
- Anthropic ra Claude Opus 4.7 ngày 16/04/2026.
- Cùng giá với 4.6 nhưng thắng 12/14 benchmark, SWE-bench Verified nhảy từ 80.8% lên 87.6%, vision tăng 3× độ phân giải.
- Tokenizer mới có thể làm hoá đơn API tăng tới 35%.
- Khi nào nên upgrade, khi nào nên ở lại 4.6.
TL;DR
Claude Opus 4.7 ra mắt 16/04/2026, hai tháng sau Opus 4.6. Cùng mức giá $5 / $25 per 1M tokens, nhưng thắng 12 trên 14 benchmark công bố, đặc biệt bứt phá ở coding, tool use và vision. Đổi lại: một regression rõ ở web research (BrowseComp -4.7 điểm) và tokenizer mới có thể làm hoá đơn tăng 0–35% trên cùng prompt. Đây không phải một model thông minh hơn — đây là một model biết build.

Có gì mới
- xhigh effort level — tầng reasoning mới nằm giữa
highvàmax, giúp cân bằng chất lượng và latency tốt hơn. Claude Code đã nâng default lênxhighcho mọi plan. - Self-verification loop — model tự plan → execute → verify → report, tự viết test và sanity check trước khi báo xong. Vercel phản hồi 4.7 "làm proof trên system code trước khi bắt đầu" — behavior chưa từng có ở 4.6.
- Literal instruction following — theo nghĩa đen hơn. Prompt cũ viết dạng "gợi ý" có thể bị model hiểu thành yêu cầu cứng. Cần audit system prompt trước khi rollout.
- Vision 3.3× độ phân giải — chấp nhận ảnh tới 2,576 px cạnh dài (~3.75 MP), gấp 3 lần các Claude cũ.
