
- NVIDIA Toronto AI Lab just dropped the code and 7B weights for UniRelight — a DiT video diffusion model that jointly predicts a relit video and its albedo from a single environment map.
- In user studies it beats DiffusionRenderer 96% and NeuralGaffer 84%.
TL;DR
NVIDIA's Toronto AI Lab has open-sourced UniRelight — the code lives at nv-tlabs/UniRelight and the 7B weights are on Hugging Face. Feed it a video plus a target environment map; it returns a relit video and the scene's albedo in a single joint denoising pass. The paper is a NeurIPS 2025 poster, and in blind user studies UniRelight was preferred 96% of the time over DiffusionRenderer-Cosmos and 84% over NeuralGaffer.
What's new
Video relighting has historically been a pipeline problem: first decompose the scene into intrinsics (albedo, normals, materials), then re-render under a new light. Every stage leaks errors downstream — baked-in shadows, flickering, or lost reflections on glass and metal.
UniRelight collapses that pipeline into one generative model. Its key insight: relighting and albedo estimation are mutually informative. Predicting them jointly gives the relit branch a clean demodulation prior, which reduces shadow-baking artifacts and improves generalization to materials the old pipelines choked on.
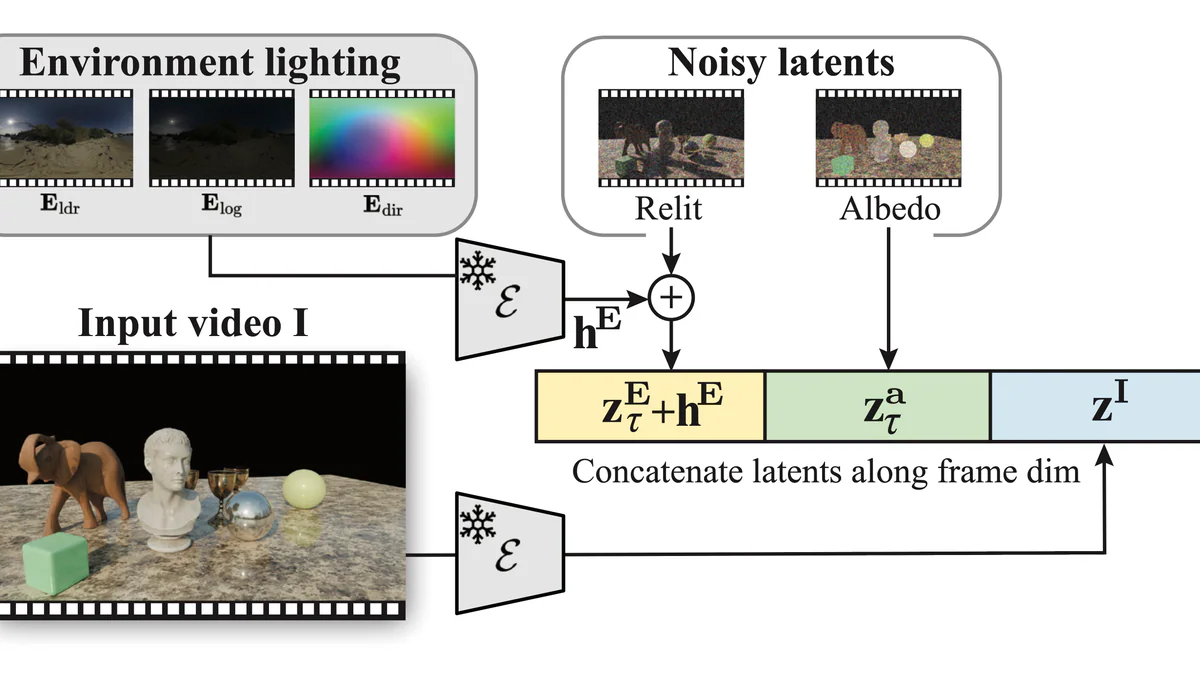
How it works
Under the hood it is a fine-tuned Diffusion Transformer (DiT) built on Cosmos-Predict1-7B-Video2World. The flow:
- Encode the input video with a frozen VAE to latent
z^I. - Encode the target environment map (LDR + log + directional channels) into a lighting embedding
h^E. - Concatenate the noisy relit latent
z^E, noisy albedo latentz^a, and input latentz^Ialong the token/frame dimension. - Denoise the whole block with a single DiT forward — self-attention lets the albedo and relit tracks share scene geometry every step.
- Decode each branch back to a 480×848 RGB video.
The training mix is synthetic multi-illumination renders plus a large stock of auto-labeled real-world videos, which is why the model holds up on in-the-wild footage rather than just controlled studio captures.
The token-level concatenation trick is the core contribution. Instead of training a separate decomposition network and a separate re-render network, UniRelight lets a single self-attention stack look at all three latents at every denoising step. That means when the relit branch has to decide how a specular highlight should move, it can directly peek at what the albedo branch thinks the underlying material is — and vice versa. Errors that would have compounded across a two-stage pipeline get absorbed inside the transformer.
Technical facts
| Property | Value |
|---|---|
| Base model | Cosmos-Predict1-7B-Video2World (DiT) |
| Parameters | ~7B |
| Input / output resolution | 480 × 848 RGB video |
| Tensor shape | [B, T, H, W, 3] |
| Inference hardware | NVIDIA A100+ (Ampere minimum), TensorRT, Linux |
| Metrics | PSNR, SSIM, LPIPS + user study |
| License | NVIDIA Source Code License (non-commercial) |
Comparison
The paper benchmarks UniRelight against the strongest public relighting baselines. UniRelight wins on PSNR / SSIM / LPIPS across the board, but the more telling numbers are from the blind user study where humans pick the output closest to ground truth:
| Baseline | UniRelight preferred |
|---|---|
| DiffusionRenderer-Cosmos | 96% |
| NeuralGaffer | 84% |
| DiLightNet | Strong win (qualitative) |
The gap is widest on anisotropic, glass, and transparent materials — exactly the cases where older methods bake shadows into albedo or lose specular highlights.
Use cases
- Autonomous-driving data augmentation. Turn daytime driving footage into dusk or night variants to diversify perception-stack training data — the paper demonstrates this explicitly.
- VFX and virtual production. Relight an actor plate to match a new background without re-shooting.
- Intrinsic decomposition research. Use the albedo branch as a strong starting point for downstream vision tasks.
- Ad and content post-production prototyping. Test mood/time-of-day variants before committing to a full render.
- Robotics and sim-to-real. Augment manipulation footage with new lighting to close the appearance gap between simulation and deployment.
- 3D reconstruction pipelines. Decoupled albedo is a cleaner signal than RGB for methods that need material estimates upstream of geometry.
Limitations & pricing
- Non-commercial only under the NVIDIA Source Code License. Shipping it in a product needs separate licensing.
- Fixed 480×848 resolution — no native HD/4K.
- Heavy: 7B DiT at video rates wants an A100 or better.
- No built-in PII/face redaction — deployment safety is on you.
- Free for research and benchmarking.
What's next
Expect rapid community follow-ons: ComfyUI nodes have already started appearing, and the obvious roadmap items are higher resolutions, a commercial license path, and tighter integration with NVIDIA's Cosmos video-foundation stack. If you work on video generation, relighting is the next frontier after text-to-video — and UniRelight just handed everyone a state-of-the-art baseline.
Nguồn: NVIDIA Toronto AI Lab, arXiv 2506.15673, Hugging Face model card, GitHub repo.


