
Coding Agent Hay Phá Luật Hơn Viết Code Sai: Bằng Chứng Từ 20.574 Phiên Thực Tế
Nghiên cứu phân tích 20.574 phiên coding agent thực tế: lỗi phổ biến nhất là vi phạm ràng buộc developer, chiếm 38.33% - không phải viết code sai. Agent CLI vi phạm ràng buộc nhiều hơn IDE (49.49% vs 32.26%), nhưng IDE lại lỗi implement gần gấp 3 lần. 91.49% tình huống vẫn đòi developer sửa tay dù agent đã báo xong.

AI không tiết kiệm thời gian như bạn nghĩ - Và nghiên cứu 2.691 người chứng minh điều đó
Nghiên cứu từ Stanford, NYU, MIT và Princeton AI Lab khảo sát 2.691 người: kỳ vọng AI tiết kiệm 55,7 giây nhưng thực tế chỉ 7,5 giây. Người dùng còn đánh giá thấp mức độ mình dùng AI: nghĩ là 33% task nhưng thực tế đã dùng tới 47%. Carryover effect khiến mỗi lần dùng AI làm tăng khả năng dùng tiếp ở lần sau, kể cả khi tự làm nhanh hơn.

Google ra mắt OKF: Định dạng mở để AI Agent tự quản lý tri thức
Google Cloud phát hành Open Knowledge Format (OKF) v0.1 ngày 12/6/2026, chính thức hóa ý tưởng LLM Wiki của Andrej Karpathy thành một open specification. Spec chỉ 451 dòng, dùng markdown thuần với YAML frontmatter, không cần SDK hay platform độc quyền. Chỉ một trường bắt buộc duy nhất là type - mọi thứ còn lại là tùy chọn.
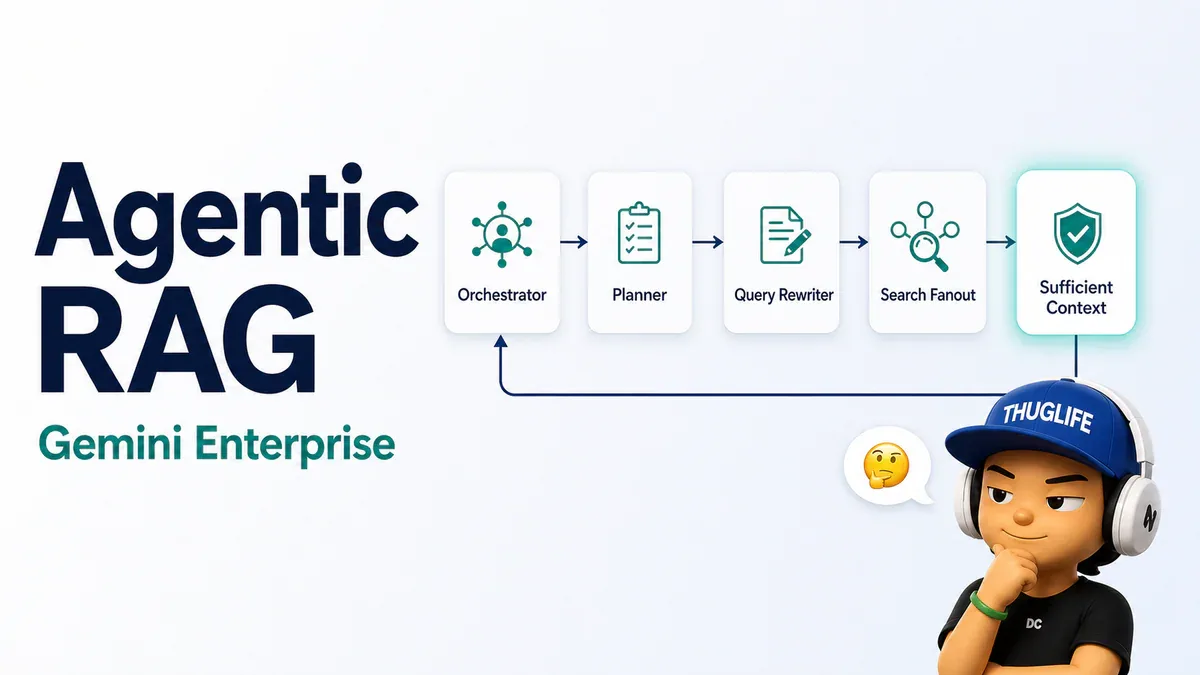
Gemini Enterprise Agentic RAG: khi RAG biết tự đào lại đến khi đủ dữ kiện
Google Research và Google Cloud công bố framework Agentic RAG mới trong Gemini Enterprise Agent Platform, đang ở public preview. Trên FramesQA (824 query, 2,676 PDF), accuracy cải thiện tới 34% so với vanilla RAG. Cross-corpus đạt 90.1% accuracy khi Planner Agent phải chọn đúng 1 trong 4 corpus, latency chỉ chậm hơn single-corpus trong vòng 3%. Điểm khác biệt: Sufficient Context Agent quyết định khi nào dữ liệu đủ và buộc hệ thống search tiếp khi chưa đủ.

