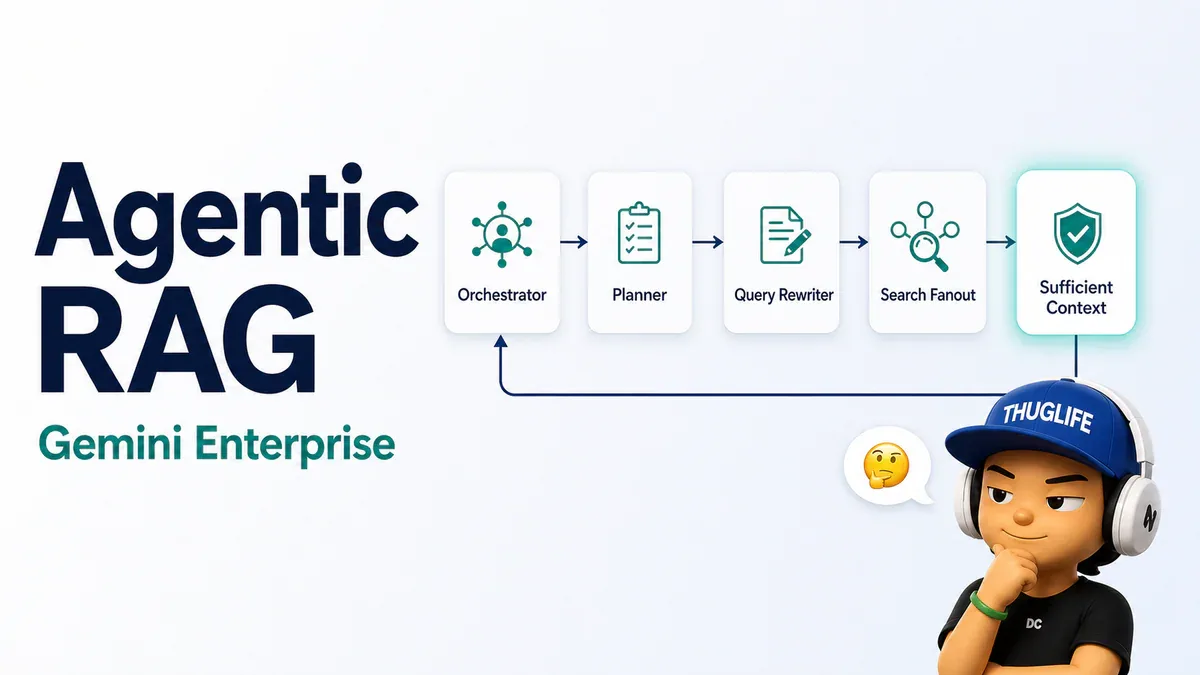
Gemini Enterprise Agentic RAG: khi RAG biết tự đào lại đến khi đủ dữ kiện
Google Research và Google Cloud công bố framework Agentic RAG mới trong Gemini Enterprise Agent Platform, đang ở public preview. Trên FramesQA (824 query, 2,676 PDF), accuracy cải thiện tới 34% so với vanilla RAG. Cross-corpus đạt 90.1% accuracy khi Planner Agent phải chọn đúng 1 trong 4 corpus, latency chỉ chậm hơn single-corpus trong vòng 3%. Điểm khác biệt: Sufficient Context Agent quyết định khi nào dữ liệu đủ và buộc hệ thống search tiếp khi chưa đủ.

Turbovec - Vector Index Xây Dựng Trên TurboQuant Của Google Research
Turbovec là vector index viết Rust dựa trên TurboQuant của Google Research. Nén 10 triệu vectors từ 31 GB xuống 4 GB (tỉ lệ 8x), vẫn nhanh hơn FAISS 12-20% trên ARM. Không cần training phase, hỗ trợ LangChain/LlamaIndex. Mã nguồn mở, hoàn toàn miễn phí.

Lộ trình Vibe Coding 6 tháng - P5: Context Engineering và Model Context Protocol
Tháng 5 là meta-skill tách biệt vibe coder tốt với xuất sắc: context engineering - kỷ luật định hình thông tin nào vào context window của AI. MCP (Model Context Protocol) mở khóa next level: agents kết nối với databases, APIs, Figma, GitHub. Vercel AI SDK, RAG, và quản lý chi phí token.

