
- Anthropic tung Claude Opus 4.7 ngày 16/4/2026 với 64.3% SWE-bench Pro — vượt GPT-5.4 (57.7%) và Gemini 3.1 Pro (54.2%).
- Ảnh 3.75MP, auto mode, /ultrareview, và model tự verify output trước khi trả về.
TL;DR
Ngày 16/4/2026, Anthropic phát hành Claude Opus 4.7 — model generally available mạnh nhất của họ, xếp ngay dưới Claude Mythos Preview (hạn chế). Điểm đáng chú ý:
- 64.3% SWE-bench Pro, vượt GPT-5.4 (57.7%) và Gemini 3.1 Pro (54.2%)
- Ảnh tối đa 2,576px / 3.75 megapixel — gấp hơn 3 lần Claude cũ
- Tuân thủ prompt sát nghĩa đen, tự nghĩ cách verify output trước khi trả về
- +14% hiệu năng multi-step, dùng ít token hơn, chỉ 1/3 tool error so với 4.6
- Giá giữ nguyên $5/$25 mỗi triệu token input/output
Có gì mới
Opus 4.7 không phải bước nhảy thế hệ — Anthropic định vị nó là một focused improvement nhắm vào ba mảng: agentic software engineering, multimodal reasoning và long-running autonomous task. Ba điểm thay đổi hành vi đáng chú ý:
- Self-verify: model tự nghĩ cách kiểm tra output trước khi báo lại. Hệ quả lớn cho CI/CD pipeline và agent chạy nhiều bước.
- Literal instruction following: không tự khái quát hóa, không tự suy diễn yêu cầu. Prompt cũ có thể cần tune lại.
- Continue through tool failure: không đứng yên khi một tool fail, tự recover và chạy tiếp.
Tại sao quan trọng
Câu đáng nhớ nhất trong thông báo: nhiều developer giờ có thể hand off công việc coding khó nhất — loại trước đây cần giám sát sát sao — cho Opus 4.7. CEO của Cursor cho biết CursorBench nhảy từ 58% lên 70%; CEO Notion nói đây là "reliability jump" khiến Notion Agent cảm giác như đồng đội thật. Đó không phải là điểm số trên bảng, đó là thay đổi cách làm việc với LLM.