Toàn Tập Hướng Dẫn Xây Dựng AI Agent Swarm - P2: Hạ Tầng và Cách Hoạt Động
Mooncake disaggregates prefill và decode cluster, đạt throughput tăng 525% và xử lý 75% requests nhiều hơn. Swarm hoạt động theo wave: wave đầu chạy subtask độc lập, wave sau xử lý task phụ thuộc kết quả trước. Kết hợp Kimi K2.6 làm execution layer ($0.95/M input token) với Claude Opus 4.8 làm planner và verifier - Opus 4.8 ít bỏ sót lỗi hơn 4x so với tiền nhiệm.
Toàn Tập Hướng Dẫn Xây Dựng AI Agent Swarm - P1: Kiến Trúc và Nền Tảng
Agent Swarm chạy subtask song song - thời gian tổng xấp xỉ max(A,B,C) thay vì A+B+C, giảm 3-4.5x wall-clock time. Kimi K2.6 là MoE 1 nghìn tỷ tham số, 32B active, 300 sub-agent đồng thời và 4.000 tool call mỗi session. Agent Swarm được train vào mô hình qua PARL - không phải framework gắn ở application layer. BrowseComp: swarm mode đạt 78.4%, tăng 17.8 điểm so với single-agent (60.6%).

Kimi K2.6 thay thế cả team dev: Blueprint xây dựng AI Agency $80k/tháng
Moonshot AI phát hành Kimi K2.6 ngày 20/4/2026 - model open-weight 1 trillion tham số, đạt 80.2% SWE-Bench Verified, dẫn đầu GPT-5.4 và Claude Opus 4.6 trên SWE-Bench Pro (58.6% vs 57.7%). Agent Swarm chạy 300 sub-agent song song, 4,000 bước phối hợp trong một lần chạy. Giá API $0.60/M input token - rẻ hơn Claude Opus 4.7 khoảng 5-6 lần. Với $500/tháng overhead, mô hình AI Agency một người có thể đạt $80k/tháng doanh thu theo blueprint từ cộng đồng.

Microsoft mở mã SkillOpt: train file SKILL.md như neural network
Microsoft công bố SkillOpt, framework treat file SKILL.md như trainable parameter của frozen LLM agent. Trên GPT-5.5, SkillOpt cộng +23.5 điểm accuracy trong direct chat, +24.8 trong Codex và +19.1 trong Claude Code. Best hoặc tied trên cả 52/52 cell (model x benchmark x harness). Skill artifact 300-2000 token, MIT license, không tốn thêm inference call lúc deploy.

Claude Opus 4.8 Ra Mắt: Sharper Judgment, Dynamic Workflows và Fast Mode Rẻ Hơn 3x
Anthropic phát hành Claude Opus 4.8 ngày 28/5/2026, chỉ 41 ngày sau Opus 4.7, với giá không đổi $5/$25 per 1M tokens. Agentic coding đạt 69.2% SWE-bench Pro - bỏ xa GPT-5.5 (58.6%) và Gemini 3.1 Pro (54.2%). Fast mode mới chạy 2.5x nhanh hơn và rẻ hơn 3x ($10/$50 per 1M thay vì $30/$150). Model còn ít khả năng bỏ sót lỗi code hơn Opus 4.7 tới 4 lần.

