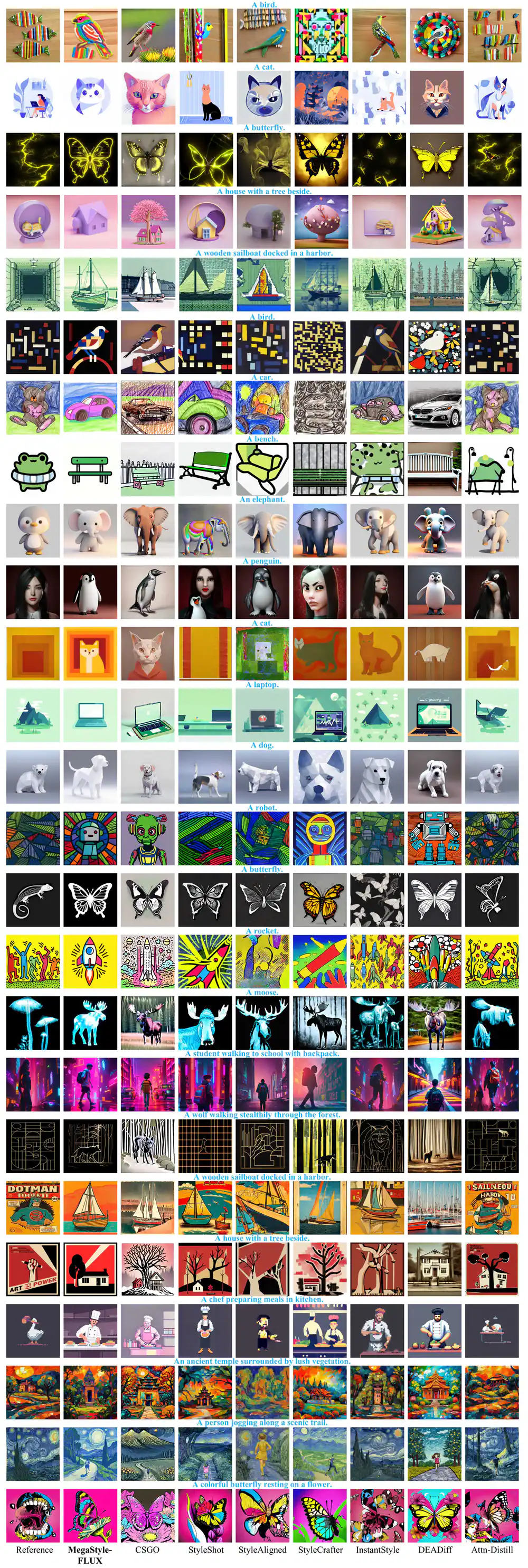
So sánh với SOTA
MegaStyle-FLUX được chấm điểm cùng 7 phương pháp SOTA (DEADiff, StyleShot, Attention-Distillation, CSGO, StyleCrafter, InstantStyle, StyleAligned):
| Model | Style score | Text score | Human style pref | Human text pref |
|---|---|---|---|---|
| MegaStyle-FLUX | 76.16 | 23.20 | 31.37% | 28.72% |
| StyleShot | — | — | 15.21% | — |
| InstantStyle | 85.59 | — | — | 6.31% |
Lưu ý: InstantStyle có style score tự động cao hơn nhưng human preference text chỉ 6.31% — nghĩa là nó bẻ nội dung prompt quá nhiều để "ép" style. MegaStyle-FLUX cân bằng cả hai, và được đánh giá cao nhất ở cả hai tiêu chí human preference.