Technical facts
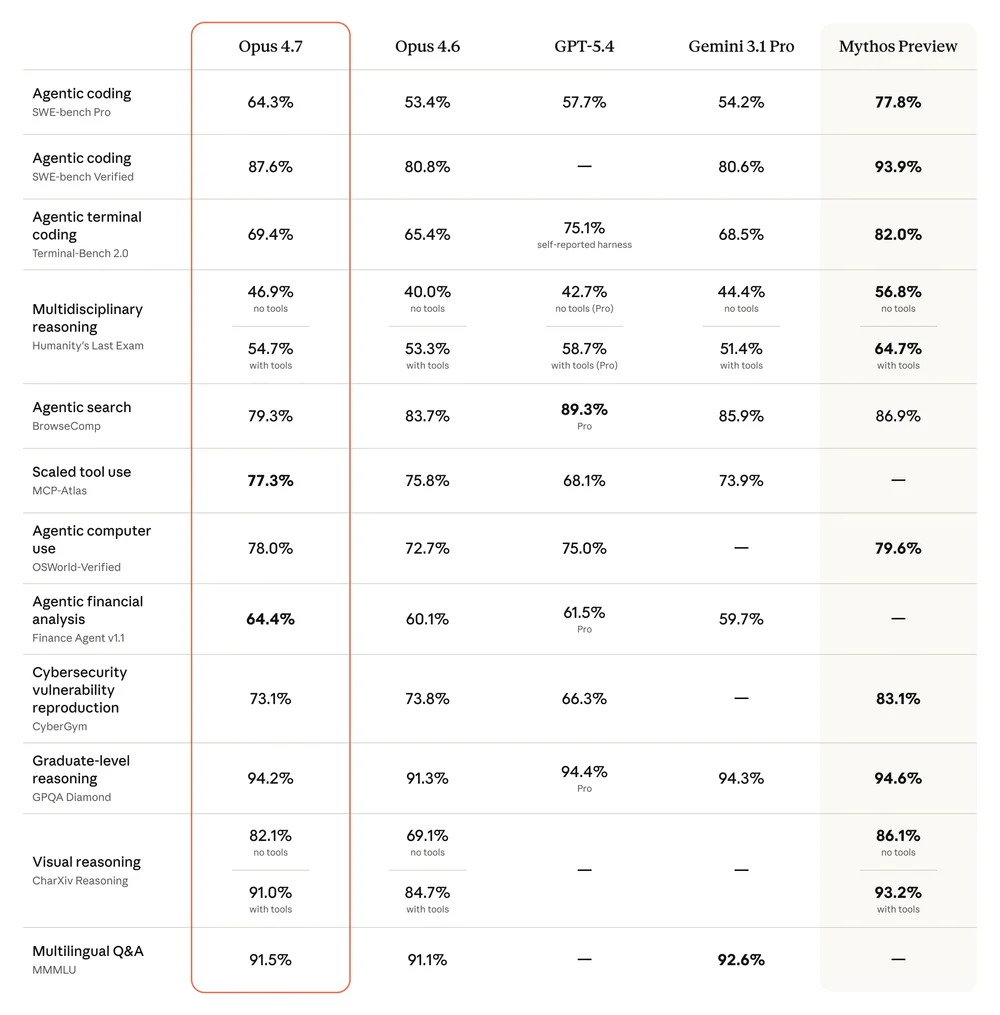
Số liệu từ system card của Anthropic (tổng hợp qua Vellum và báo chí):
| Benchmark | Opus 4.7 | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| SWE-bench Verified | 87.6% | 80.8% | — | 80.6% |
| MCP-Atlas (tool use) | 77.3% | 75.8% | 68.1% | 73.9% |
| OSWorld-Verified | 78.0% | 72.7% | 75.0% | — |
| Finance Agent v1.1 | 64.4% | 60.1% | 61.5% | 59.7% |
| GPQA Diamond | 94.2% | 91.3% | 94.4% | 94.3% |
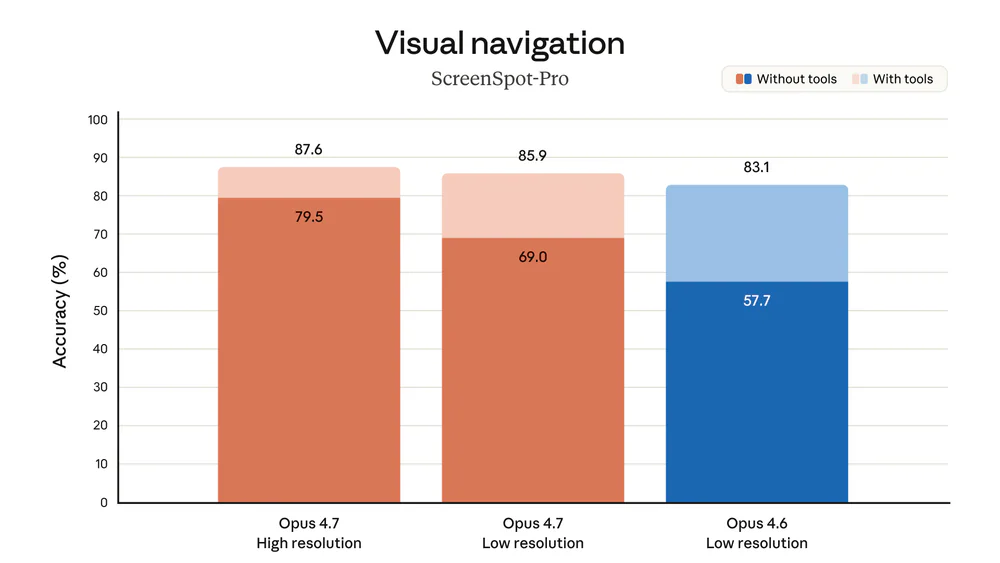
Vision mới: nhận ảnh đến 2,576px long edge (~3.75MP), gấp 3.2 lần giới hạn cũ (1,568px / 1.15MP). Document Reasoning (OfficeQA Pro) nhảy từ 57.1% lên 80.6%. XBOW — đối tác test computer-use cho autonomous pentest — báo cáo visual acuity lên 98.5% từ 54.5% ở Opus 4.6: gần như xóa sạch pain point lớn nhất của Opus trong workflow của họ.
Comparison
Với Opus 4.6: +14% trên workflow multi-step, token ít hơn, tool error chỉ bằng 1/3. Là Claude đầu tiên pass implicit-need test (suy ra tool nào cần dùng khi prompt không nói rõ).
Với GPT-5.4: thắng rõ ở SWE-bench Pro (+6.6pt), MCP-Atlas (+9.2pt), OSWorld (+3pt). Nhưng thua ở BrowseComp (79.3% vs 89.3% Pro) và Humanity's Last Exam với tools (54.7% vs 58.7% Pro). Coding + tool-calling → chọn Opus 4.7. Research-heavy browsing → GPT-5.4 Pro vẫn trên tay.
Với Gemini 3.1 Pro: dẫn SWE-bench Pro (+10.1pt), SWE-bench Verified (+7pt), MCP-Atlas, Finance Agent. Gemini thắng BrowseComp (85.9% vs 79.3%) và MMMLU multilingual (92.6% vs 91.5%). Gemini rẻ hơn đáng kể: $2/$12 so với $5/$25.