Xây dựng LLM Architecture từ đầu - Phần 3: Dự án thực tế và 5 cách kiếm tiền với LLM Skills
Senior LLM freelancer kiếm $210/giờ trung bình năm 2026, tăng 45% trong 3 năm. Specialist fine-tuning và RLHF: $350-$700+/giờ. Phần 3 hướng dẫn 6 project nên build đầu tiên, 5 con đường kiếm tiền cụ thể (freelance, SaaS, remote jobs, agency, personal brand) và lộ trình 12 tháng từ zero đến remote engineer.

Xây dựng LLM Architecture từ đầu - Phần 2: Tokenization, Embeddings, Attention và RAG
4 khái niệm kỹ thuật cốt lõi phân biệt người dùng AI và người xây dựng AI: Tokenization, Embeddings, Attention Mechanism và Fine-tuning. Chuyên gia fine-tuning (LoRA, RLHF) đang kiếm $350-$700/giờ freelance 2026. Cộng thêm RAG - kỹ năng sinh tiền nhất để build private AI assistants - và cách deploy lên production thực tế.

PageIndex: Khi RAG Bỏ Hẳn Vector Database Mà Vẫn Đạt 98.7% Accuracy
PageIndex là framework RAG mã nguồn mở của VectifyAI, loại bỏ hoàn toàn vector database và document chunking. Mafin 2.5 - hệ thống phân tích tài chính dùng PageIndex - đạt 98.7% trên FinanceBench, so với ~50% của vector RAG truyền thống. Thay vì tính cosine similarity, PageIndex xây cây phân cấp từ tài liệu rồi dùng LLM lý luận qua cây để truy xuất đúng section. MIT License, 31.5k GitHub stars, hỗ trợ MCP tích hợp trực tiếp vào Claude, Cursor và các AI agent frameworks.

Blockify và IdeaBlocks: Giảm corpus RAG 40x, tăng độ chính xác y tế 261%
Blockify giảm kích thước corpus xuống còn 2.5% kích thước gốc trong khi giữ lại 99% factual integrity. Token tiêu thụ mỗi query giảm 3.09x - từ 1,515 xuống 490 tokens. Độ chính xác vector search tăng 2.29x so với chunking truyền thống. Trong thử nghiệm lâm sàng với Llama 3.2 3B chạy on-device, Blockify cải thiện độ chính xác trung bình 261% và lên đến 650% với trường hợp DKA management.

HelixDB: Kết hợp Graph và Vector Database trong một nền tảng duy nhất cho AI apps
HelixDB là open-source graph-vector database viết bằng Rust, kết hợp semantic search và relationship traversal trong một DB thay vì hai. Benchmark trên AWS cho thấy nhanh hơn Neo4j 16x cho graph lookups và 5.9x cho traversal với dataset 4 triệu edges. YC W25 backed, 4,100+ GitHub stars, license AGPL-3.0, self-hosted miễn phí.

RAG tiến hóa như thế nào: Từ Retrieval đơn giản đến Agentic AI
RAG đã trải qua 6 giai đoạn tiến hóa - từ keyword search thủ công đến Agentic AI tự lên kế hoạch và tự sửa lỗi. Agentic RAG tốn 3-10x token và thêm 2-5x latency, nhưng đáng giá với các tác vụ multi-hop phức tạp, y tế, pháp lý. MCP trở thành chuẩn Linux Foundation tháng 12/2025 - báo hiệu RAG sắp biến thành tầng hạ tầng cốt lõi của mọi ứng dụng AI.

PageIndex: Xuất sắc trong niche của nó - nhưng Twitter đang hype quá mức
PageIndex đạt 98.7% accuracy trên FinanceBench - một benchmark tài chính cực khó - nhờ cách tiếp cận vectorless hoàn toàn mới. Tuy nhiên, bản OSS chỉ thực sự mạnh với 1 tài liệu dài; multi-document cross-folder search đòi hỏi tier Enterprise mới ra mắt. Hype trên Twitter không sai, chỉ thiếu context quan trọng.

Firecrawl Agent: Bỏ Qua Pipeline RAG, Chỉ Cần URL + Câu Hỏi
Firecrawl Agent endpoint cho phép truyền URL + câu hỏi tự nhiên và nhận về grounded answer ngay lập tức - không cần scrape, chunk, embed hay vector DB. Agent chạy với 2 model: spark-1-mini (giảm 60% chi phí) và spark-1-pro cho nghiên cứu phức tạp. Pricing: Free 1,000 credits/tháng; Standard $83/tháng với 100,000 credits và 500 req/min. Đang ở Preview stage với 5 lượt chạy miễn phí mỗi ngày.