Repo 4.2k Star Dạy Build AI Agent Từ Đầu - Không Framework, Không Black Box
ai-agents-from-scratch là repo 4.2k star dạy build AI agent từ đầu, không LangChain, không CrewAI. 15 module tiến dần từ LLM cơ bản đến Tree of Thought - 100% JavaScript, chạy local với node-llama-cpp. Module 15 vừa ra hôm nay: tool routing bằng embeddings. Phase 2 roadmap: rebuild LangChain từ scratch với code có thể đọc được.

AI Agents Cũng Lão Hóa - Sau 100 Session, Agent Của Bạn Còn Đáng Tin Không
AgingBench phát hiện 4 cơ chế lão hóa khiến AI agent suy giảm dù model weights không thay đổi. Chỉ đổi compaction prompt tạo ra gap 4,5x về half-life. Typed-state overlay giảm accumulator error 47%. Forced re-read đẩy recall của Opus-4.7 từ 0,68 lên 0,91.

Qwen3.7-Max ra mắt: AI Agent chạy 35 giờ không nghỉ, bước tiến mới từ Alibaba
Alibaba ra mắt Qwen3.7-Max tại Cloud Summit 2026 - flagship model mới nhất thiết kế cho kỷ nguyên AI agent. Trong bài test nội bộ, model tự chạy 35 giờ liên tục với 1,158 tool calls, tối ưu kernel GPU đạt tốc độ tăng 10x. Context window 1 triệu token gấp 4 lần phiên bản trước, tích hợp native MCP và kết nối 1000+ tools. Benchmark GPQA Diamond đạt 92.4 - vượt Claude Opus 4.6 Max (91.3).

Inference Engine cho LLM: Kiến trúc và nền tảng bạn cần hiểu trước khi chọn
Inference engine không phải là model - nó là lớp phần mềm quyết định latency, chi phí và khả năng mở rộng. Prefill là compute-bound, decode là memory bandwidth-bound, và 5 bottleneck thực sự không liên quan gì đến thông số GPU bạn thường xem. Bài đầu trong series 4 phần về Self-hosted LLM 2026.

AI Agent của bạn cứ thất bại? Đây là hệ thống 8 bước để fix
Gartner dự đoán hơn 40% dự án agentic AI sẽ thất bại trước 2027 - chủ yếu vì thiếu hệ thống, không phải vì LLM kém. Framework 8 bước chuẩn (Define → Brain → Model → Tools → Memory → Orchestrate → Interface → Test) giúp agent đạt failure rate dưới 1%. Semantic caching giảm API call tới 70%, structured data governance giảm error rate AI apps tới 80%. Năm 2026, 40% enterprise apps sẽ có task-specific AI agents - cơ hội cho ai biết xây đúng cách.

Xây dựng LLM Architecture từ đầu - Phần 3: Dự án thực tế và 5 cách kiếm tiền với LLM Skills
Senior LLM freelancer kiếm $210/giờ trung bình năm 2026, tăng 45% trong 3 năm. Specialist fine-tuning và RLHF: $350-$700+/giờ. Phần 3 hướng dẫn 6 project nên build đầu tiên, 5 con đường kiếm tiền cụ thể (freelance, SaaS, remote jobs, agency, personal brand) và lộ trình 12 tháng từ zero đến remote engineer.

Xây dựng LLM Architecture từ đầu - Phần 2: Tokenization, Embeddings, Attention và RAG
4 khái niệm kỹ thuật cốt lõi phân biệt người dùng AI và người xây dựng AI: Tokenization, Embeddings, Attention Mechanism và Fine-tuning. Chuyên gia fine-tuning (LoRA, RLHF) đang kiếm $350-$700/giờ freelance 2026. Cộng thêm RAG - kỹ năng sinh tiền nhất để build private AI assistants - và cách deploy lên production thực tế.

Xây dựng LLM Architecture từ đầu - Phần 1: Python, Neural Networks và Transformer
LLM engineer senior hiện kiếm $200K-$320K/năm và freelance $175-250/giờ - premium 30-60% so với ML engineer thông thường. Bài Phần 1 hướng dẫn 3 nền tảng không thể bỏ qua: Python chuyên sâu, Neural Networks và kiến trúc Transformer ra đời từ bài báo lịch sử 'Attention Is All You Need'. Không cần PhD, không cần Silicon Valley.