Use cases
- Autonomous coding agent: giao task khó qua đêm, chạy long-horizon. Cursor, Vercel, Notion đều là early-access partner công khai khen.
- Multi-agent orchestration: chạy song song code review + phân tích document + xử lý data thay vì tuần tự — throughput tăng thật.
- Computer-use: đọc UI dày đặc, thao tác GUI, chụp/đọc screenshot có chữ nhỏ. Đây là nơi vision 3.75MP tạo khác biệt.
- Enterprise document intelligence: hợp đồng scan, bản vẽ kỹ thuật, báo cáo tài chính có fine print.
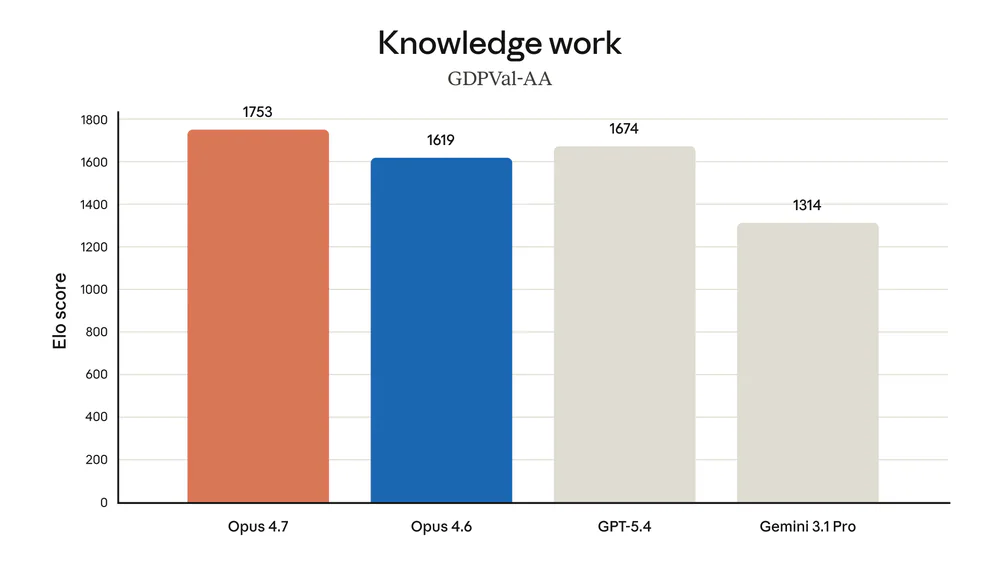
- Finance/legal knowledge work: state-of-the-art trên GDPval-AA (đánh giá công việc tri thức có giá trị kinh tế).
Limitations & pricing
Regression rõ ràng: BrowseComp giảm 4.4 điểm (83.7% → 79.3%). Agent chuyên browsing web sẽ cảm nhận được.
Tokenizer mới: cùng một đoạn text có thể tốn 1.0–1.35× số token so với Opus 4.6. Giá per-token giữ nguyên nhưng hóa đơn thực tế có thể tăng. Anthropic khuyên đo trên traffic thật.
Cyber safeguard: real-time block request cybersecurity prohibited/high-risk. Security pro hợp pháp cần apply vào Cyber Verification Program. Đây là test case đầu tiên cho Project Glasswing — Anthropic dùng Opus 4.7 để validate safeguard trước khi release Mythos-class model rộng rãi.
Giá: $5/M input, $25/M output — giống Opus 4.6. Prompt caching giảm tới 90%, Batch API giảm 50%. Có mặt trên Claude Pro, Max, Team, Enterprise, Claude API (claude-opus-4-7), Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry.
What's next
Cùng ngày launch, Anthropic còn đẩy thêm ba cần gạt cho developer:
- xhigh effort level: giữa
highvàmax. Claude Code đã mặc định xhigh cho mọi plan. - Task budgets: public beta trên Claude Platform API — điều phối token spend qua nhiều lượt tool call.
- /ultrareview: slash command trong Claude Code, chạy phiên review đọc sạch changeset, flag bug và design issue như senior engineer. Pro + Max được 3 lượt miễn phí.
- Auto mode mở rộng cho Max user: Claude tự quyết định thay bạn để chạy task dài ít gián đoạn hơn.
Về dài hạn, Opus 4.7 là bước đệm kiểm chứng Project Glasswing. Mythos Preview (77.8% SWE-bench Pro, 93.9% SWE-bench Verified) mới là đỉnh thực sự — nhưng vẫn restricted release. Nếu safeguard trên Opus 4.7 hoạt động ổn trong thực địa, Mythos-class sẽ mở rộng sau.
Nguồn: Anthropic, Claude API Docs, Vellum benchmarks, VentureBeat, The Decoder.