
- Tại Cloud Next 2026, Google tách thế hệ TPU thứ 8 thành hai con chip riêng: 8t cho training, 8i cho inference.
- Pod 9.600 chip, 121 FP4 exaflops, SRAM on-chip gấp 3 lần — và Anthropic vừa cam kết 3,5 GW compute cho Google.
TL;DR
Ngành AI vừa đâm thẳng vào latency wall. Khi mô hình chuyển từ trả lời câu hỏi sang chạy agent nhiều bước real-time, cổ chai không còn là "train to nổi không" mà là "serve nhanh tới đâu". Tại Google Cloud Next 2026, Google làm điều chưa từng: tách TPU thế hệ 8 thành hai con chip khác nhau — TPU 8t cho training và TPU 8i cho inference. 2x perf/watt so với Ironwood, pod 9.600 chip, 121 FP4 exaflops, SRAM on-chip 384 MB (gấp 3 Ironwood). Anthropic vừa ký 3,5 GW compute 2027. Google giờ sở hữu full-stack từ silicon đến mô hình Gemini đến cloud — không ai khác trong cuộc đua có vị thế đó.

Có gì mới
Google trích dẫn nguyên văn vấn đề tại Cloud Next:
Khi bước vào kỷ nguyên agent, ngành công nghiệp đang đâm vào cái chúng tôi gọi là latency wall — nơi kiến trúc truyền thống vật lộn với nhu cầu real-time của autoregressive decoding và chain-of-thought reasoning.
Giải pháp: bỏ triết lý "một con chip trị cả training lẫn inference" đã dùng suốt 7 thế hệ Ironwood. Thay vào đó là hai silicon chuyên biệt, cả hai do Google DeepMind cùng thiết kế, ra mắt cùng lúc, GA cuối năm 2026.
- TPU 8t (training) — nén chu kỳ phát triển mô hình frontier từ vài tháng xuống vài tuần.
- TPU 8i (inference) — tối ưu riêng cho agent, chain-of-thought và serve đa phiên.
Thông số kỹ thuật
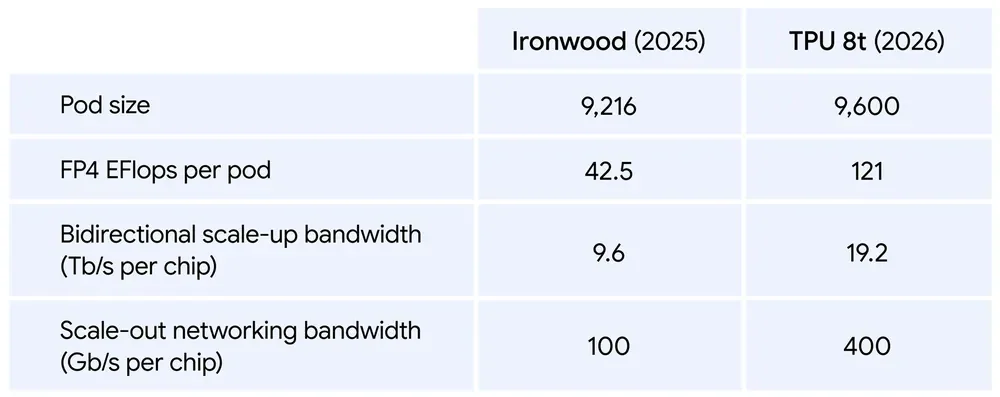
TPU 8t — con quái vật training:
- 12,6 FP4 PFLOPs/chip, pod 9.600 chip (vs 9.216 Ironwood) → 121 exaflops FP4 mỗi pod (gần gấp 3 Ironwood)
- 216 GB HBM, 128 MB SRAM on-chip, băng thông HBM 6.528 GB/s
- Scale-up 19,2 Tb/s mỗi chip (gấp đôi), scale-out 400 Gb/s (gấp 4 lần Ironwood)
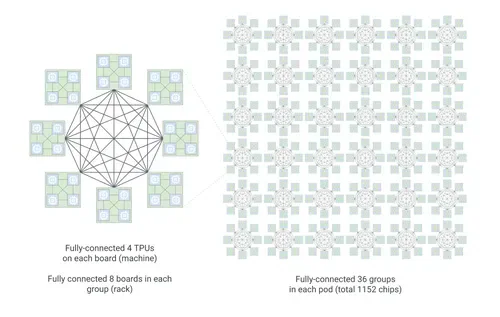
- Virgo fabric kết nối 134.000+ chip, 47 petabit/s throughput, scale tuyến tính tới 1 triệu chip trong một logical cluster
- Truy cập storage nhanh gấp 10 thế hệ trước, goodput >97%
- 2,7x perf/dollar so với Ironwood cho training quy mô lớn
TPU 8i — con chip của agent era:
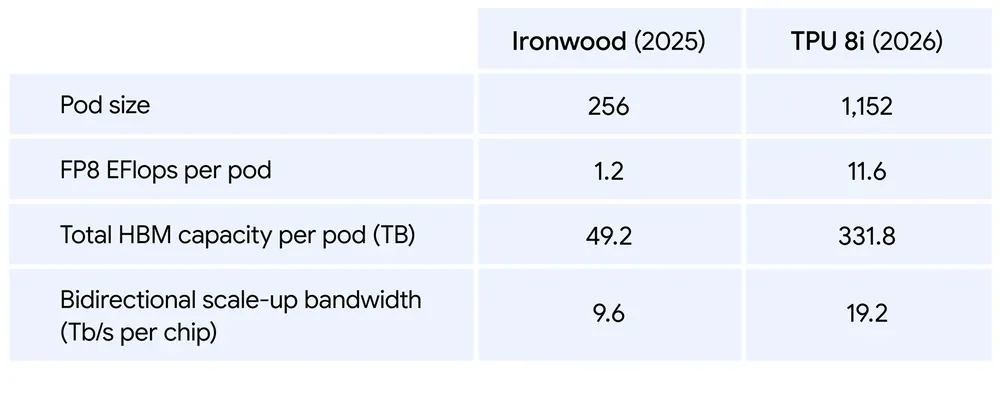
- 10,1 FP4 PFLOPs/chip, pod 1.152 chip, 11,6 FP8 exaflops, 331,8 TB HBM/pod
- 384 MB SRAM on-chip — gấp 3 Ironwood → toàn bộ working memory của agent nằm ngay trên chip, không phải fetch từ memory ngoài
- 288 GB HBM, băng thông 8.601 GB/s (cao hơn 8t ~1,3x)
- Collectives Acceleration Engine (CAE) — giảm latency collective op on-chip tới 5 lần
- Boardfly topology: đường kính network còn 7 hop (giảm 56% so với 16 hop của 3D torus)
- Axion ARM CPU host gấp đôi mỗi server, interconnect 19,2 Tb/s cho MoE
- +80% perf/dollar so với Ironwood, capacity gấp đôi cùng chi phí
