
- Memory là điểm hợp nhất giữa model và harness - không phải chỉ là dữ liệu.
- Claude Code, Codex (OpenAI) và Hermes (Nous Research) dùng ba kiến trúc hoàn toàn khác nhau, khiến memory không thể chuyển giữa các agent chỉ bằng cách copy file.
- Vector database đã thua - người thắng là “ LLM + markdown + filesystem tools “
TL;DR
Có ba agent đang chạy song song trên cùng một máy: Claude Code, Codex CLI và Hermes. Cùng file, cùng bash, cùng workstation.
Nhưng khi chuyển từ agent này sang agent kia, feedback rules và memory không "bắt" theo nhau.
Lý do sâu xa: model được post-train trên harness cụ thể của nó. Claude "biết" cách đọc MEMORY.md theo kiểu Claude Code. GPT-5 "biết" cách đọc memory theo kiểu Codex.
Copy file sang agent khác - bytes đến nơi, nhưng behavior khác hoàn toàn. Đây không phải vấn đề config. Đây là kiến trúc.
Và điều bất ngờ nhất sau khi đọc source code của cả ba: mọi kiến trúc "thông minh" đều thua.
Vector database, semantic search, knowledge graph - tất cả đều thất bại trong production.
Thứ thắng là: LLM + markdown + filesystem tools.
Khi memory không chịu "chuyển nhà"
Vấn đề bắt đầu từ một quan sát đơn giản: feedback rules được dạy dỗ qua hàng trăm session với Claude Code - những file markdown nhỏ sống trong ~/.claude/projects/<encoded-cwd>/memory/ - không có tác dụng tương tự khi chuyển sang Codex. Và ngược lại.
Nguyên nhân: trong quá trình post-training, mỗi model được huấn luyện với chính harness của nó.
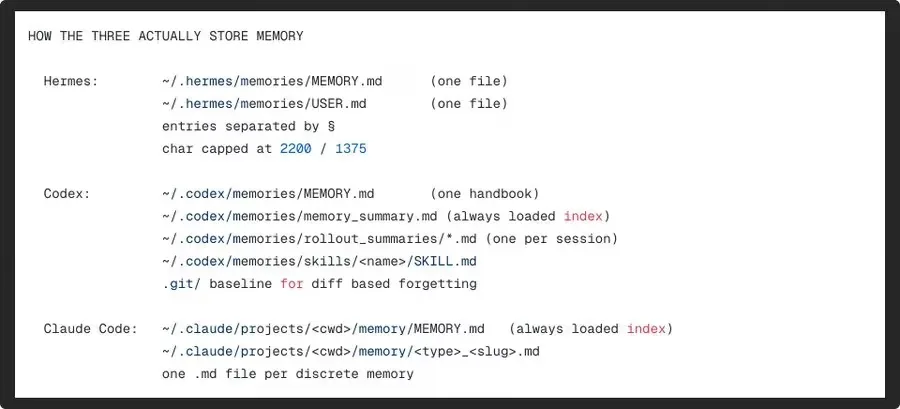
Claude Code có file taxonomy kiểu typed (user/feedback/project/reference), index MEMORY.md luôn được load, và mỗi lần đọc memory body đều có age-aware reminder.
Codex có memory_summary.md luôn load ở đầu, on-demand grep vào MEMORY.md đầy đủ, và tag <oai-mem-citation> để đánh dấu memory nào được dùng.
Kết quả: switching giữa agents không phải là copy file. Đó là switching harness. Và switching cost tích lũy theo từng session.
Ba kiến trúc, ba cách đặt cược
Khi đọc source code của cả ba implementation, ba hướng tiếp cận hiện ra rõ ràng:
Hermes (Nous Research - Python, open source hoàn toàn) đặt cược vào sự đơn giản và prefix cache stability. Hai file flat với dấu phân cách § (section sign - hiếm gặp trong văn bản thông thường). Hard cap: 2200 chars cho MEMORY.md, 1375 chars cho USER.md. Snapshot bị đóng băng ngay khi session bắt đầu - mọi thao tác write trong session cập nhật disk nhưng không thay đổi system prompt. Memory mới chỉ visible ở session tiếp theo.
Codex (OpenAI - Rust, open source) đặt cược vào pipeline offline nặng, live turn rẻ. Sau khi session idle 6 giờ trở lên, một pipeline hai pha kích hoạt: Phase 1 dùng gpt-5.4-mini (low reasoning effort) đọc toàn bộ transcript và extract raw memory - mặc định output là rỗng (chỉ viết khi thực sự đáng lưu). Phase 2 dùng gpt-5.4 chạy như sub-agent sandboxed, edit canonical MEMORY.md. Session tiếp theo chỉ thấy memory_summary.md (giới hạn 5K tokens). Decay tự động: 30 ngày không được cite thì bị xóa.
