
- Kimodo là motion diffusion model open-source của NVIDIA Research, huấn luyện trên 700 giờ mocap chuyên nghiệp, sinh chuyển động 3D cho người và robot Unitree G1 từ prompt text + kinematic constraints trong 2–5 giây trên một GPU.
TL;DR
NVIDIA Research vừa công bố Kimodo (Kinematic Motion Diffusion) — mô hình diffusion 282M tham số sinh chuyển động 3D cho người và robot hình người từ prompt text. Huấn luyện trên 700 giờ optical mocap chuyên nghiệp (bộ Bones Rigplay 1, lớn gấp ~25× HumanML3D), Kimodo tạo motion sequence tối đa 10 giây trong 2–5 giây trên RTX 3090. Hỗ trợ nguyên bản khung xương SOMA, SMPL-X và robot Unitree G1; output đẩy thẳng vào MuJoCo hoặc retarget sang robot khác qua GMR. Code Apache-2.0, checkpoint SOMA/G1 phát hành theo NVIDIA Open Model License (dùng thương mại được). Cần ~17GB VRAM.

What's new
Released lần đầu ngày 16/03/2026 kèm paper arXiv 2603.15546, Kimodo tiếp tục có breaking change ngày 19/03 chuyển sang SOMA skeleton 77-joint, rồi đến 10/04/2026 ra mắt v1.1 cho SOMA cùng Motion Generation Benchmark chính thức. Gói repo nv-tlabs/kimodo gồm: inference CLI, web demo tương tác có timeline editor (chạy local trên 127.0.0.1:7860), bộ text annotation fine-grained cho BONES-SEED, và pipeline evaluation với embedding model TMR-SOMA-RP-v1 để tính R-precision, FID.
Năm biến thể v1 gốc trải trên ba skeleton: Kimodo-SOMA-RP và Kimodo-SOMA-SEED cho nhân vật digital (30 joint, nay 77 joint), Kimodo-G1-RP và Kimodo-G1-SEED cho Unitree G1 (34 joint), và Kimodo-SMPLX-RP (22 joint) cho tương thích AMASS.
Vì sao đáng chú ý
Cuộc đua humanoid robot (Figure, 1X, Agility, Boston Dynamics, Unitree) đang chuyển bottleneck từ compute sang dữ liệu chuyển động. Trước Kimodo, muốn sinh demo motion cho một robot cụ thể bạn có ba lựa chọn đều đau: teleop thủ công (chậm, chuyển động gượng), mocap studio (đắt, lắp dựng phức tạp), hoặc reconstruct từ video đơn (chất lượng thấp). Kimodo biến vòng lặp đó thành một prompt text và 2–5 giây inference — với output là chuỗi joint-angle mà chân tay, tầm với của G1 thật sự thực thi được.
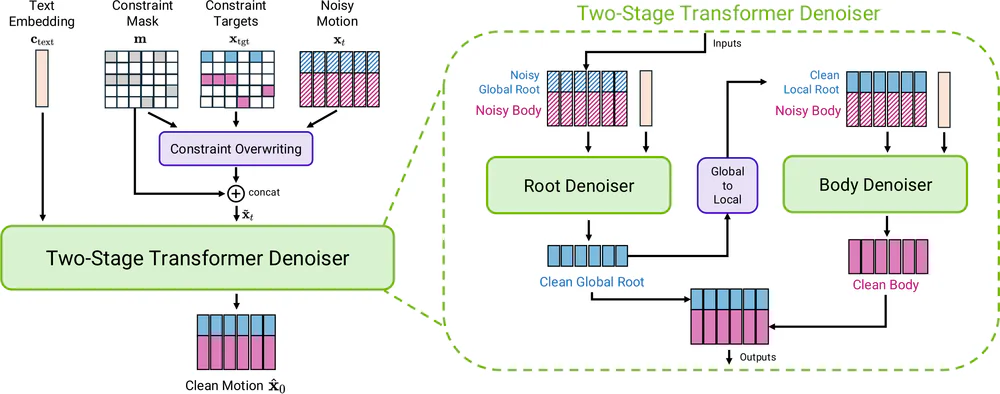
Điểm khác biệt cốt lõi so với các text-to-motion trước (MDM, MotionDiffuse, MoMask, MotionGPT): Kimodo hoạt động trực tiếp trong explicit pose space, cho phép áp kinematic constraints ngay trong mỗi bước denoising thay vì phải tối ưu ở test time hoặc fine-tune ControlNet.