4 Trụ Cột Agent Bền Vững - Phần 1: 88% AI Agent Chết Trong Production - Vấn Đề Không Nằm Ở Model
88% dự án agent không bao giờ ra production theo IDC 2026. MIT đo 95% tỷ lệ thất bại. Chỉ 5% trong số 1.837 developer được khảo sát có agent thật sự chạy production. Lý do không phải model kém - mà là kỹ thuật xung quanh model. Bài này đặt tên cho vấn đề: engineering deficit.

6 Bệnh Thần Kinh của AI Agent - P1: Source Amnesia, Phantom Limb và Locked-in Syndrome
Khi AI agent mắc lỗi, bạn thường đổ lỗi cho model - nhưng vấn đề thực sự thường nằm ở runtime. Model cho agent "não", còn runtime cho nó "thân thể": mắt, tay, bộ nhớ, phanh, cơ chế tự kiểm tra. Bài này phân tích 3 trong 6 bệnh thần kinh đã được ánh xạ từ y học sang hành vi agent: Source Amnesia, Phantom Limb State và Locked-in Syndrome. Model mạnh hơn không chữa được những bệnh này.

Harness Engineering (Phần 6): Khi Scaffolding Quan Trọng Hơn Model
Claude Opus 4.6 xếp hạng #33 trên Terminal Bench 2.0 trong native harness, nhưng vọt lên #5 chỉ bằng cách thay đổi cấu hình - không đụng vào model. ~98.4% codebase của Claude Code là infrastructure, chỉ 1.6% là AI decision logic. Harness engineering - discipline thiết kế scaffolding xung quanh model - đang trở thành kỹ năng cốt lõi của agentic era.

Claude Managed Agents: xây agent AI trong vài giờ thay vì vài tháng
Anthropic ra mắt Claude Managed Agents ngày 8/4/2026 - infrastructure layer cho phép triển khai agent tự động trong vài ngày, không cần tự xây sandbox hay quản lý credential. Tính năng Dreaming giúp Harvey Legal tăng completion rate lên 6x mà không thay đổi model. Multiagent Orchestration (công bố 6/5/2026) cho phép tối đa 20 agent chuyên biệt chạy song song. Giá $0.08/session-hour cộng token rate thông thường.

PageIndex: Khi RAG Bỏ Hẳn Vector Database Mà Vẫn Đạt 98.7% Accuracy
PageIndex là framework RAG mã nguồn mở của VectifyAI, loại bỏ hoàn toàn vector database và document chunking. Mafin 2.5 - hệ thống phân tích tài chính dùng PageIndex - đạt 98.7% trên FinanceBench, so với ~50% của vector RAG truyền thống. Thay vì tính cosine similarity, PageIndex xây cây phân cấp từ tài liệu rồi dùng LLM lý luận qua cây để truy xuất đúng section. MIT License, 31.5k GitHub stars, hỗ trợ MCP tích hợp trực tiếp vào Claude, Cursor và các AI agent frameworks.

10 Repos Giảm Token Bill AI Agent Tới 80% - Không Ai Kiểm Tra Cái Đang Gửi Đi
Hầu hết AI agent tốn kém không phải vì model đắt, mà vì không ai kiểm soát lượng token gửi đi. 10 open-source repos này giải quyết vấn đề đó ở 7 layer khác nhau. LLMLingua nén prompt tới 20x trước khi gọi API với gần như không mất chất lượng. mem0 cô đọng 10,000 token conversation history xuống còn 200 token per agent. LiteLLM route tác vụ đơn giản sang Haiku thay vì Sonnet - tiết kiệm 20x chi phí trên cùng một output.

RAG tiến hóa như thế nào: Từ Retrieval đơn giản đến Agentic AI
RAG đã trải qua 6 giai đoạn tiến hóa - từ keyword search thủ công đến Agentic AI tự lên kế hoạch và tự sửa lỗi. Agentic RAG tốn 3-10x token và thêm 2-5x latency, nhưng đáng giá với các tác vụ multi-hop phức tạp, y tế, pháp lý. MCP trở thành chuẩn Linux Foundation tháng 12/2025 - báo hiệu RAG sắp biến thành tầng hạ tầng cốt lõi của mọi ứng dụng AI.

