
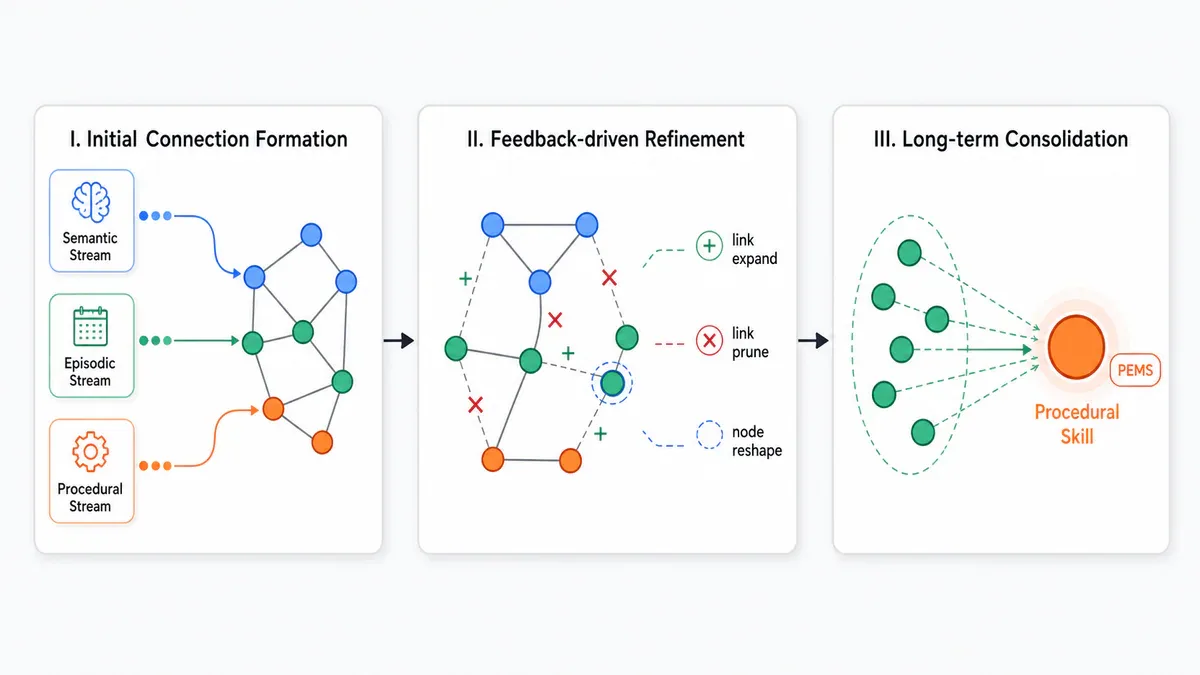
- FluxMem mô hình hóa bộ nhớ agent thành một heterogeneous graph có thể tự chỉnh sửa qua 3 giai đoạn.
- Trên LoCoMo, framework đạt 95.06 LMJ với GPT-4.1-mini, vượt EverMemOS (93.05) và Full Context (81.23).
- Trên GAIA với Kimi K2, success rate nhảy từ 52.12 lên 64.85, tăng tuyệt đối 12.73 điểm.
- Trên Mind2Web realistic, Cross-Task SR đạt 8.1 - hơn gấp đôi AWM (3.6).
TL;DR
Nhóm Zhejiang University, Alibaba Group, MemTensor và Tongji University vừa công bố FluxMem trên arXiv (27/05/2026, ID 2605.28773), đề xuất coi bộ nhớ của LLM Agent là một heterogeneous graph tự chỉnh sửa thay vì kho lưu trữ tĩnh. Framework dùng feedback từ execution để thêm/cắt liên kết theo thời gian thực, đồng thời chưng cất trajectory thành procedural skill có thể tái dùng. FluxMem set state-of-the-art trên cả 3 benchmark LoCoMo, Mind2Web và GAIA, code dự kiến open-source tại repo zjunlp/LightMem.