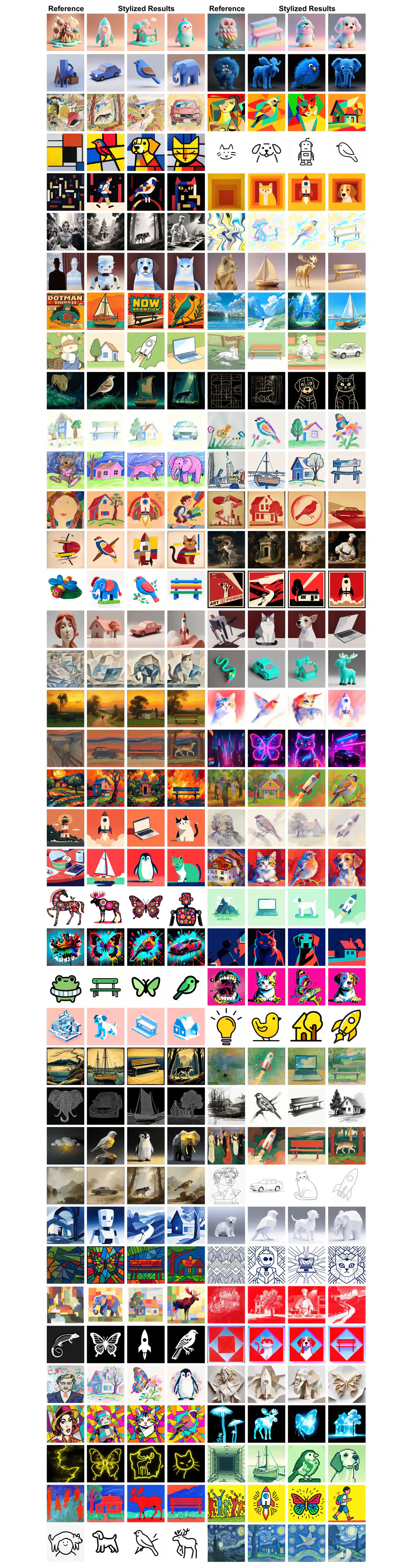
Use cases
- Research baseline: dataset mở quy mô lớn đầu tiên cho style transfer — giờ mọi paper mới có reference để benchmark fair.
- Fine-tune model riêng: team sản phẩm có thể fine-tune MegaStyle-FLUX cho bộ style brand-specific.
- Style retrieval / similarity search: dùng encoder để tìm kiếm ảnh theo phong cách trong kho asset lớn.
- Design tooling: storyboard, mood board, brand-consistent illustration, generative ad creative.
- Downstream: conditioning cho video/3D model, style-aware image editing.
Limitations & pricing
- Miễn phí — code MIT-ish (custom license, đọc
LICENSE.txttrước khi dùng thương mại). - FLUX.1-dev là non-commercial — MegaStyle-FLUX kế thừa ràng buộc này, production thương mại cần license riêng từ Black Forest Labs.
- Dataset 45 GB, English-only prompts.
- Tác giả thừa nhận VLM khi mô tả style đôi khi dùng "vague words" cho texture/brushwork/medium — còn không gian cải thiện độ chi tiết của style prompt.
- Inference cần GPU ≥24 GB VRAM; training đa GPU.
What's next
Với code + dataset + weights cùng lúc lên public, cộng đồng chắc chắn sẽ nhanh chóng đóng góp Diffusers integration, ComfyUI nodes, và các fine-tune theo domain (anime, architecture, UI mockup...). Dataset 1.4M cũng đủ lớn để phục vụ nghiên cứu encoder phong cách cho video và 3D.
Bản thân pipeline curate cũng có thể tái sử dụng ngoài style transfer: cùng tư tưởng "prompt gallery balanced + consistent T2I sampling" có thể áp dụng cho dataset composition, lighting, camera angle hay character consistency — những bài toán generative AI đều đang thiếu dữ liệu dán nhãn quy mô lớn. Nếu "ImageNet moment" của tác giả thực sự xảy ra, bước kế tiếp sẽ là các benchmark tiêu chuẩn hoá, leaderboard công khai, và một thế hệ style-transfer model mới coi MegaStyle-1.4M làm pretraining baseline mặc định — giống cách ImageNet trở thành viên gạch nền cho thập kỷ computer vision tiếp theo.
Nguồn: arXiv 2604.08364, project page, Tencent/MegaStyle.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