
- Reflexion tăng pass@1 từ 80% lên 91% trên HumanEval chỉ bằng cách cho agent ghi nhớ lỗi quá khứ.
- Mem0 đạt 91.6 điểm trên benchmark LoCoMo với chỉ ~6.900 tokens/query, so với ~26.000 tokens của full-context.
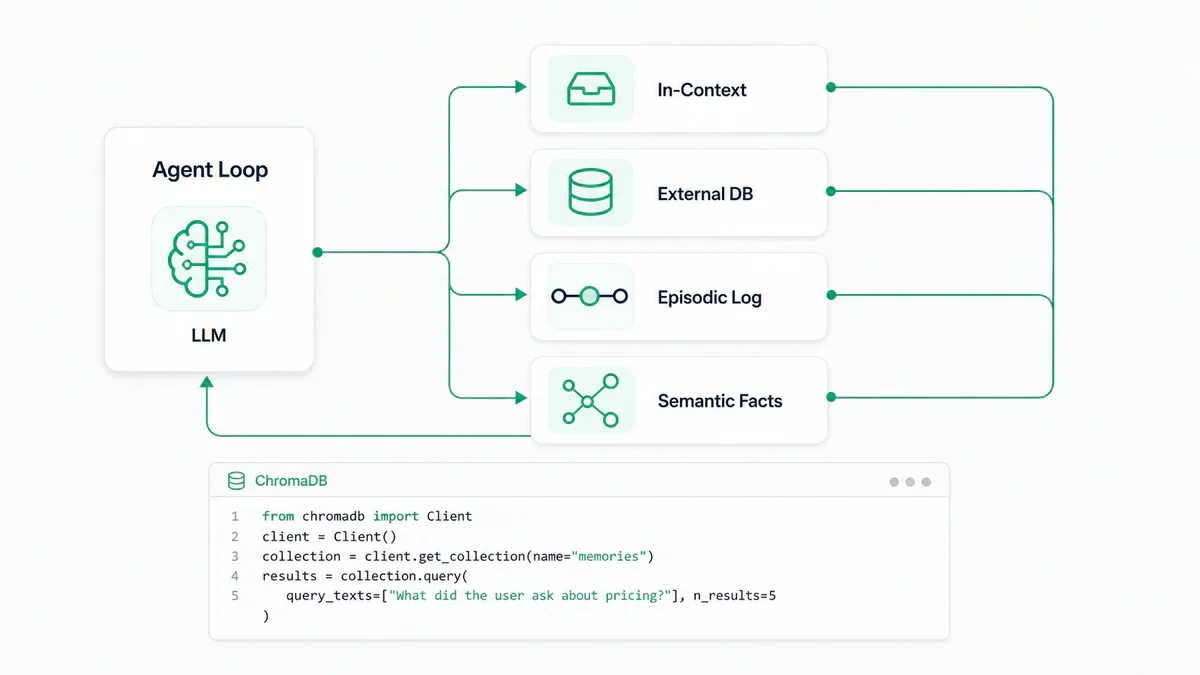
- Agentic memory chia thành 4 loại riêng biệt - in-context, external, episodic, semantic - mỗi loại giải quyết một bài toán khác nhau.
- Voyager (Minecraft agent) có procedural memory nhanh hơn 15.3x so với agent không có memory.
TL;DR
Mọi LLM đều stateless theo mặc định - kết thúc phiên là mất sạch context. Agentic memory giải quyết điều này bằng 4 loại bộ nhớ ngoài: in-context (bàn làm việc tạm thời), external (database bền vững), episodic (log sự kiện quá khứ), và semantic (facts trừu tượng). Kết quả đo được: Reflexion tăng coding pass@1 từ 80% lên 91%, Voyager nhanh hơn 15.3x trong Minecraft, Mem0 tiết kiệm 3.7x chi phí token so với nhét toàn bộ lịch sử vào context. Công cụ đã sẵn cho production ngay hôm nay.
Vấn đề bạn chưa nhận ra
Hãy tưởng tượng bạn thuê một lập trình viên tài năng. Ngày đầu họ làm việc tuyệt vời - bắt được mọi bug, viết docs sạch, gợi ý cải tiến bạn chưa nghĩ ra. Ngày thứ hai bạn hỏi: "Nhớ cái issue hôm qua không?" Họ nhìn bạn. Mỉm cười nhẹ. "Xin lỗi... issue nào?"
Đó chính xác là hành vi của hầu hết LLM. Mỗi conversation mới là một tờ giấy trắng hoàn toàn. Với chatbot đơn giản thì không sao - nhưng với agent chạy task phức tạp, đưa ra quyết định, và cần cải thiện theo thời gian, đây là dealbreaker.
