- Google Research và Google Cloud công bố framework Agentic RAG mới trong Gemini Enterprise Agent Platform, đang ở public preview.
- Trên FramesQA (824 query, 2,676 PDF), accuracy cải thiện tới 34% so với vanilla RAG.
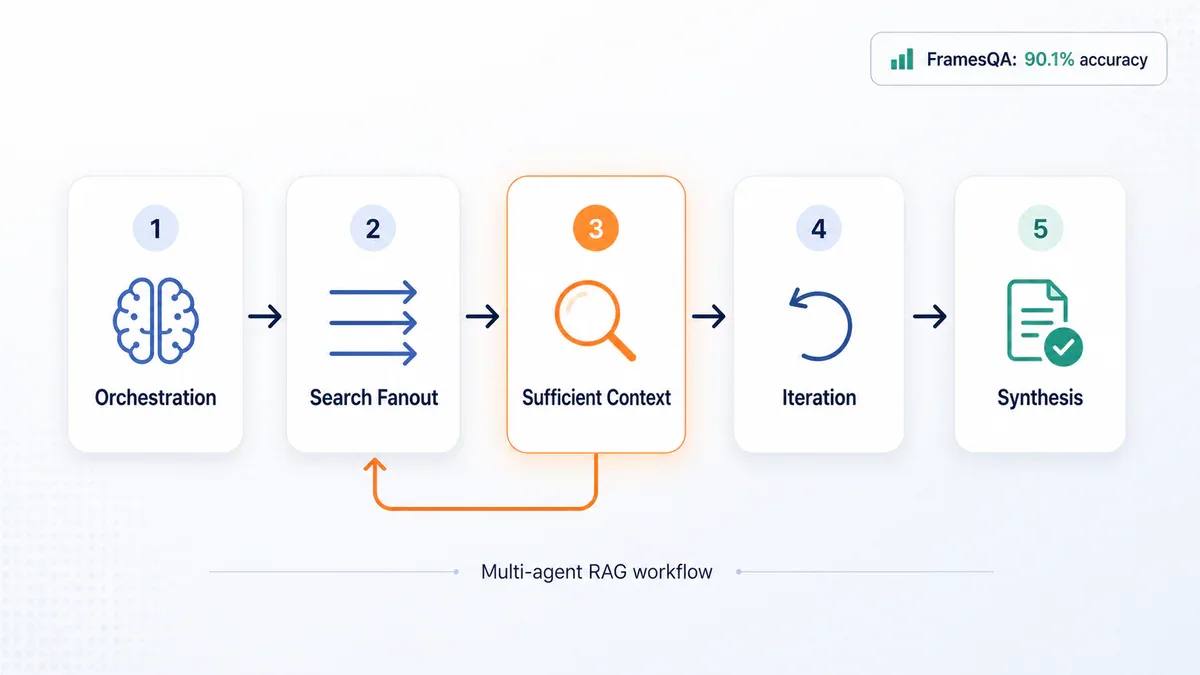
- Cross-corpus đạt 90.1% accuracy khi Planner Agent phải chọn đúng 1 trong 4 corpus, latency chỉ chậm hơn single-corpus trong vòng 3%.
- Điểm khác biệt: Sufficient Context Agent quyết định khi nào dữ liệu đủ và buộc hệ thống search tiếp khi chưa đủ.
TL;DR
- Google Research và Google Cloud ra Agentic RAG framework mới, host trong Gemini Enterprise Agent Platform dưới dạng Cross-Corpus Retrieval, hiện public preview.