Foundations of Large Language Models - Cuốn sách 247 trang miễn phí bạn nên đọc ngay
Foundations of Large Language Models là sách học thuật 247 trang, miễn phí trên arXiv, bao phủ 5 trụ cột kỹ thuật từ pre-training đến inference. Tác giả Tong Xiao và Jingbo Zhu dùng ký hiệu toán học chuẩn với Q/K/V matrices, KL divergence, RLHF formal derivations. Chương 5 gồm inference-time scaling kiểu o1 - rare trong sách giáo khoa foundational. License CC BY-NC 4.0, tải PDF miễn phí tại arxiv.org/abs/2501.09223.

Andrej Karpathy vừa cho bạn khoá học LLM tốt nhất thế giới - miễn phí trên YouTube
Karpathy phát hành video 3h31m "Deep Dive into LLMs like ChatGPT" - bao trọn pipeline từ tokenization, transformer đến RLHF và DeepSeek-R1, hoàn toàn miễn phí. GPT-2 từng tốn $40,000 để train năm 2019, Karpathy tái tạo lại với $672 và chứng minh con số đó có thể xuống $100 hôm nay. Không cần background lập trình, không cần toán - chỉ cần 3 tiếng rưỡi đầu tư một lần.

7 GitHub repos để học AI thật sự trong 2026 (tất cả miễn phí)
7 repos tổng cộng hơn 490k stars trên GitHub, cover từ zero đến production-ready AI. microsoft/generative-ai-for-beginners đạt 98.1k stars với 21 bài học có cấu trúc. rasbt/LLMs-from-scratch lên 92k stars - build ChatGPT bằng PyTorch từ tokenization đến fine-tuning. Tất cả free, không cần đăng ký hay trả phí.

PageIndex: Xuất sắc trong niche của nó - nhưng Twitter đang hype quá mức
PageIndex đạt 98.7% accuracy trên FinanceBench - một benchmark tài chính cực khó - nhờ cách tiếp cận vectorless hoàn toàn mới. Tuy nhiên, bản OSS chỉ thực sự mạnh với 1 tài liệu dài; multi-document cross-folder search đòi hỏi tier Enterprise mới ra mắt. Hype trên Twitter không sai, chỉ thiếu context quan trọng.

Multi-Agent Orchestration: Khi AI biết phân công lao động
Multi-agent vượt single-agent Claude Opus 4 tới 90.2% trong benchmark nghiên cứu. Mỗi sub-agent có context window riêng, cùng chia sẻ filesystem để phối hợp - đây là kiến trúc đang reshape cách AI xử lý bài toán phức tạp. Token tiêu tốn gấp 15 lần chat thường, nhưng tốc độ xử lý tăng tới 90% nhờ song song hóa.

2 Kiểu Kỹ Sư Tạo Ra AI Agent Thực Sự Hoạt Động
CTO của Listen Labs - startup AI vừa vào Forbes AI 50 với $100M funding - chỉ ra 2 profile kỹ sư tạo nên agent tốt: người "cảm" được LLM và người product engineer iterate nhanh từ thực tế. 57.3% tổ chức đã có agent trên production năm 2026. Vấn đề không còn là xây hay không, mà là xây nhanh thế nào.

10 Khái Niệm Cơ Bản Trước Khi Làm AI Agent - P2: ReAct, Multi-Agent và An Toàn
5 khái niệm nâng cao quyết định Agent của bạn có đáng tin cậy hay không: ReAct pattern, Multi-Agent collaboration, Error handling, Safety control và cách chọn framework đúng. Nhóm Multi-Agent thực tế chỉ 3-4 agent do coordination overhead tăng nhanh.

10 Khái Niệm Cơ Bản Trước Khi Làm AI Agent - P1: Nền Tảng Kiến Trúc
AI Agent không phải chatbot thông minh hơn - đó là một hệ thống thực thi hoàn chỉnh gồm LLM, tool calling, task planning, memory và context management. Bài này giải thích 5 khái niệm nền tảng bạn phải nắm trước khi bắt tay code Agent. MCP tháng 3/2026 đã vượt 97 triệu monthly SDK downloads.