Tại sao bộ nhớ tĩnh đang ghìm chân LLM Agent
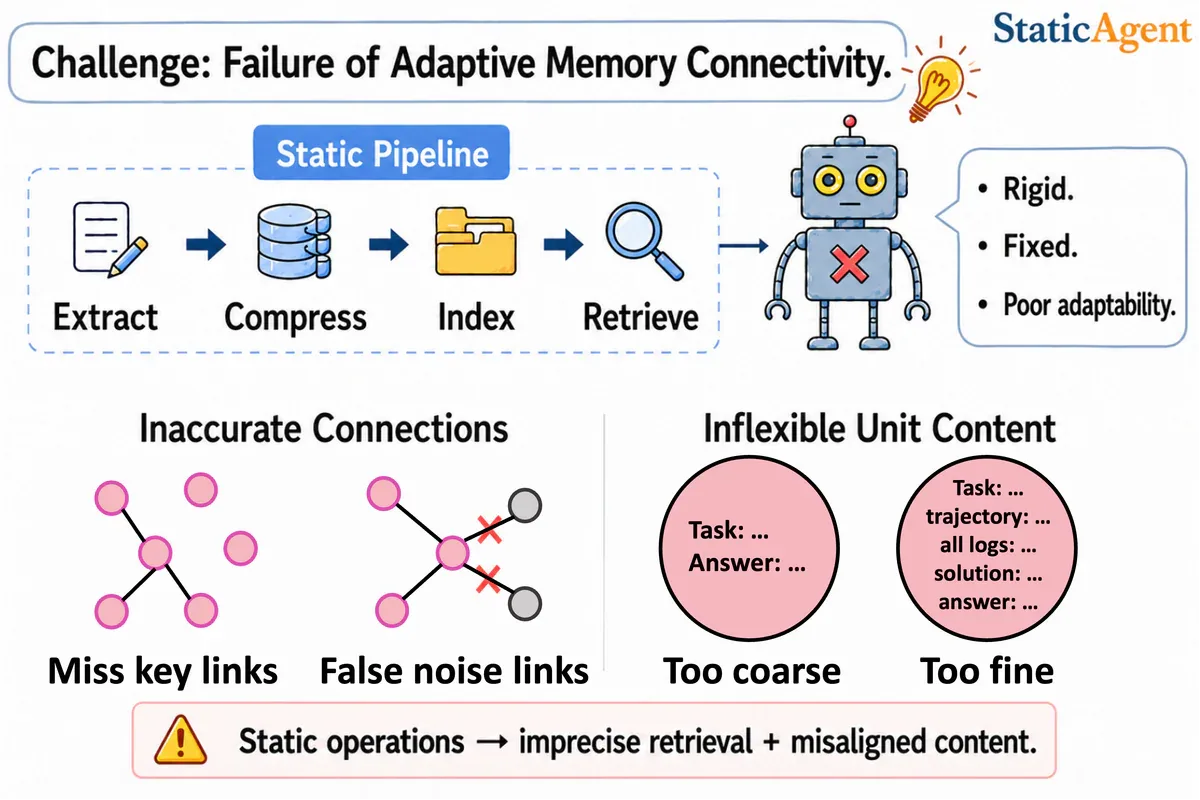
Hầu hết các memory system hiện tại - Mem0, Zep, A-Mem, MemoryOS, LightMem, MIRIX, EverMemOS - đều dùng pipeline hand-crafted với representation cố định và retrieval cứng. Trong môi trường agentic động, paper chỉ ra hai bottleneck cấu trúc.
Thứ nhất là inaccurate memory connection. Retrieval imprecision dẫn tới under-connection (mất context quan trọng vì thiếu link) hoặc over-connection (kéo thêm liên kết noise gây hallucination). Thứ hai là inflexible memory unit content: mỗi memory unit bị fix sẵn một mức abstraction. Quá coarse thì mất chi tiết execution, quá fine thì che mất pattern high-level.
FluxMem xử lý cả hai bằng cách biến chính topology của graph thành đối tượng học tập, refine từng node và edge dựa trên environment signal hoặc self-verification.
Ba lớp memory trong heterogeneous graph
FluxMem mô hình hóa memory là graph G = (V, E) với V gồm ba lớp chức năng:
- Semantic Knowledge (V_sem): fact tĩnh - tài liệu kiến thức, dialogue history, tool API documentation. Lớp này lấy thẳng từ environment.
- Episodic Experiences (V_epi): trajectory state-action chi tiết của từng task, ví dụ tool-use sequence hay debugging log. Mỗi node là một task riêng. Đây được tác giả gọi là operational nexus kết nối semantic và procedural.
