
TL;DR
Anthropic vừa phát hành Claude Opus 4.7 vào 16/04/2026, chỉ 2 tháng sau Opus 4.6. Model mới đạt 57.3 điểm trên Artificial Analysis Intelligence Index — chính thức tạo ra cú đồng hạng 3 bên đầu tiên trong lịch sử cùng GPT-5.4 (56.8) và Gemini 3.1 Pro (57.2), tất cả đều nằm trong khoảng tin cậy ±1 điểm. Điều đáng chú ý hơn: Opus 4.7 dẫn tuyệt đối trên GDPval-AA — benchmark agentic chính đo hiệu suất trên 44 nghề nghiệp và 9 ngành công nghiệp — đạt 1,753 Elo, vượt 79 điểm so với model xếp thứ hai. Tất cả điều này đạt được với ít hơn 35% output token so với Opus 4.6 và giá không đổi $5/$25 per 1M tokens.

What's new
Opus 4.7 là bản nâng cấp trực tiếp của Opus 4.6, tập trung vào advanced software engineering, agentic reasoning dài hạn, và vision chi tiết cao. Ba thay đổi API đáng chú ý:
- Mức effort mới
xhigh: nằm giữahighvàmax, cho developer kiểm soát tinh hơn trade-off giữa reasoning và latency. Range đầy đủ hiện là low, medium, high, xhigh, max. - Task budgets (public beta): advisory token budget bao trùm toàn bộ agentic loop (thinking, tool calls, tool results, output). Model nhìn thấy countdown và tự ưu tiên công việc, finish gracefully khi budget cạn.
- Extended thinking bị loại bỏ hoàn toàn: Adaptive reasoning là setting duy nhất.
Tokenizer mới map cùng input ra ~1.0–1.35× token hơn tuỳ content. Vision xử lý ảnh tới 2,576 pixel long-edge (~3.75MP), gấp 3 lần Claude trước đây — mở ra computer-use agents đọc screenshot dày đặc, data extraction từ diagram phức tạp.