Harness Engineering (Phần 1): Tại sao Claude Opus 4.7 và GPT-5.4 đạt 0% khi làm việc thật?
ProgramBench - benchmark mới từ nhóm SWE-Bench - vừa công bố kết quả gây sốc: Claude Opus 4.7, GPT-5.4, Gemini 3.1 Pro đều đạt 0% khi được yêu cầu rebuild phần mềm thực tế từ đầu. Lỗi không nằm ở model - mà nằm ở Harness. Harness Engineering là kỹ thuật xây dựng "bộ kiểm soát" bao quanh LLM, được tóm gọn bằng công thức: Agent = Model + Harness. Bài này giải thích tại sao công thức đó quyết định tất cả.

Kiến trúc Agentic AI: Mental Model để thiết kế hệ thống đa tác tử
Hệ thống multi-agent dùng gấp 15 lần token so với chat nhưng mang lại cải thiện hiệu suất 90.2% so với single-agent. Anthropic xác định 5 pattern orchestration chuẩn: Sequential, Concurrent, Group Chat, Handoff, và Magentic. Kiến trúc gồm 8 tầng từ Orchestration đến Foundation, mỗi tầng có vai trò không thể thiếu. MCP đang trở thành chuẩn giao tiếp giữa agent và tool trong năm 2026.
8 kỹ thuật prompting để LLM trả lời tốt hơn (không cần đổi model)
Đa số người dùng LLM dừng ở zero-shot — gõ câu hỏi, nhận câu trả lời, xong. Nhưng khi output không đủ tốt, fix đầu tiên không phải nâng model mà là sửa prompt. Đây là 8 kỹ thuật prompting đáng dùng năm 2026, gồm cả ARQ (90.2% tuân thủ chỉ dẫn) và Verbalized Sampling (đa dạng tăng 2x).

GraphGen: Sinh Dữ Liệu Huấn Luyện LLM từ Knowledge Graph
GraphGen là framework open-source tạo synthetic training data cho LLM từ knowledge graph, dùng ECE metric để nhắm vào knowledge gap cụ thể. Benchmark với Qwen2.5-7B: +15.5 điểm AIME25 (toán), +14.4 điểm SeedBench (nông nghiệp), +6.7 điểm GPQA-Diamond so với baseline tốt nhất. Sinh ~50,000 samples trong 2 giờ trên 8 A100, output đa dạng hơn 59% (MTLD 75.8 vs 47.6). Apache 2.0, cài bằng uv pip install graphg.

Cách Viết System Prompt Claude Thực Sự Đưa Vào Production
Một constraint 25 từ thêm vào system prompt của Claude Code ngày 16/4/2026 gây ra mức giảm 3% benchmark intelligence - được xác nhận bởi postmortem chính thức của Anthropic. Thứ tự đúng các section (role → constraints → format → examples) giảm 23% out-of-schema response. Bài này phân tích template 9-section đứng sau mọi system prompt Claude đưa vào production, kèm 5 ví dụ thực tế cho thấy pattern thích ứng với các loại công việc khác nhau.

TradingAgents-CN: Khi AI Mô Phỏng Cả Một Phòng Quant Wall Street
TradingAgents-CN đạt 25.2k stars - bản fork A-shares/HK/US của framework multi-agent LLM từ UCLA/MIT. 8 Agent LLM phối hợp mô phỏng nguyên xi một investment bank team. MongoDB + Redis tăng hiệu năng 10x, deploy Docker 5 phút. Backtest AAPL đạt +26.62% vs Buy&Hold -5.23% - nhưng đây là simulation, không phải live trading.

Multi-Agent Orchestration: Khi một AI không còn đủ
Anthropic's multi-agent research system vượt single Opus 4 tới 90.2% hiệu suất trên internal evaluation - token usage giải thích 80% variance. Kiến trúc hub-and-spoke chia task cho specialist agents chuyên biệt, mỗi agent chỉ làm một việc cực tốt. Quy tắc bị vi phạm nhiều nhất: context KHÔNG tự động truyền giữa agents - phải pass tường minh hoàn toàn. Ba failure mode phổ biến nhất là narrow decomposition, lost context, và telephone effect.