Cognee: open-source memory layer đưa AI agents thoát khỏi 'mất trí' sau mỗi session
Cognee thay RAG bằng pipeline ECL (Extract, Cognify, Load) + Memify, biến dữ liệu thành knowledge graph lai vector — chạy trong 6 dòng code, đạt ~90% accuracy so với ~60% của RAG, vừa gọi $7.5M seed.

LLM Wiki: Khi Karpathy dạy AI tích lũy kiến thức thay vì chỉ tra cứu
Ngày 2/4/2026, Andrej Karpathy công bố pattern LLM Wiki - tweet đạt 16 triệu lượt xem, GitHub gist 5.000+ stars trong vài ngày. Pattern này giải quyết điểm mù lớn nhất của RAG: kiến thức biến mất sau mỗi phiên. LLM Wiki biến AI thành công cụ tích lũy tri thức - 1 nguồn có thể cập nhật 10-15 trang wiki liên kết, và wiki của Karpathy đã đạt 100 bài viết, 400.000 từ trên một chủ đề nghiên cứu duy nhất.

LLM Wiki của Karpathy: Khi AI Trở Thành Người Quản Lý Kiến Thức Của Bạn
Ngày 2/4/2026, Andrej Karpathy công bố "LLM Knowledge Bases" - pattern dùng AI xây dựng wiki markdown tự duy trì, đạt 16 triệu views và 5,000 GitHub stars chỉ trong vài ngày. Wiki của ông đạt ~100 bài viết, ~400,000 từ mà không cần tự viết một chữ. Pattern này cắt giảm token consumption lên đến 95% so với RAG thông thường và hoạt động hoàn toàn không cần vector database.

Awesome LLM Apps: Kho 100+ Template AI Agent & RAG Hot Nhất GitHub với 111k Stars
Awesome LLM Apps đạt 111k stars và 16.4k forks trên GitHub - kho template AI Agent & RAG lớn nhất hiện tại. 100+ app production-ready chạy được ngay trong 30 giây, 13 danh mục từ Starter Agents đến Voice AI và MCP. Provider-agnostic: switch giữa Claude, Gemini, GPT, Llama, Qwen, xAI chỉ bằng một thay đổi config. Apache-2.0 license, miễn phí hoàn toàn, không paywall.

Kỷ Nguyên Multi-Agent: Building the Model Không Còn Là Thách Thức Khó Nhất
Agentic RAG tốn 3-10x token và 2-5x latency so với one-pass RAG, đẩy latency p95 lên tới 10-15 giây. Model performance giảm sau 32.000 tokens dù context window có thể lên đến hàng triệu. Tối ưu KV-cache giảm chi phí 10x nhờ tỷ lệ 100:1 input-to-output token. Context engineering đang thay thế prompt engineering làm kỹ năng cốt lõi của AI developer.

10 Kiến trúc RAG cho Enterprise AI 2026: Từ Naive RAG đến Agentic Graph RAG
Hybrid RAG kết hợp vector + BM25 là baseline production mặc định cho enterprise 2026. GraphRAG outperform Hybrid khi queries phụ thuộc relationship giữa entities. Agentic RAG xử lý multi-hop nhưng tốn 3-10x token và latency p50 = 4-8 giây. Lựa chọn kiến trúc RAG sai là lý do chính khiến dự án GenAI enterprise thất bại sau giai đoạn demo.
10 Kiến trúc RAG cho Enterprise AI 2026: Từ Naive RAG đến Agentic Graph RAG
Hybrid RAG kết hợp vector + BM25 là baseline production mặc định cho enterprise 2026. GraphRAG outperform Hybrid khi queries phụ thuộc relationship giữa entities. Agentic RAG xử lý multi-hop nhưng tốn 3-10x token và latency p50 = 4-8 giây. Lựa chọn kiến trúc RAG sai là lý do chính khiến dự án GenAI enterprise thất bại sau giai đoạn demo.

MCP, RAG & Skills: 3 trụ cột context của mọi AI Agent 2026
Ba mảnh ghép không thay thế nhau mà cộng gộp: MCP chuẩn hoá việc gọi tool, RAG nạp kiến thức ngoài training, Skills cắt prompt bloat bằng progressive disclosure. Đây là cách chúng khớp với nhau trong một agent hiện đại.