Tech facts
| Thuộc tính | Giá trị |
|---|---|
| Tham số (model L) | 282M |
| Kiến trúc | Two-stage transformer denoiser (16 layer × 8 head × latent 1024) |
| Text encoder | LLM2Vec 4096-d (tốt hơn CLIP & T5 trong ablation) |
| Diffusion steps | 1000 train / 100 DDIM inference |
| Dữ liệu train | Bones Rigplay 1 (700h, đóng) + BONES-SEED (288h, mở) = ~1,000h |
| Inference | 2–5 giây trên RTX 3090 |
| Độ dài clip tối đa | 10 giây (300 frame @ 30 fps) |
| VRAM tối thiểu | ~17GB (chủ yếu cho text encoder) |
| Skeleton hỗ trợ | SOMA (77-joint), Unitree G1 (34-joint), SMPL-X (22-joint) |
| Output formats | NPZ native, MuJoCo qpos CSV, AMASS NPZ |
Về benchmark chất lượng trên test set Rigplay: model L đạt R@3 = 71.9 (ground-truth 75.6), FID = 1.85, foot-skate 3.87 cm/s. Về constraint following: sai số vị trí toàn thân 2.67 cm, end-effector 3.09 cm, rotation 4.18°, 2D root 2.90 cm — đủ chính xác để ghép vào animation pipeline.
Ba cách điều khiển
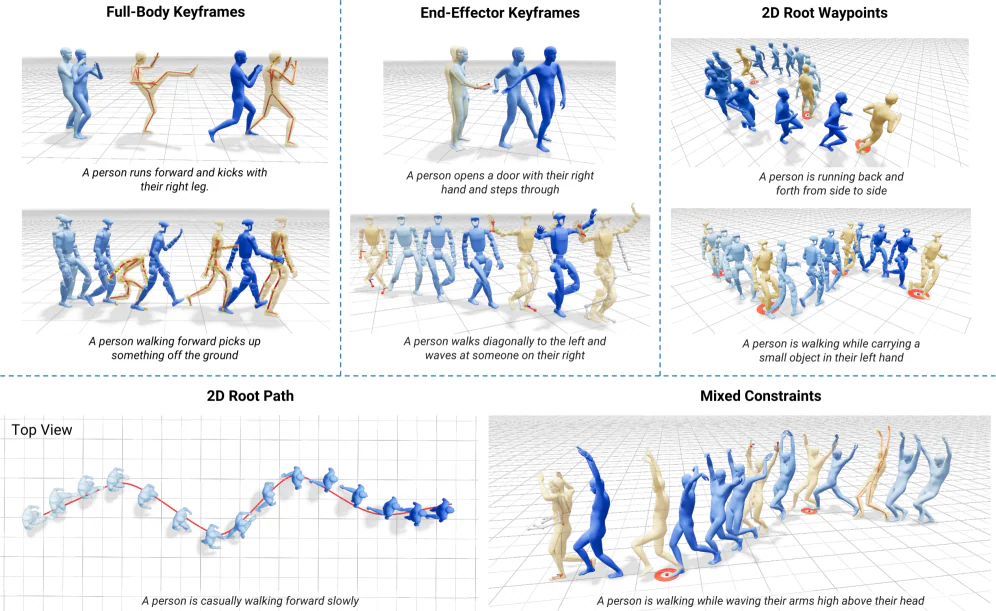
Kimodo nhận đồng thời text prompt và các kinematic constraint. Có bốn trục control:
- Full-body keyframes — cắm pose tại frame cụ thể (ví dụ start và end của một transition), Kimodo tự sinh phần giữa.