Claude Code (Anthropic - closed binary) đặt cược vào user oversight. Memory được viết ngay trong live turn, bởi chính live agent, qua cùng Write và Edit tools dùng cho code. MEMORY.md index luôn trong system prompt mỗi turn, body đọc on-demand. Không có decay tự động - thay vào đó, mỗi lần đọc memory body đều kèm theo reminder về tuổi của file tính theo ngày, buộc agent phải verify trước khi assert.

Vì sao vector database thua
Hai năm trước, mọi startup memory đều pitch cùng một ý tưởng: vector database + semantic search + background memory agent.
Kết quả: đủ tốt để demo, không đủ tốt để ai dùng lâu dài.
Lý do rất cụ thể: embeddings có tính lossy. Semantic similarity trên các chuỗi fact ngắn rất nhiễu - retrieval hay miss thứ hiển nhiên và trả về thứ không liên quan.
Background agent không biết khi nào nên fire. Chi phí chạy embedding model mỗi turn cộng dồn. Và debugging gần như không thể vì store không trong suốt.
Thứ đang thắng trong production: không có bespoke infrastructure nào cả. Agent có Read tool, Write tool, Edit tool, bash tool - và dùng chúng để đọc viết markdown file như một người thật. Câu hỏi quan trọng không phải là "dùng data structure nào" mà là "agent tuân thủ kỷ luật gì khi đọc và viết."
Những con số đáng nhớ
Để hiểu tại sao các architectural choices này quan trọng, cần nhìn vào economics của prompt cache:
Anthropic cache hit rẻ hơn khoảng 10 lần so với uncached. Muốn cache hoạt động, system prompt phải byte-for-byte giống nhau giữa các turns.
Một session 50 turns với 22K-token system prompt thay đổi mỗi turn = gấp 10 lần chi phí. Đây là lý do Hermes freeze snapshot và Codex không write memory trong live turn.
LangChain chạy thí nghiệm: giữ nguyên model, chỉ thay harness - benchmark nhảy từ 52.8% lên 66.5%, từ ngoài top 30 lên top 5. Zero thay đổi model.
Codex dùng extraction prompt 570 dòng chỉ để dạy model cách phân biệt memory đáng lưu và noise. Consolidation prompt 841 dòng.
Claude Code: 200 dòng đầu hoặc 25KB của MEMORY.md được load tự động mỗi session. Body của từng file chỉ đọc khi cần.
Ai nên quan tâm đến điều này
Nếu bạn dùng Claude Code hoặc Codex hàng ngày: hiểu harness lock-in giúp bạn không mất công build memory ở một agent rồi kỳ vọng nó tự động hoạt động ở agent khác.
Nếu bạn đang build AI product: memory là nơi tạo ra moat thực sự. Một agent nhớ preferences của từng user tích lũy proprietary dataset theo thời gian. Không có memory, agent của bạn bị replicate dễ dàng bởi bất kỳ ai có cùng tool. Nhưng cẩn thận: nếu dùng closed harness behind API (Claude Managed Agents, Codex's encrypted summaries), user không sở hữu memory đó.
Nếu bạn đang design agent infrastructure: năm câu hỏi cốt lõi - write path (khi nào/ai/ở đâu?), load path (always-loaded hay on-demand?), verification discipline (hint hay authority?), signal gate (mặc định có lưu không?), eviction (decay hay manual?).
Vấn đề chưa ai giải được
Cold start vẫn là bài toán mở nhất: không có agent nào tự seeding memory từ dữ liệu hiện có của user (email, calendar, cloud drive, git history). Ba hệ thống đều bắt đầu từ file trống.
Cross-project scoping cũng chưa hoàn chỉnh: Codex dùng global folder với annotations có nguy cơ leakage, Claude Code encode cwd nhưng không có global overlay, Hermes dùng isolated profiles nhưng không có inheritance.
Và câu hỏi lớn nhất còn chưa có đáp án: khi agent trở thành long-running service tích lũy kiến thức về codebase và workflow của bạn - ai sở hữu dataset đó? User, platform hay model provider? Model providers đang có mọi động lực để đẩy memory layer vào closed API. Và họ đang làm điều đó.
Via: The New Stack, LangChain Blog, Claude Code Docs, Hermes Agent GitHub.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