
- TencentDB Agent Memory là hệ thống open-source (MIT) từ Tencent, giải quyết vấn đề agent mất ngữ cảnh qua kiến trúc 4 tầng tiến trình.
- Token tiêu thụ giảm 61.38% trên WideSearch benchmark.
- Persona coherence tăng từ 48% lên 76% trên PersonaMem.
- Chạy hoàn toàn local, không phụ thuộc external API.
TL;DR
Sau 6 tháng nghiên cứu, nhóm kỹ sư TencentDB đã open-source một hệ thống bộ nhớ cho AI Agent: TencentDB Agent Memory. Hệ thống này giải quyết vấn đề agent mất ngữ cảnh trong các session dài bằng kiến trúc 4 tầng kết hợp với Mermaid Canvas - một dạng bản đồ tác vụ symbolic giúp agent không bao giờ "quên" mình đang làm gì. Kết quả đo được: token tiêu thụ giảm 61.38%, tỉ lệ thành công tăng 51.52%, persona coherence tăng từ 48% lên 76%.
Vấn đề: AI Agent quên chính nó trong session dài
Bất kỳ ai đang xây dựng AI Agent đều biết vấn đề này: agent hoạt động tốt trong 5-10 bước đầu, nhưng khi workflow kéo dài tới 30+ bước, nó bắt đầu lặp lại câu hỏi, quên tool convention đã thỏa thuận, hoặc đổi tone giữa chừng.
Vấn đề không phải là context window quá ngắn - mà là cách quản lý bộ nhớ hiện tại quá thụ động. Phần lớn hệ thống hiện tại hoặc nhồi toàn bộ lịch sử vào context, hoặc dựa vào LLM tự quyết định nén thông tin - cả hai đều dẫn đến mất dữ liệu không thể phục hồi.
Tencent dành 6 tháng để giải quyết đúng vấn đề đó, và kết quả là TencentDB Agent Memory - một hệ thống bộ nhớ 4 tầng chạy hoàn toàn local, không cần external API.
Kiến trúc 4 tầng - từ raw log đến persona
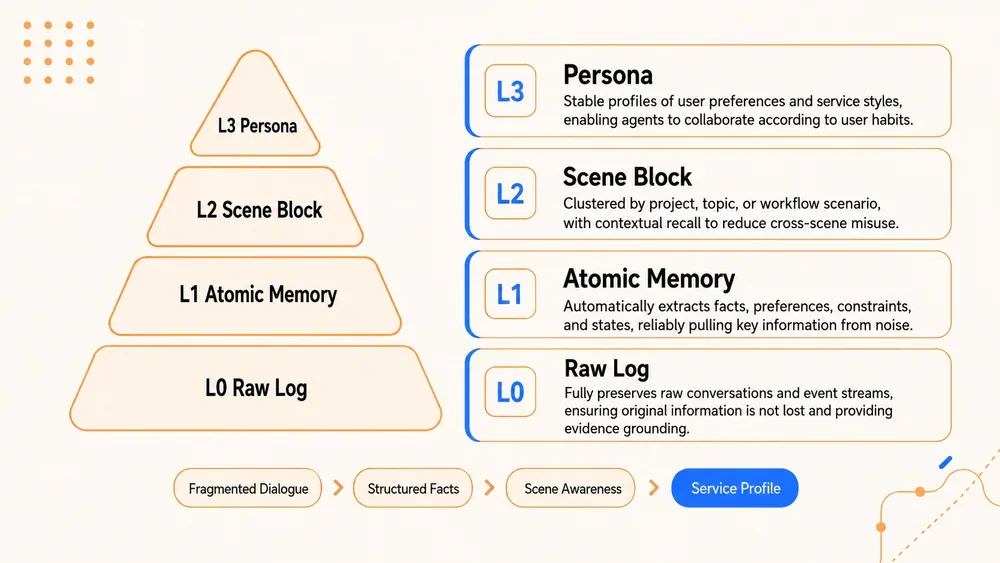
Hệ thống xây dựng một tháp ngữ nghĩa gồm 4 tầng:
- L0 Raw Log - lưu toàn bộ cuộc hội thoại và execution trace gốc, không mất mát
- L1 Atomic Memory - LLM trích xuất atomic facts, preferences, và constraints từ L0
- L2 Scene Block - nhóm facts thành scene blocks theo project/topic/workflow
- L3 Persona - tổng hợp profile người dùng ổn định: phong cách làm việc, ngôn ngữ ưa thích, reusable skills
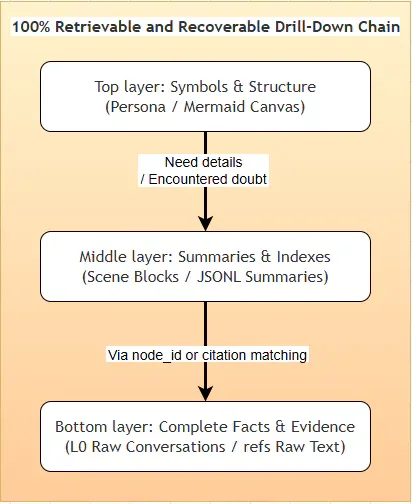
Song song đó, hệ thống có Symbolic Short-Term Memory dưới dạng Mermaid Canvas. Thay vì nhồi toàn bộ tool log vào context, nó offload nội dung verbose sang file refs/*.md bên ngoài, chỉ giữ lại một graph Mermaid nhỏ trong context window. Agent có thể drill-down vào bất kỳ node nào khi cần - tương tự như bản đồ có chỉ dẫn chi tiết.