Why it matters
Đây là lần đầu tiên ba lab frontier cùng chạm đỉnh Intelligence Index trong cùng một chu kỳ. Theo Artificial Analysis, khoảng cách giữa Opus 4.7 (57.3), Gemini 3.1 Pro (57.2) và GPT-5.4 (56.8) nằm trong margin of noise — điều này có nghĩa cạnh tranh không còn ở điểm benchmark tổng hợp, mà chuyển sang các năng lực chuyên biệt: Anthropic dẫn về agentic thực tế, Google về knowledge và scientific reasoning, OpenAI về long-horizon coding và scientific reasoning.
Technical facts
Bảng so sánh official từ Anthropic cho thấy Opus 4.7 dẫn tuyệt đối trên hàng loạt benchmark agentic và coding:
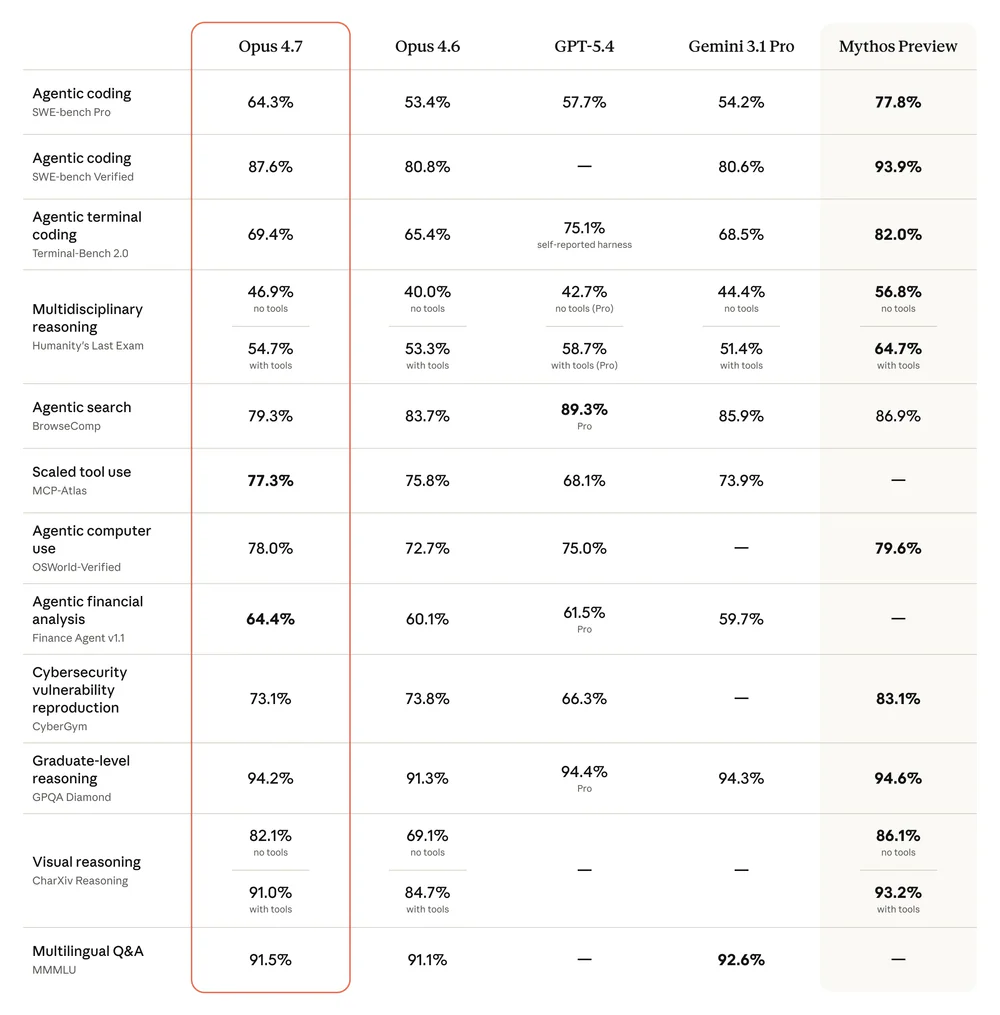
- Intelligence Index: 57.3 (+4 so với 4.6 ở 53).
- GDPval-AA: 1,753 Elo — dẫn 79 Elo so với Sonnet 4.6 (1,674) và GPT-5.4 xhigh (1,674); 134 Elo so với Opus 4.6 (1,619).
- AA-Omniscience: 26 (#2 sau Gemini 3.1 Pro 33). Hallucination rate giảm 25 p.p. xuống 36% (so với 61% ở 4.6). Attempt rate 70% — model từ chối trả lời nhiều hơn khi không chắc.
- SWE-bench Pro: 64.3% (vs 53.4% ở 4.6, 57.7% GPT-5.4, 54.2% Gemini 3.1 Pro).
- SWE-bench Verified: 87.6% (vs 80.8% trước).
- CursorBench: 70% (vs 58% ở 4.6).
- Gains khác so với 4.6: IFBench +5.5 p.p., TerminalBench Hard +5.3, HLE +2.9, SciCode +2.6, GPQA Diamond +1.8. Một regression nhẹ: τ²-Bench -3.5.
- Token & chi phí: dùng 102M output token để chạy Intelligence Index (vs 157M cho 4.6 — giảm 35%). Chi phí ~$4,406 (~11% thấp hơn 4.6 ở $4,970).
- Context: 1M token. Max output: 128K token.