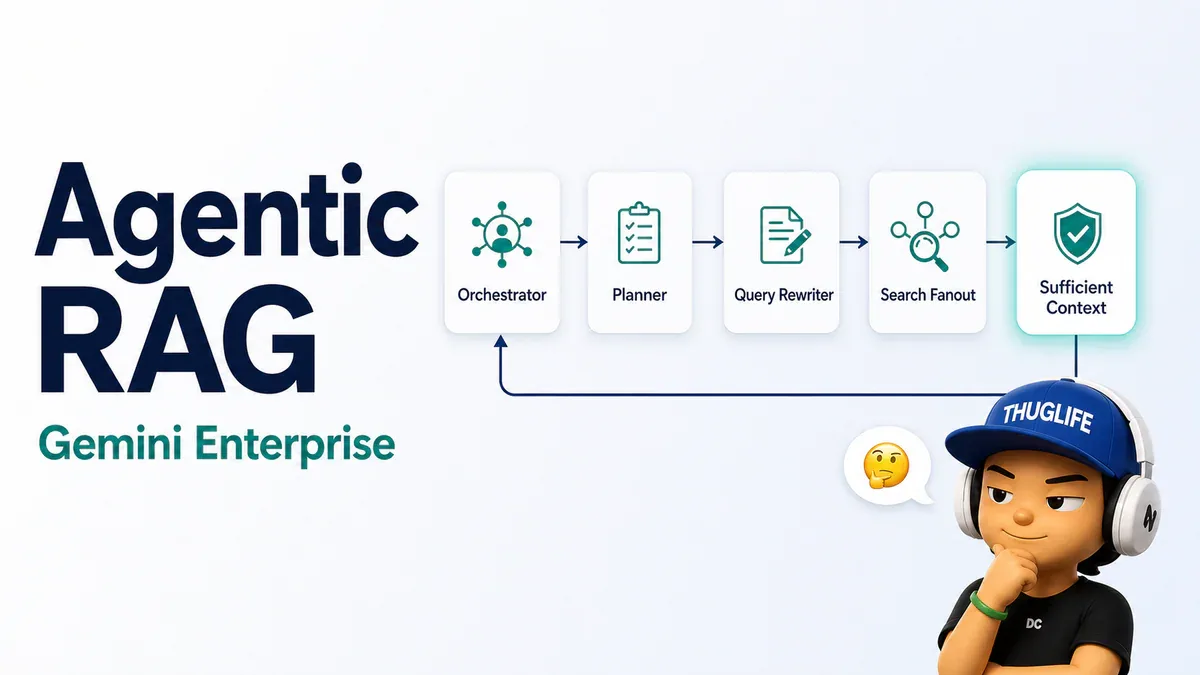
- Workflow 5 agent: Orchestrator, Planner, Query Rewriter, Search Fanout, Sufficient Context. Agent cuối là điểm sáng tạo - nó quyết định data đã đủ chưa, chưa đủ thì ép search tiếp.
- Trên FramesQA: 824 query, 2,676 PDF. Cải thiện tới 34% accuracy so với vanilla RAG. Cross-corpus đạt 90.1% khi phải chọn đúng 1 trong 4 corpus, latency chênh dưới 3%.
- RAG Engine GA tại us-central1, us-east4, europe-west3, europe-west4. Hỗ trợ VPC-SC và CMEK. Pricing tính theo token Vertex AI, cộng Spanner nếu dùng managed vector DB.
Vấn đề mà vanilla RAG không giải nổi
RAG single-step được thiết kế cho câu hỏi gọn: 1 query, 1 lượt retrieve, 1 lượt sinh. Workflow doanh nghiệp không đơn giản như vậy. Câu hỏi điển hình kiểu "specs của server dùng trong Project X là gì?" gãy ngay ở bước đầu - tài liệu Project X có nhắc tới server ID, nhưng specs lại nằm ở DB inventory khác. Hệ thống dừng ở partial answer hoặc trả "not found" vì không biết phải đào tiếp.
Đây là vấn đề multi-hop multi-source kinh điển. Dữ liệu doanh nghiệp nằm rải rác trên nhiều "island" do các team khác nhau quản lý, mỗi island có schema riêng. Vanilla RAG không có cơ chế nhận ra mình thiếu gì, càng không có cơ chế tự sinh query tiếp theo.
Kiến trúc 5 agent thay vì 1 retriever
Thay vì coi RAG là một search engine, framework mới mô hình hoá nó như một phòng research thu nhỏ với phân vai rõ ràng:
- Orchestrator (Root Agent) - nhìn request, quyết định đây không phải one-step job, phân việc cho sub-agent.
- Planner Agent - vẽ pathway thông tin, xác định cần check những DB nào.
- Query Rewriter - dịch yêu cầu dài thành nhiều câu query đơn giản. "What's up with Project X?" thành "Status report for Project X Q3" cộng "Key blockers for Project X team".
- Search Fanout Agent (RAG Agent) - đẩy refined query tới các retrieval source, gom snippet về.
- Sufficient Context Agent - kiểm tra chất lượng cuối assembly line.
Sufficient Context Agent - chốt chặn quyết định khi nào đủ
Đây là phần Google Research mô tả là innovation chính. Sau khi RAG Agent fanout xong, Sufficient Context Agent xem ba thứ:
- Retrieved snippet - đọc text chunk thực tế trong DB, xem thông tin cần có thật sự nằm trong đó không.