Điểm đặc biệt: khác với các hệ thống nén không thể phục hồi, TencentDB duy trì một chuỗi drill-down xác định: L3 Persona → L2 Scene → L1 Atom → L0 Raw. Không có thông tin nào bị mất vĩnh viễn.
Con số benchmark đáng chú ý
Kết quả đo trên các benchmark cụ thể:
- WideSearch: task success 33% → 50% (+51.52%), token tiêu thụ 221.31M → 85.64M (-61.38%)
- SWE-bench (50 task liên tiếp): success 58.4% → 64.2% (+9.93%), token 3,474.1M → 2,375.4M (-33.09%)
- AA-LCR: success 44.0% → 47.5% (+7.95%), token 112.0M → 77.3M (-30.98%)
- PersonaMem: accuracy 48% → 76% (+59% relative)
Retrieval sử dụng hybrid search: 70% vector (semantic similarity) + 30% BM25 (keyword matching), fused qua RRF (Reciprocal Rank Fusion).
So sánh với Mem0 và cách bắt đầu
Nếu đã dùng Mem0 - đối thủ chính trong không gian agent memory - điểm khác biệt lớn nhất là triết lý thiết kế:
- Mem0 thiên về framework-agnostic: hỗ trợ 21 framework (LangChain, LangGraph, CrewAI, AutoGen...), 20 vector store backends, có managed cloud. Thế mạnh là tích hợp rộng và production-ready ở scale lớn.
- TencentDB Agent Memory thiên về local-first và lossless: không cần external API, full traceability từ Persona về Raw, white-box debugging qua Markdown. Phù hợp khi cần kiểm soát hoàn toàn dữ liệu hoặc môi trường air-gapped.
Cài đặt đơn giản qua npm (OpenClaw >= 2026.3.13, Node.js >= 22.16.0). Repo có sẵn trên GitHub với MIT license, hiện ở v0.3.4 với 1.3k stars.
Ai nên dùng ngay
Hệ thống phù hợp nhất với những ai:
- Xây dựng coding assistant cần nhớ team conventions, tool setup, coding patterns qua nhiều session mà không phải giải thích lại từ đầu
- Chạy workflow dài hơn 30 bước nơi agent cần biết chính xác mình đang ở bước nào và bước tiếp theo là gì
- Cần local-first vì lý do compliance, privacy, hoặc môi trường không có internet
- Đang gặp vấn đề persona inconsistency - agent đổi tone, đổi cách xưng hô giữa chừng trong session dài
Nếu cần hỗ trợ nhiều framework hoặc đang scale ở môi trường production lớn, Mem0 vẫn là lựa chọn thực tế hơn ở thời điểm này.
Kết - Bài toán thật sự của agent memory
Tencent sau 6 tháng kết luận: vấn đề của agent memory không phải là lưu nhiều hơn, mà là nhớ đúng thứ, vào đúng lúc, theo đúng cách. Chỉ tăng context window hay dùng vector store không giải quyết được điều đó - cần cả cấu trúc phân tầng lẫn cơ chế drill-down xác định.
Roadmap còn khá nhiều thứ đang chờ: portable memory (cross-agent/cross-framework), automatic skill generation, và visual debugging dashboard. Dự án còn trẻ (repo 1 tháng, v0.3.4), nhưng đà phát triển nhanh và benchmarks thực tế đủ thuyết phục để thử.
GitHub repo: Tencent/TencentDB-Agent-Memory - via @TencentAI_News
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