Comparison — ba lab chia nhau ngai vàng
Kết quả cho thấy chiến thắng chuyên biệt hoá, không còn chiến thắng toàn diện:
| Lab | Model | Dẫn về |
|---|---|---|
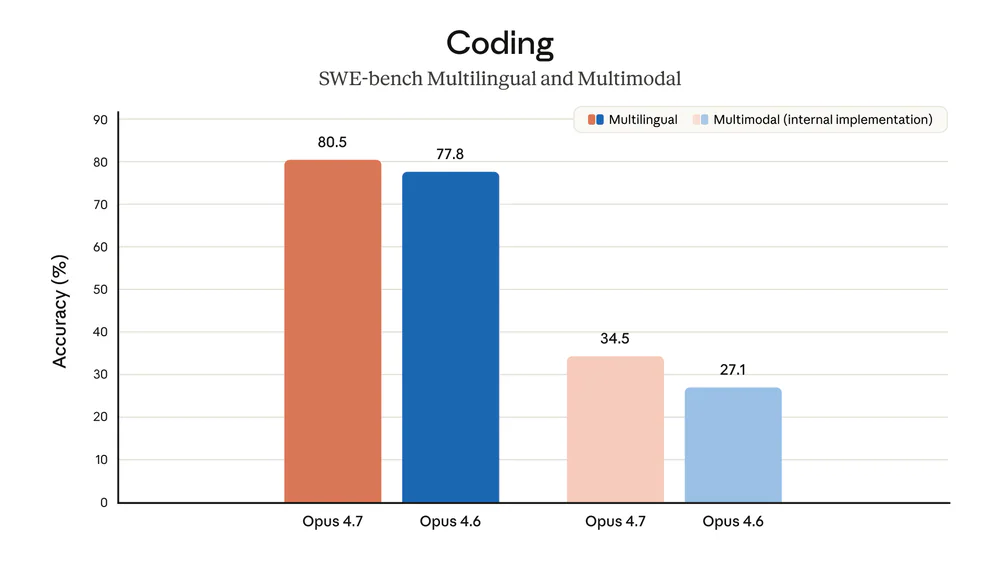
| Anthropic | Opus 4.7 | GDPval-AA (agentic thực tế), SWE-bench Pro/Verified/Multilingual, CursorBench, OfficeQA Pro, Finance Agent, BigLaw Bench |
| Gemini 3.1 Pro | HLE, GPQA Diamond, SciCode, IFBench, AA-Omniscience (+ 2M context, giá $2/$12) | |
| OpenAI | GPT-5.4 | TerminalBench Hard, CritPt, AA-LCR |
GPQA Diamond đã bão hoà: Opus 4.7 (94.2%), GPT-5.4 Pro (94.4%), Gemini 3.1 Pro (94.3%) — sự khác biệt nằm trong noise. Competitive differentiation đã chuyển hoàn toàn sang applied performance trên tác vụ nhiều bước.
Use cases — partner validation
Gần 30 đối tác enterprise đã test trước khi ra mắt. Một số highlight:
- Box: giảm 56% model calls, 50% tool calls, nhanh hơn 24%, tốn 30% ít AI Units hơn Opus 4.6.
- Notion (Michael Truell): "+14% so với 4.6 với ít token hơn và 1/3 tool errors. Đây là reliability jump khiến Notion Agent cảm giác như một teammate thật."
- Devin (Scott Wu): "Làm việc mạch lạc hàng giờ, đẩy xuyên qua các vấn đề khó thay vì bỏ cuộc — mở ra cả lớp deep investigation work mà trước đây không chạy ổn định."
- XBOW (cybersec): visual-acuity benchmark nhảy từ 54.5% (Opus 4.6) lên 98.5% — mở khoá autonomous pen-testing.
- Harvey (legal): 90.9% trên BigLaw Bench, phân biệt chính xác điều khoản assignment vs change-of-control.
- Vercel (Joe Haddad): "Thậm chí còn làm proof trên systems code trước khi bắt đầu — hành vi mới mà các Claude đời trước không có."