- Procedural Skills (V_proc): reasoning template và multi-step planning heuristic được chưng cất từ nhiều episode tương tự, có thể guide cho task tương lai.
Ba lớp nối với nhau qua hai loại edge: E_ground nối semantic vào episodic (fact nào hỗ trợ step nào), và E_distill nối episodic lên procedural (skill nào sinh ra từ trajectory nào).
Ba giai đoạn tiến hóa
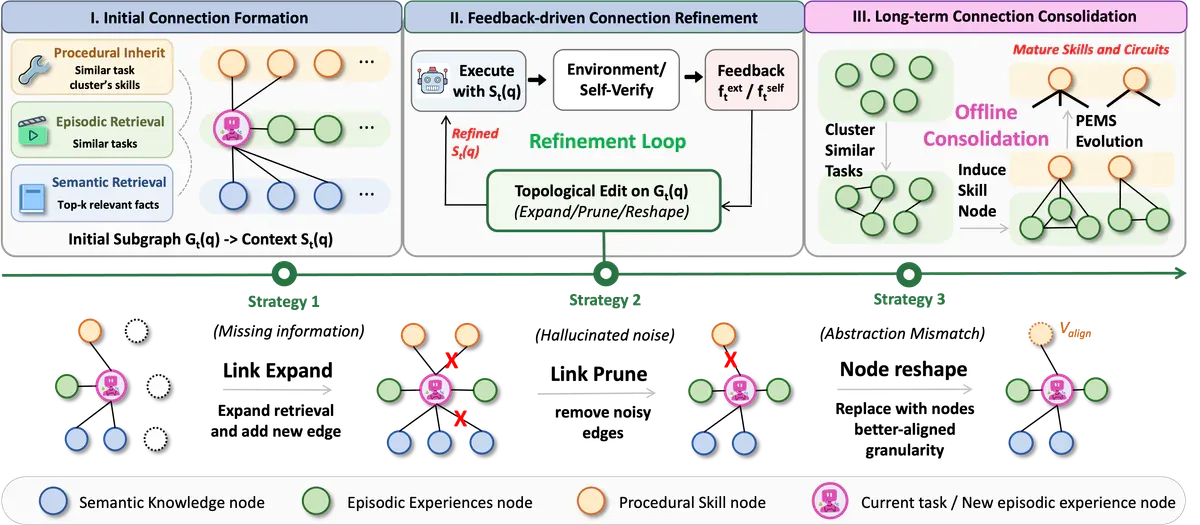
Tại mỗi step t của task q, FluxMem build context S_t(q) như một local subgraph G_t(q). Subgraph này được tinh chỉnh qua ba stage liên tiếp - hai stage chạy online từng step, stage cuối chạy offline theo batch.
Stage I - Initial Connection Formation
Retrieve nhanh để dựng subgraph khởi đầu. Semantic layer dùng hybrid score gồm embedding similarity, BM25 và LLM verification để chọn top-k node. Episodic layer chấm bằng cosine similarity. Procedural layer thì inherit: lấy mọi skill node đã từng link với các episode vừa retrieve qua E_distill. Toàn bộ được serialize thành context S_t cho LLM xử lý.
Stage II - Feedback-driven Refinement
Đây là vòng lặp closed-loop quan trọng nhất. Khi nhận feedback f_t (environment error hoặc self-verify), agent attribute lỗi về một trong ba loại flaw rồi áp một trong ba topological edit:
- Link Expansion: nếu thiếu context, hệ thống tìm node ngữ nghĩa gần đó nhưng chưa activate, thêm edge mới về task-anchor v_t.
- Link Pruning: nếu context bị congestion hoặc xuất hiện hallucinated guidance, cắt distractor edge để isolate v_t khỏi liên kết irrelevant.
- Node Reshape: nếu abstraction sai granularity, LLM rewrite nội dung node v_old thành v_align - mở rộng chi tiết execution hoặc abstract bớt redundancy - vẫn giữ nguyên các edge đã có.
Loop terminate khi execution thành công hoặc đủ T round refinement.
Stage III - Long-term Consolidation
Sau khi task xong, trajectory được commit thành episodic node. Offline, FluxMem cluster các episode theo cosine distance trên embedding trajectory, mỗi cluster được LLM induction operator chưng cất thành một procedural skill node mới.