Cả hai chip: 2x perf/watt so với Ironwood — chỉ số quan trọng nhất khi chi phí điện giờ là cổ chai của data center. Hỗ trợ native JAX, MaxText, PyTorch, SGLang, vLLM. Làm mát bằng liquid cooling gen 4.
So sánh Ironwood vs 8t vs 8i
| Chỉ số | Ironwood (gen 7) | TPU 8t (training) | TPU 8i (inference) |
|---|---|---|---|
| FP4 PFLOPs/chip | 4,6 | 12,6 | 10,1 |
| Chip/pod | 9.216 | 9.600 | 1.152 |
| SRAM on-chip | 128 MB | 128 MB | 384 MB |
| HBM/chip | — | 216 GB | 288 GB |
| FP-compute/pod | 42,5 EF | 121 EF (FP4) | 11,6 EF (FP8) |
| Perf/dollar vs Ironwood | baseline | +2,7x | +80% |
| Perf/watt vs Ironwood | baseline | 2x | 2x |
| Latency collective op | baseline | — | giảm 5x |
Vì sao đáng chú ý
Kiến trúc GPU truyền thống (kể cả H100/H200/B200) thiết kế cho pretraining batch lớn. Khi bạn chạy một agent suy luận 20 bước liên tiếp, mỗi bước đều cần đọc lại KV cache, chờ collective sync, rồi sinh token tiếp theo — GPU mạnh mấy cũng vấp phải memory latency. Đó là latency wall.
TPU 8i giải quyết đúng điểm đó: 384 MB SRAM đủ chứa working set của agent trong cache nhanh nhất, và CAE xóa bottleneck đồng bộ giữa các chip. Kết quả không chỉ là nhanh hơn — mà là nhanh đủ để agent real-time khả thi về mặt kinh tế.
Ai được lợi
- Anthropic — vừa ký mở rộng lên 3,5 GW compute TPU năm 2027, đào tạo Claude/Mythos trên stack này
- Meta — thuê TPU thông qua Google Cloud (không phải mua đứt)
- Google Gemini — dòng frontier model của chính Google chạy trên TPU 8t/8i end-to-end
- Enterprise agent builders — ai đang xây sản phẩm agent (code agent, deep research, voice agent) sẽ thấy cost/token giảm mạnh khi switch sang 8i
- Citadel Securities — được Google nêu tên là khách hàng pioneer cho workload AI tiên tiến
Hạn chế & giá
- Google chỉ công bố perf/dollar tương đối, không phải giá list tuyệt đối
- Process node không xác nhận chính thức trên keynote — báo chí nói Broadcom thiết kế 8t ("Sunfish"), MediaTek thiết kế 8i ("Zebrafish"), cả hai trên TSMC 2nm
- Chỉ sở hữu qua Google Cloud, không bán rời như GPU
- GA "cuối 2026" — chưa có ngày cụ thể
- Ironwood (gen 7) vừa GA cùng event này, workload hiện hữu có thể ở lại đó
Bức tranh lớn hơn
Đây không chỉ là câu chuyện chip. Nhìn toàn cảnh: Google giờ sở hữu end-to-end — silicon, fabric, cooling, mô hình frontier (Gemini), và cloud phân phối. Anthropic train Claude trên TPU. Meta thuê. Gemini chạy trên chính stack đó.
Đó là vị thế cạnh tranh rất khác so với bất kỳ ai khác trong đường đua AI — NVIDIA có silicon nhưng không có mô hình frontier, OpenAI có mô hình nhưng đi thuê compute, Microsoft có cloud nhưng phụ thuộc NVIDIA. Chỉ Google (và ở mức độ nhỏ hơn là Amazon với Trainium) có full stack.
Chu kỳ tiếp theo (gen 9) nhiều khả năng 12–18 tháng nữa, tiếp tục giữ phân tách training/inference. Và cuộc di cư toàn ngành từ "GPU đa năng" sang "silicon inference chuyên biệt" sẽ chỉ tăng tốc.
Nguồn: blog.google, Google Cloud Blog, SiliconANGLE, Anthropic.