- File-system memory cải thiện cho agentic workflow chạy nhiều session.
Vì sao quan trọng
Các con số coding không chỉ là màu sắc đẹp trên biểu đồ. Chúng map thẳng vào những workflow production thường xuyên gãy ở 4.6: refactor multi-language, long-running agent tasks, và computer-use agent phải đọc UI dày đặc. Notion report 4.7 giảm ⅓ lỗi tool call, "keep executing through tool failures that used to stop Opus cold". Rakuten đo được gấp 3× số task production hoàn thành.
Con số kỹ thuật
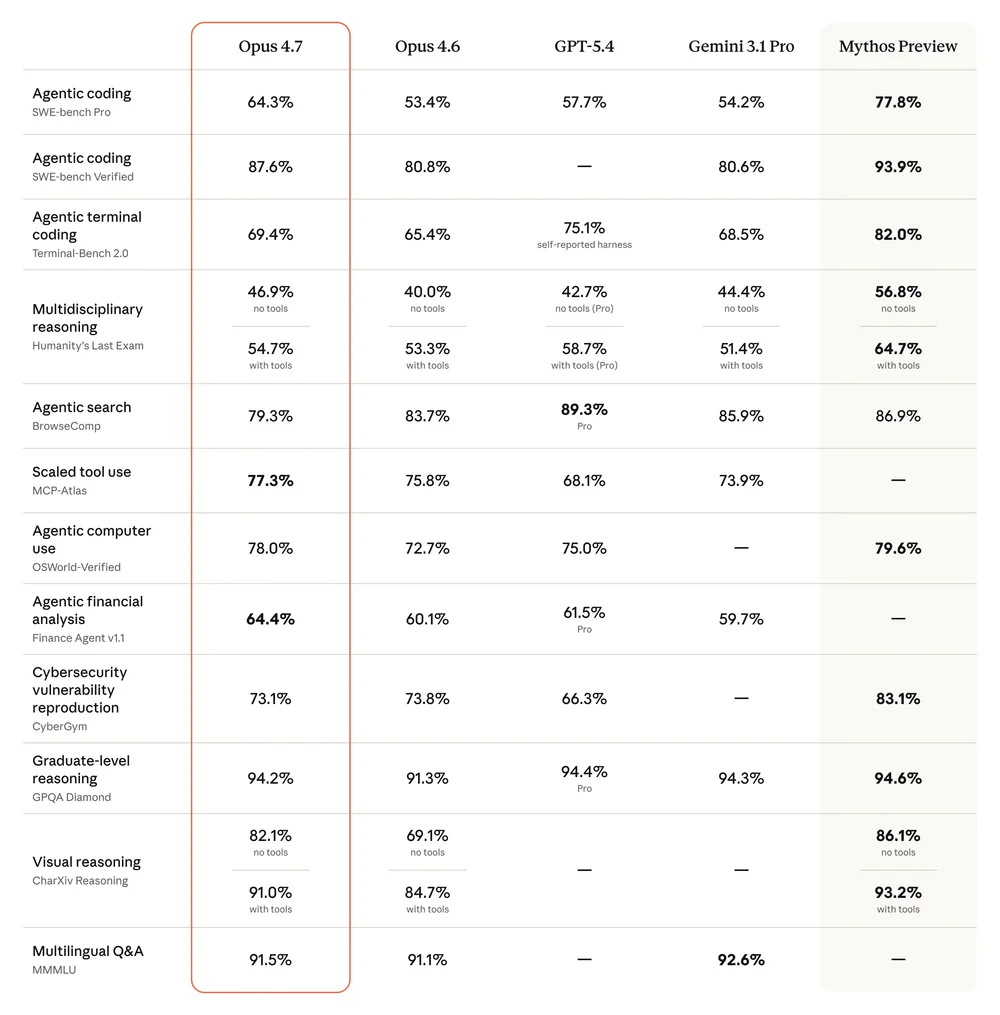
- SWE-bench Verified: 80.8% → 87.6% (+6.8)
- SWE-bench Pro: 53.4% → 64.3% (+10.9) — lead cả GPT-5.4 (57.7%) và Gemini 3.1 Pro (54.2%)
- CursorBench: 58% → 70% (Cursor báo cáo)
- MCP-Atlas (tool use): 75.8% → 77.3% — best-in-class
- CharXiv Reasoning vision (no tools): 68.7% → 82.1% (+13.4)
- XBOW partner visual acuity (autonomous pen-testing): 54.5% → 98.5%
- GPQA Diamond: 91.3% → 94.2%
- Finance Agent v1.1: 60.1% → 64.4% (best-in-class)
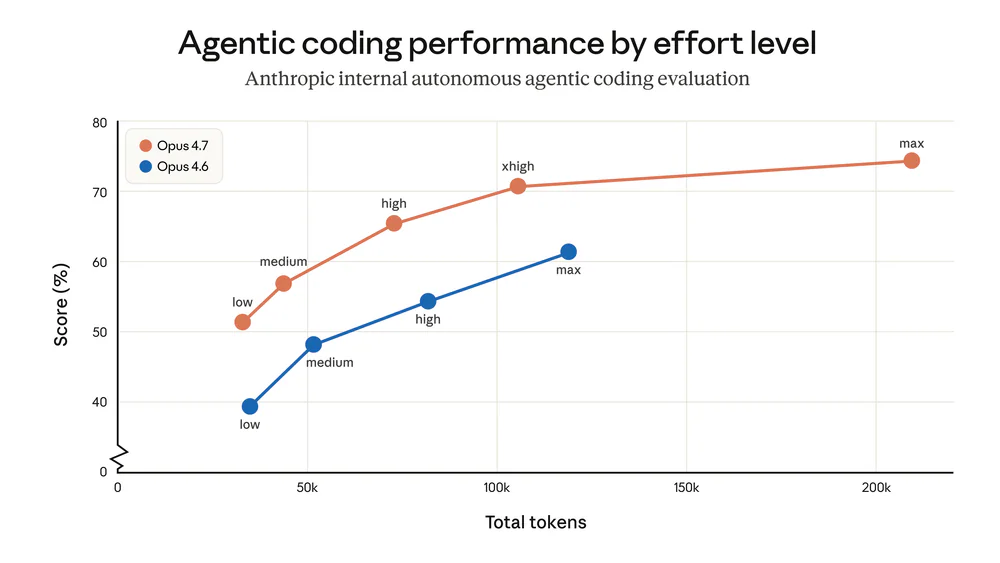
Một chi tiết quan trọng về cost-per-task: Hex test thấy low-effort 4.7 match medium-effort 4.6 về chất lượng. Nghĩa là cùng một task, bạn có thể dùng effort thấp hơn trên 4.7 — token per completed task giảm dù giá/token không đổi.