Để skill không bị invalid, paper đề xuất metric PEMS (Procedure Evolution Maturity Score):
PEMS = (success_rate / log(token_length)) * (1 - embedding_drift)Hệ thống re-run source episode với skill mới, tính PEMS, rồi LLM rewrite skill thấp điểm để fix lỗi logic hoặc cắt phần redundant. Cycle test-score-refine lặp tới khi ΔPEMS < ε. Khi skill maturity đủ cao, task lặp lại có thể bypass retrieval và activate thẳng subgraph mature.
Kết quả: SOTA trên cả ba benchmark
Paper test FluxMem trên ba scenario rất khác nhau để đo generalization, đều ra SOTA.
LoCoMo (long-context conversational reasoning): với backbone GPT-4.1-mini, FluxMem đạt 95.06 điểm LMJ trung bình, vượt EverMemOS (93.05), MIRIX (85.38), LightMem (82.40) và baseline Full Context (81.23). Khi dùng Qwen3-30B-A3B-2507-Instruct, FluxMem vẫn giữ 93.44 trong khi next-best chỉ đạt 74.87.
Mind2Web (realistic web navigation, không filter HTML thủ công): Cross-Task Success Rate đạt 8.1 với GPT-4.1-mini và 9.6 với Gemini-2.5-flash. Baseline AWM (Agent Workflow Memory) chỉ đạt lần lượt 3.6 và 5.6. Dataset có 2350 task, 137 website, 31 domain, trung bình 1135 DOM element/page và 7.3 action/task.
GAIA (generalist assistant, 165 task qua 3 level):
- Kimi K2: 52.12 (Flash-Searcher baseline) -> 64.85, tăng tuyệt đối 12.73 điểm.
- GPT-5-mini: 69.09 -> 76.36, tăng 7.27 điểm. Level-3 đạt 53.85, sánh ngang nhiều closed-source agent framework lớn.
- DeepSeek V3.2: 60.61 -> 70.30, tăng 9.69 điểm.
Trên cả ba backbone, FluxMem cũng vượt MemEvolve - một baseline self-evolving meta-learning rất mạnh ra cuối 2025.
Ablation: stage nào đóng góp nhiều nhất
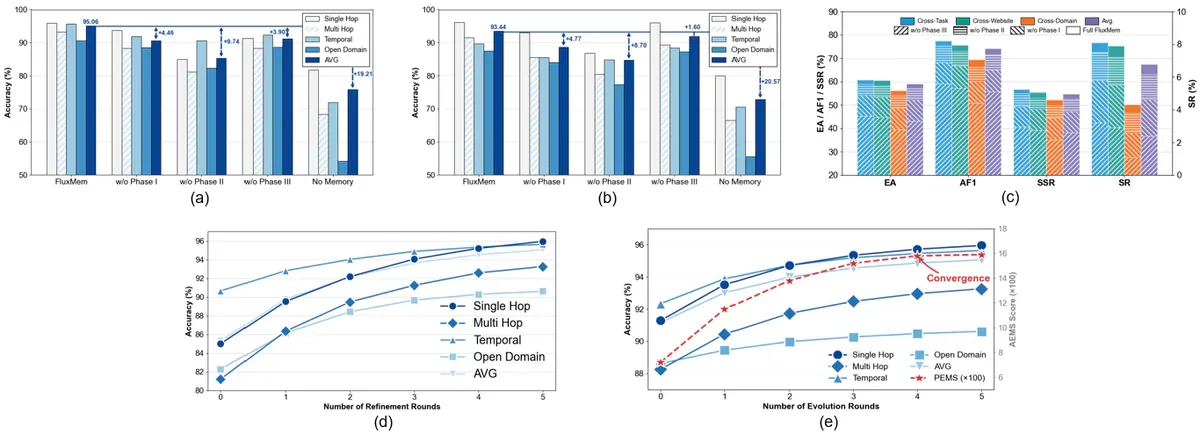
Ablation hé lộ chuyện thú vị: tầm quan trọng của stage phụ thuộc bản chất task.
- LoCoMo memory-centric: bỏ Stage II khiến điểm GPT-4.1-mini drop từ 95.06 xuống 85.32. Recall fact mới là chìa khóa, refinement semantic layer giúp nhiều nhất.