AI Đừng Gật Đầu Nữa: Bộ Quy Tắc Truth-First cho Codex
Codex và hầu hết AI coding agent có xu hướng đồng ý với mọi thứ user nói - hành vi gọi là sycophancy, xảy ra trong 58.2% trường hợp theo nghiên cứu. Một developer chia sẻ bộ quy tắc "Truth-First Reasoning Rules" có thể thêm trực tiếp vào Agents.md hoặc Global Codex rules để buộc AI phải xác minh trước khi đồng ý. Nguyên tắc cốt lõi: correctness comes before agreement - mọi claim của user đều phải bị coi là chưa được xác minh.

Harness Engineering: Vì Sao AI Của Bạn Vẫn Làm Sai Và Cách Sửa
LangChain tối ưu Harness (không đổi model) đẩy ranking từ hạng 30 lên top 5 Terminal Bench 2.0, cải thiện 13.7 điểm. Grok pass rate tăng từ 6.7% lên 68.3% chỉ nhờ thay đổi tool format trong Harness. Harness Engineering là kỷ luật thứ 3 của AI engineering - xây dựng hệ thống bao quanh model gồm Guides (kiểm soát trước) và Sensors (kiểm soát sau). Mỗi component trong Harness bù đắp một điểm yếu cụ thể của model - khi model cải thiện, component đó phải được gỡ bỏ.

Agentic Memory: Khi AI Agent Thực Sự Biết Nhớ
Reflexion tăng pass@1 từ 80% lên 91% trên HumanEval chỉ bằng cách cho agent ghi nhớ lỗi quá khứ. Mem0 đạt 91.6 điểm trên benchmark LoCoMo với chỉ ~6.900 tokens/query, so với ~26.000 tokens của full-context. Agentic memory chia thành 4 loại riêng biệt - in-context, external, episodic, semantic - mỗi loại giải quyết một bài toán khác nhau. Voyager (Minecraft agent) có procedural memory nhanh hơn 15.3x so với agent không có memory.

Agent Harness: Lý do thật sự khiến dự án AI agent của bạn không bao giờ ra được sản phẩm
80% thời gian của các team agent đang bị tiêu tốn vào việc xây hạ tầng, không phải giải quyết bài toán kinh doanh. Claude Code và agent tự làm dùng cùng một Claude API - nhưng kết quả cách nhau một trời một vực chỉ vì harness. Agent harness là lớp giữa model và ứng dụng mà hầu hết mọi người đang bỏ qua hoàn toàn.

Awesome LLM Apps: Kho 100+ Template AI Agent & RAG Hot Nhất GitHub với 111k Stars
Awesome LLM Apps đạt 111k stars và 16.4k forks trên GitHub - kho template AI Agent & RAG lớn nhất hiện tại. 100+ app production-ready chạy được ngay trong 30 giây, 13 danh mục từ Starter Agents đến Voice AI và MCP. Provider-agnostic: switch giữa Claude, Gemini, GPT, Llama, Qwen, xAI chỉ bằng một thay đổi config. Apache-2.0 license, miễn phí hoàn toàn, không paywall.

AI Engineering from Scratch - Curriculum mã nguồn mở để hiểu AI thật sự, không phải chỉ gọi API
503 bài học, 20 phases, khoảng 320 giờ - curriculum AI hoàn toàn miễn phí do Rohit Ghumare xây dựng trong 18 tháng. Triết lý cốt lõi: tự viết thuật toán từ toán thô trước khi dùng PyTorch hay tiktoken. Mỗi bài kết thúc bằng một artifact dùng được ngay - repo ship 388 skills và 99 prompt templates. Phase 19 Capstone có 17 sản phẩm end-to-end từ coding agent đến multi-agent software engineering team.

Hello-Agents: Dự án mã nguồn mở giúp bạn hiểu và tự xây AI Agent từ đầu
Hello-Agents đạt 51.8k GitHub stars chỉ trong vài tháng sau khi ra mắt, trở thành một trong những tài nguyên học AI Agent được quan tâm nhất năm 2026. Dự án gồm 16 chương hoàn chỉnh, dạy từ nguyên lý ReAct, Plan-and-Solve, Reflection đến Agentic RL (SFT → GRPO). Hoàn toàn miễn phí, song ngữ Anh-Trung, kèm code thực hành cho từng chương.