Theo survey về Memory for LLM Agents (2026), thiếu memory khiến agent: rediscover cùng thông tin mỗi phiên, lặp lại đúng lỗi đã gây crash trước đó, và không bao giờ tích lũy được project-specific knowledge.
4 loại bộ nhớ trong AI Agent
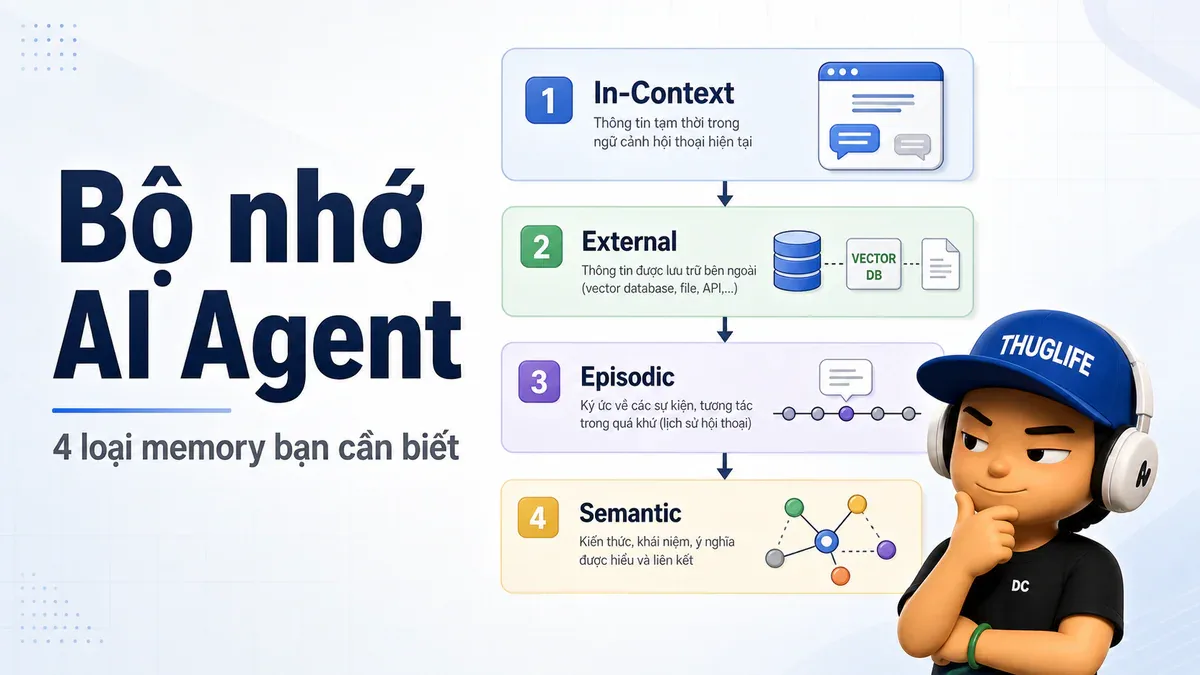
Nghiên cứu đã hội tụ về 4 loại memory riêng biệt, mỗi loại như một vùng não khác nhau với nhiệm vụ cụ thể.
1. In-Context Memory
Đây là bàn làm việc của agent - context window. Mọi thứ trên đó đều accessible ngay lập tức, không cần retrieval. Bao gồm: system prompt, conversation history hiện tại, kết quả tool call, và scratchpad reasoning.
Giới hạn rõ ràng: khi session kết thúc, bàn được dọn sạch. Và khi lịch sử tích lũy quá dài, xảy ra hiện tượng attentional dilution - thông tin ở giữa context bị model "quên" dù vẫn còn trong window ("lost in the middle").
2. External Memory
Mọi thứ tồn tại ngoài model - vector stores, SQL databases, file systems. Tồn tại xuyên session. Có 2 dạng chính:
- Structured Store (PostgreSQL, Redis): query bằng key/ID/SQL, nhanh và deterministic, phù hợp user profiles và structured data
- Vector Store (ChromaDB, Qdrant, pgvector): query theo nghĩa - "tìm ký ức liên quan đến concept này" - cần thiết cho episodic recall và unstructured notes
Điểm cốt lõi: memory architecture là 20% storage, 80% retrieval design. Nếu không lấy được đúng ký ức, agent hành xử như chúng không tồn tại.