- Mind2Web web-navigation: bỏ Stage III khiến SR sub-category đầu tiên rớt từ 8.1 xuống 3.2. Skill distillation và evolution mới là yếu tố sống còn cho reasoning multi-step.
Hàm ý: cùng một framework, đóng góp của các stage chuyển đổi linh hoạt theo workload - đúng tinh thần adaptive memory.
Case study: xếp hạng country với medals/athlete trong GAIA
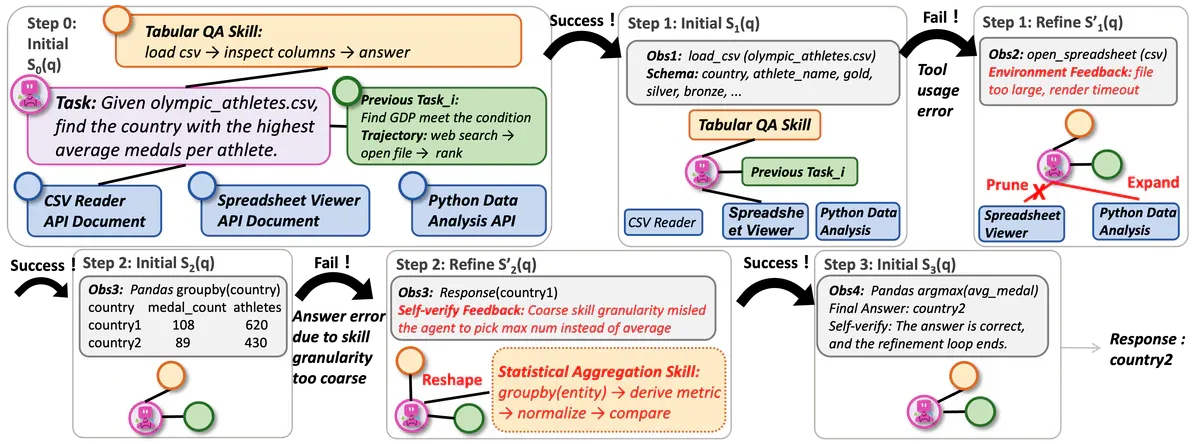
Case study GAIA cho thấy ba topological edit phối hợp trên một task duy nhất. Task: từ olympic_athletes.csv tìm quốc gia có trung bình huy chương/vận động viên cao nhất.
Step 0 init subgraph với Tabular QA skill (coarse) và 3 semantic node API doc. Step 1 load CSV thành công. Step 2 agent gọi nhầm Spreadsheet Viewer API để aggregate, environment trả lỗi render timeout. FluxMem attribute lỗi về connection: prune edge tới Spreadsheet Viewer, expand sang Python Data Analysis. Step 3 chạy groupby(country) ra kết quả nhưng self-verify phát hiện skill quá coarse - đếm max medal thay vì avg. Reshape Tabular QA thành Statistical Aggregation skill (groupby - derive metric - normalize - compare). Step 4 cho ra đáp án đúng country2.
Những gì paper chưa nói
Tác giả thẳng thắn liệt kê limitation. Chi phí tính toán: Stage II và III gọi LLM lặp đi lặp lại, paper không đo latency, API cost hay token consumption - những thứ critical cho production realtime. Benchmark tĩnh: cả ba dataset đều pre-collected, chưa simulate streaming environment với memory decay thật sự. Hyperparameter sensitivity: T (refinement round), ε (PEMS convergence) và top-k chưa được sweep rộng. Offline scheduling: Stage III chạy batch periodic, chưa có dynamic scheduling cho deployment lifelong.
Một chi tiết đáng chú ý cho cộng đồng: code sẽ release ngay tại repo zjunlp/LightMem - cùng repo với LightMem (2025) của chính nhóm, vốn được dùng làm một baseline LoCoMo trong paper này.
Tóm lại
FluxMem dịch chuyển memory từ "kho tĩnh để retrieve" sang "substrate connectivity tự tối ưu". Three-layer graph cộng với feedback loop và PEMS-guided consolidation cho phép agent vừa fix lỗi tức thì, vừa tích lũy skill bền vững. Nếu bạn đang build lifelong agent cho web automation, enterprise assistant hay long-term chatbot, đây là một trong những baseline đáng theo dõi nhất hiện tại - đặc biệt khi repo release. via arXiv 2605.28773
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