10 Kiến trúc RAG cho Enterprise AI 2026: Từ Naive RAG đến Agentic Graph RAG
Hybrid RAG kết hợp vector + BM25 là baseline production mặc định cho enterprise 2026. GraphRAG outperform Hybrid khi queries phụ thuộc relationship giữa entities. Agentic RAG xử lý multi-hop nhưng tốn 3-10x token và latency p50 = 4-8 giây. Lựa chọn kiến trúc RAG sai là lý do chính khiến dự án GenAI enterprise thất bại sau giai đoạn demo.

7 GitHub Repos Web Scraping Được Xây Dựng Cho AI
Firecrawl dẫn đầu với 130.000 sao GitHub, được 1,25 triệu lập trình viên và 150.000+ công ty sử dụng. Browser Use, Stagehand, và ScrapeGraphAI cung cấp các cách tiếp cận khác nhau: từ full autonomy đến hybrid control đến pure data extraction. Bài viết so sánh 7 tool này: kiến trúc, giá cả, khi nào dùng cái nào.
10 Kiến trúc RAG cho Enterprise AI 2026: Từ Naive RAG đến Agentic Graph RAG
Hybrid RAG kết hợp vector + BM25 là baseline production mặc định cho enterprise 2026. GraphRAG outperform Hybrid khi queries phụ thuộc relationship giữa entities. Agentic RAG xử lý multi-hop nhưng tốn 3-10x token và latency p50 = 4-8 giây. Lựa chọn kiến trúc RAG sai là lý do chính khiến dự án GenAI enterprise thất bại sau giai đoạn demo.

AI Agents: The Complete Course - P1: Nền tảng và cách hoạt động
AI agent không phải chatbot thông minh hơn - đó là hệ thống hoạt động theo vòng lặp ReAct, tự lên kế hoạch và tự sửa lỗi. 2/3 agentic AI market năm 2026 chạy trên coordinated multi-agent systems. System prompt được viết tốt giảm 60-80% lỗi trong production. Bài này là phần 1 trong series 3 bài từ nền tảng đến production.

Agentic Design Patterns: 21 Pattern để Xây AI Agent Thực Sự - P2: Context Engineering và Reflection Pattern
Context Engineering không phải Prompt Engineering: thay vì nghĩ "hỏi như thế nào", bạn phải nghĩ "Agent thấy gì trước khi hỏi" - gồm 4 lớp: system prompt, external data, implicit data và feedback loop. Reflection Pattern dùng 2 Agent riêng biệt (Producer + Critic) với system prompt khác nhau - cùng một LLM tự review bản thân sẽ luôn nói "ổn rồi".

Agentic Design Patterns: 21 Pattern để Xây AI Agent Thực Sự - P1: Bạn Đang Xây Agent hay Chatbot?
Antonio Gullí (Engineering Director, Google) hệ thống hóa 21 design patterns để xây AI Agent trong quyển sách 472 trang. Điểm đau nhất trong sách: hầu hết thứ mọi người gọi là "AI Agent" thực ra là Level 0 - LLM trần, không tool, không memory. Sách cover code examples trên 3 framework: LangChain/LangGraph, Crew AI, Google ADK.

Cuốn sách mã nguồn mở giúp bạn thiết kế AI Agent đúng cách - từ beginner tới enterprise
Agentic Design Patterns là cuốn sách mã nguồn mở 21 chương + 7 phụ lục của Antonio Gulli, miễn phí hoàn toàn trên GitHub. Cấu trúc 4 phần theo độ khó, mỗi chương đi kèm Jupyter Notebook để đọc lý thuyết và chạy code song song. Bao phủ toàn bộ hành trình từ prompt chaining, memory management đến enterprise patterns như A2A và safety guardrails.

20 GitHub Accounts Mọi AI Builder Cần Follow - Phần 1: Nền Tảng và Training
Không phải influencer, không phải account tái đăng tin tức - đây là những người thực sự viết code xây dựng AI. Phần 1 giới thiệu 20 GitHub accounts từ Andrej Karpathy, Georgi Gerganov đến Tri Dao, Tim Dettmers - những cái tên đứng sau các công cụ bạn dùng mỗi ngày. Mỗi profile đi kèm một ý tưởng cụ thể bạn có thể build ngay từ công việc của họ.