So sánh với đối thủ
| Benchmark | Opus 4.7 | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| SWE-bench Verified | 87.6% | 80.8% | — | 80.6% |
| MCP-Atlas | 77.3% | 75.8% | 68.1% | 73.9% |
| Finance Agent v1.1 | 64.4% | 60.1% | 61.5% | 59.7% |
| BrowseComp | 79.3% | 83.7% | 89.3% | 85.9% |
| MMMLU | 91.5% | 91.1% | — | 92.6% |
Opus 4.7 dominate coding và tool orchestration. GPT-5.4 Pro vẫn dẫn ở web research (BrowseComp 89.3%) và Humanity's Last Exam với tools. Gemini 3.1 Pro nhỉnh hơn một chút ở multilingual. Mythos Preview (giới hạn) vẫn là model mạnh nhất Anthropic có.
Use cases thực tế
- Coding agents production: Replit báo chất lượng đầu ra tương đương với chi phí thấp hơn; Rakuten resolved 3× nhiều task hơn.
- Single-shot full-stack generation: 4.7 build xong personal finance dashboard React + Express.js với dark-mode UI, biểu đồ, transaction list, budget tracker trong dưới 20 phút từ một prompt. 4.6 cần SQLite và dùng React version cũ. Gemini 3.1 Pro và GPT-5.4 đều không hoàn thành trong một lần.
- Multi-tool orchestration: Notion Agent pass implicit-need test lần đầu tiên; chạy tiếp xuyên qua tool failure thay vì stop và hỏi.
- Computer-use agents: đọc UI dày đặc, screenshot độ phân giải cao mà không cần crop trước khi gửi vào API.
- Agentic penetration testing: XBOW unlock workflow không khả thi trên 4.6.
Hạn chế & pricing
Regression thật sự nằm ở web browsing, không phải long-document retrieval như một số bản tóm tắt nhầm. BrowseComp (agentic search đa bước) giảm từ 84.0% xuống 79.3% (-4.7). Nếu agent của bạn nặng research multi-page, GPT-5.4 Pro hoặc Gemini 3.1 Pro sẽ tốt hơn cho riêng workload đó.
Tokenizer mới map cùng một đoạn text thành nhiều token hơn — hệ số 1.0× đến 1.35× tuỳ loại nội dung (code, structured data và non-English bị nặng nhất). Dù giá/token giữ nguyên $5 / $25 per 1M, hoá đơn thực tế có thể tăng 0–35% trên cùng prompt. Tin tốt: 4.7 dùng effort level thấp hơn vẫn đạt chất lượng 4.6 effort cao hơn, nên token-per-task có thể giảm.
Pricing đầy đủ:
- ≤200K context:
$5 / $25 per 1M tokens - >200K context:
$10 / $37.50 per 1M tokens - Prompt caching: discount tới 90%
- Batch processing: discount 50%
- Context window: 1M input / 128K output (giữ nguyên)
Availability: Claude Pro, Max, Team, Enterprise + Claude API + Amazon Bedrock + Google Vertex AI + Microsoft Foundry. Model ID: claude-opus-4-7.
Kết luận & next
Phiên bản ngắn:
- Đang build sản phẩm, agent, coding workflow? Upgrade hôm nay. Benchmark evidence và partner feedback đồng thuận.
- Đang làm research/browsing multi-page nặng? Ở lại 4.6 hoặc test GPT-5.4 Pro cho workload đó.
- Prompt tuned kỹ cho 4.6? Re-tune trước khi switch, vì 4.7 đọc instruction theo nghĩa đen hơn.
- Token budget chặt? Test tokenizer impact trên traffic thật trước khi migrate.
Opus 4.7 là bridge model Anthropic dùng để test Project Glasswing cybersecurity safeguard trước khi rollout rộng rãi Mythos-class. Nghĩa là đây chưa phải điểm cuối — Mythos Preview (93.9% SWE Verified, 77.8% SWE Pro) đang chờ ở cuối đường hầm. Nhưng trong số các model generally available hôm nay, 4.7 là lựa chọn mạnh nhất cho coding và agentic work.