- End-effector positions/rotations — ghim tay/chân vào vị trí 3D (cho tương tác object) hoặc góc xoay cụ thể.
- 2D waypoints & dense paths — vẽ đường đi trên mặt đất, nhân vật đi theo với pelvis motion tự nhiên.
- Multi-prompt timeline — chuỗi nhiều prompt nối tiếp, model tự xử lý transition bằng ràng buộc liên đoạn.
So với các model trước
| Model | Data | Control mode | Robot support |
|---|---|---|---|
| MDM / MotionDiffuse | ~30h (HumanML3D) | Text only | Không |
| MoMask / MMM | ~30h | Text + latent, cần test-time opt cho constraint | Không |
| MotionGPT | ~30h | Autoregressive token, constraint yếu | Không |
| OmniControl | ~30h | ControlNet fine-tune cho constraint | Không |
| Kimodo | ~1,000h | Explicit pose space, native constraint imputation | Unitree G1 gốc |
Use cases
- Robotics — sinh demo nhanh cho humanoid: phục hồi từ vấp, cầm nắm, bàn giao vật thể. Randomize constraint để tạo dataset đa dạng ở quy mô lớn.
- Digital twin & sim công nghiệp — populate warehouse, factory bằng người số vận động thực tế.
- Animation & game — in-betweening giữa các clip mocap có sẵn, route nhân vật qua navmesh bằng 2D path.
- Research — baseline mạnh cho text-conditioned motion control.
Workflow chuẩn cho robot: Kimodo sinh kinematic sequence → xuất MuJoCo CSV hoặc AMASS NPZ → ProtoMotions (NVIDIA framework RL vật lý) biến thành control policy thực thi được → GEAR-SONIC deploy lên robot thật. Với robot ngoài G1, dùng Kimodo-SMPLX rồi retarget bằng GMR (General Motion Retargeting).
Hạn chế & pricing
Kimodo là motion choreographer, không phải robot controller. Điều đó đi kèm bốn hạn chế cần ghi nhớ:
- Không có physics — output chỉ là quỹ đạo joint, không tính lực/torque. Muốn deploy phải qua ProtoMotions để sinh policy.
- Trần 10 giây — một lần sinh tối đa 10 giây. Tác vụ dài kiểu "đi tới workstation, nhấc linh kiện, mang sang dây chuyền, đặt xuống" (30s+) phải nối nhiều segment trên timeline.
- Không real-time — 2–5s inference là offline authoring, không phản ứng với obstacle bất ngờ giữa chừng.
- Rào cản hardware — 17GB VRAM đẩy yêu cầu lên RTX 3090/4090 hoặc A100.
Code miễn phí (Apache-2.0). Checkpoint SOMA và G1 theo NVIDIA Open Model License — commercial use OK. SMPL-X (Rigplay) chỉ R&D. Có HuggingFace Space miễn phí để thử ngay trên browser. Lưu ý quan trọng về dữ liệu: Bones Rigplay 1 (700h, phần "engine" của chất lượng Kimodo) là proprietary, không public — BONES-SEED 288h mới là phần mở. Model train riêng trên SEED có mặt trong repo để so sánh fair, nhưng chất lượng kém hơn đáng kể so với phiên bản Rigplay.
What's next
Ba hướng roadmap theo section "Future Challenges" của paper:
- Scale với video data — kết hợp motion reconstruct từ internet/synthetic video với mocap clean mà không tụt chất lượng.
- Real-time reactive control — đưa diffusion sang latent space học được, reformulate sinh motion thành autoregressive để dùng runtime cho robot và digital twin.
- Scene & object interaction — hiện tại model zero-awareness với object xung quanh. Thu thập data cho bài này là bài toán mở.
Cùng hệ sinh thái: SOMA body model, BONES-SEED dataset, GEM (video→3D motion), GEAR-SONIC/GR00T-WholeBodyControl.
Nguồn: NVIDIA Research, nv-tlabs/kimodo, arXiv 2603.15546, Hugging Face.