3. Episodic Memory
Loại hay bị đánh giá thấp nhất. Trong khi external memory lưu facts, episodic memory lưu sự kiện - cụ thể là outcome của các hành động quá khứ. Mỗi episode là một structured log:
- Task là gì, approach nào dùng, kết quả ra sao
- Chi phí token, duration, quality score
- Embedding vector để semantic search
Khi task mới đến, agent tìm episodes tương tự và dùng làm few-shot learning từ lịch sử cá nhân - thay vì từ dataset được làm thủ công. Đây là nền tảng của Reflexion và ExpeL.
4. Semantic Memory
Bộ nhớ "được sinh ra cùng model" - knowledge encoded trong weights từ training. Luôn available, không cần retrieval. Nhưng frozen tại thời điểm training cutoff, không thể update runtime, và opaque - không biết model "biết" hay không biết điều gì.
Mental model đúng: semantic memory là nền giáo dục của agent. External, episodic, và in-context là kinh nghiệm thực chiến. Agent tốt nhất kết hợp cả hai.
Con số đáng chú ý
- Reflexion: thêm episodic self-critique sau task failure → pass@1 trên HumanEval tăng từ 80% lên 91% (không cần gradient updates)
- Voyager (Minecraft): procedural skill library → 3.3x unique items, 15.3x faster tech-tree vs agent không có memory
- Mem0 2026: LoCoMo benchmark 91.6 điểm, LongMemEval 93.4 điểm, chỉ dùng ~6.900 tokens/query so với ~26.000 tokens full-context - tiết kiệm 3.7x
- MemoryArena: model near-perfect trên LoCoMo lại tụt xuống 40-60% khi task interdependent đa phiên - bằng chứng passive recall không bằng active memory management
- Latency overhead: retrieval pipeline thêm 200-500ms. Lightweight systems (SimpleMem, LOCOMO) <1.1s; MemoryOS phân cấp cứng >32 giây - không khả dụng interactive
Tại sao không chỉ mở rộng context window?
Câu hỏi hợp lý khi model đã có 128k-200k+ token context. Nhưng bằng chứng nói không:
- Attentional dilution: thông tin ở giữa context bị "mất" dù vẫn trong window
- Summarization drift: nén nhiều vòng → mất thông tin hiếm nhưng critical. Ví dụ: instruction "không được gọi production DB trực tiếp" từ ngày đầu có thể biến mất sau 3 lần nén
- Chi phí quadratic: inference cost tăng quadratic với context length
- MemoryArena: active memory agent >80% vs passive long-context baseline ~45% task completion
Traditional RAG (read-only pipeline) tốt hơn pure long-context nhưng vẫn bị contextual drift - cosine similarity có thể trả về fact cũ 5 năm trước vì wording match, dù user vừa update preference 5 phút trước. Agentic memory khắc phục bằng hybrid scoring: 80% semantic similarity + 20% recency decay, kết hợp entity matching.
Ai nên xây memory layer ngay bây giờ
Memory không cần thiết đồng đều. Chatbot dịch thuật một lần không cần; coding assistant làm việc nhiều tuần không thể thiếu. Các domain hưởng lợi rõ nhất:
- Voice agents: người dùng không thể scroll back - nếu agent không nhớ, friction xảy ra ngay lập tức
- Coding companion: lưu architecture decisions, bug history, team conventions - không rediscover mỗi Monday
- Multi-agent enterprise: shared memory là coordination mechanism - ChatDev, MetaGPT dùng shared docs để giữ project coherent qua nhiều agent
- Customer support/CRM: recall return eligibility, medical history, preference qua nhiều phiên
- Scientific R&D: hypothesis ledger + evidence accumulator với uncertainty tracking
Kết - công cụ có thể dùng ngay
Hệ sinh thái đã đủ trưởng thành để bắt đầu production ngay hôm nay:
- Mem0: managed cloud (free tier tại app.mem0.ai) hoặc self-host Docker <20 phút. Hỗ trợ 21 framework, 20 vector stores
- LangMem: open-source Python, tích hợp tự nhiên với LangChain/LangGraph
- OpenMemory MCP: local-first, chạy trên Claude Desktop/Cursor/Windsurf, <5 phút setup
- pgvector: nếu đã có PostgreSQL, thêm vector search mà không cần infra mới
Roadmap nghiên cứu tiếp theo: causally grounded retrieval ("cái gì gây ra" thay vì "cái gì trông giống"), memory consolidation kiểu sleep cycle, multimodal memory cho robotics, và foundation model chuyên biệt cho memory management.
Memory là thứ biến stateless text generator thành partner thực sự tiến hóa theo thời gian. Xây memory layer đúng, và mọi thứ còn lại trở nên thông minh hơn.
via Memory for Autonomous LLM Agents (2026) · Anatomy of Agentic Memory · State of AI Agent Memory 2026
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