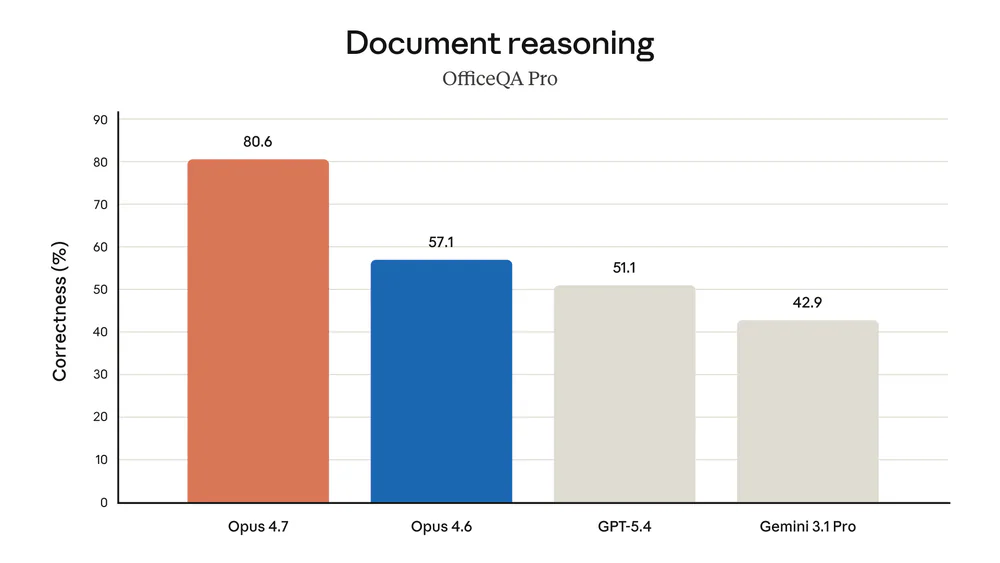
- Databricks: 21% lỗi ít hơn trên OfficeQA Pro.
Limitations & pricing
Không phải không có trade-off:
- "Token eating machine": Decrypt cạn sạch quota trong một session khi 4.7 tự viết lại toàn bộ codebase nhiều lần. Ở effort cao, model thinking sâu hơn ở các turn sau trong agentic workflow — phù hợp tác vụ khó nhưng tốn token đáng kể.
- Prompts cũ có thể vỡ: Opus 4.7 diễn giải instruction theo nghĩa đen. Prompt viết cho model trước dựa vào cách diễn giải lỏng sẽ cần re-tune.
- Chain-of-thought hiển thị: reasoning lộ ra ở main text output thay vì ẩn trong thinking box — minh bạch hơn nhưng làm output dài hơn.
- Cyber capabilities bị giảm chủ động: Anthropic "experimented with efforts to differentially reduce" khả năng cyber trong training. Automated safeguards tự block high-risk cybersec prompts. Security pro có thể đăng ký Cyber Verification Program.
- Safety profile: tương tự 4.6 — "largely well-aligned, though not fully ideal" theo đánh giá alignment của Anthropic.
Giá & availability: $5 input / $25 output per 1M token — không đổi từ Opus 4.5 và 4.6. Prompt caching giảm tới 90%, Batch API giảm 50%. Có mặt trên Claude.ai (Pro/Max/Team/Enterprise), Claude API (claude-opus-4-7), Amazon Bedrock, Google Vertex AI, Microsoft Foundry, Claude Code và Claude Cowork.
What's next
Anthropic đã thiết lập cadence phát hành Opus mỗi 2 tháng (4.5 → 4.6 → 4.7). Nếu giữ nhịp, Opus 4.8 có thể rơi vào giữa tháng 6. Nhưng câu chuyện lớn hơn đang chờ phía sau: Claude Mythos Preview — model frontier thật sự của Anthropic — hiện chỉ mở cho 11 tổ chức dưới Project Glasswing (bao gồm Apple). Mythos là AI đầu tiên hoàn thành "The Last Ones" của UK AI Security Institute: mô phỏng tấn công mạng doanh nghiệp 32 bước mà red team người thường mất 20 giờ. Opus 4.7 là bước chạy thử các safeguards trước khi Anthropic dám mở rộng release cho Mythos-class.
Nguồn: Anthropic, TNW, Decrypt, Artificial Analysis.