- Intermediate draft - hệ thống viết draft thô, agent so prompt với draft và snippet để check đủ chưa.
- Missing pieces analysis - phần quan trọng nhất. Nếu thiếu, agent không chỉ nói "insufficient" mà sinh ra
ReasonvàFeedbacklog cụ thể, kiểu "đã có meds và diet, thiếu allergy, search thêm 'rashes' hoặc 'adverse events'".
Khi nhận feedback đó, Query Rewriter sinh search mới, RAG Agent đào sâu vào file đã bỏ qua, lặp cho tới khi Sufficient Context Agent đồng ý. Lúc đó Synthesis Agent mới viết câu trả lời cuối. Tính chất quan trọng nhất là persistence: không guess, không bỏ cuộc khi search đầu tiên trống, mà tiếp tục cho đến khi đủ context.
Benchmark FramesQA: 34% và 90.1%
Google đánh giá trên FramesQA - 824 query trên corpus 2,676 PDF document. Hai setup:
- Single-corpus: chỉ retrieve từ FramesQA docs.
- Cross-corpus: thêm 3 dataset "distracting" - Planner Agent phải tự chọn đúng corpus trên 4 lựa chọn, mô phỏng tình huống công ty có nhiều DB do team khác nhau quản lý.
So sánh với vanilla RAG (dùng Google RAG Engine có advanced retrieval, LLM parser, re-ranker), framework mới cải thiện tới 34% accuracy trên factuality dataset. Trong cross-corpus, dù phải route giữa 4 corpus, vẫn đạt 90.1% accuracy - gần bằng single-corpus. Latency cross-corpus chênh single-corpus trong vòng 3% trung bình. Phương pháp đo dùng LLM-as-a-judge so sánh với ground truth.
Trên dataset proprietary nội bộ, Google ghi nhận grounding tốt hơn và reasoning accuracy cao hơn trên nhiều domain-specific task. via Google Research
Use case: bác sĩ hỏi về bệnh nhân
Bài blog dùng một ví dụ healthcare khá đắt để minh hoạ. Bác sĩ hỏi:
"What are the discharge medications and dietary restrictions for John Doe after his knee surgery, and did he have any allergic reactions during his stay? Do not include medications only administered during hospital inpatient or emergency department visits except for heparin IV drip or Tenecteplase."
Flow chạy như sau:
- Root Agent phân việc. Planner xác định ba khu vực cần check: Pharmacy, Nutrition, Clinical Notes.
- RAG Agent fanout song song. Tìm thấy meds và diet, không thấy allergy ở file rõ ràng nhất.
- Sufficient Context Agent flag insufficient, feedback cụ thể "tìm thêm rashes hoặc adverse events".
- Query Rewriter sinh search mới, RAG Agent đào sâu file đã bỏ qua, tìm thấy info allergy.
- Synthesis Agent viết summary sạch trả về cho bác sĩ.
Vanilla RAG sẽ dừng ở bước 2 với câu trả lời thiếu. Pattern này áp dụng tốt cho mọi clinical assistance system ground qua EHR và PubMed, hoặc query đa nguồn kiểu budget cộng timeline của một project.
Availability và pricing
Cross-Corpus Retrieval powered by Agentic RAG đang là public preview trong Gemini Enterprise Agent Platform. RAG Engine underlying đã GA tại 4 region: us-central1 (Iowa), us-east4 (Virginia), europe-west3 (Frankfurt), europe-west4 (Eemshaven). Preview ở thêm rất nhiều region khác - asia-east1, asia-northeast1, asia-south1, europe-west1, us-west1...
Security: hỗ trợ VPC-SC và CMEK. Chưa hỗ trợ data residency và AXT security controls. Pricing tính theo số input/output token Vertex AI. Nếu dùng RAG Engine-managed Spanner instance làm vector database ở location GA, Google Cloud bill thêm Spanner instance đó.
Kết
Agentic RAG không phải khái niệm mới, nhưng cách Google đặt Sufficient Context Agent làm chốt chặn quyết định là điểm đáng để ý. Nó dịch khái niệm "persistence" từ research thành behavior cụ thể: hệ thống biết mình thiếu gì, biết cần search gì tiếp, và lặp cho đến khi đủ. Con số 34% accuracy improvement và 90.1% cross-corpus là tín hiệu khá mạnh cho team nào đang vật lộn với RAG trên dữ liệu rải rác. Public preview là cơ hội thử trước khi GA.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