
- Opus 4.7 dẫn đầu code chất lượng với SWE-bench Pro 64.3%, cách đối thủ 10 điểm.
- Kimi K2.6 chạy 300 agent song song với chi phí chỉ $0.30/run - rẻ hơn Opus 3.6 lần.
- GPT-5.5 thống trị Terminal-Bench 82.7% và web research BrowseComp 90.1%.
- Smart routing 3 model này giảm 88% chi phí API - từ $495 xuống dưới $60/tháng.
TL;DR
Ba model mạnh nhất thị trường ra mắt trong 7 ngày - Claude Opus 4.7 (16/4), Kimi K2.6 (20/4), GPT-5.5 (23/4). Mỗi model có thế mạnh hoàn toàn khác nhau. Người chiến thắng không phải kẻ trung thành với một model - mà là kẻ biết route đúng task đến đúng model và tiết kiệm 88% chi phí API mà chất lượng không giảm.

Ba model trong 7 ngày
Tuần từ 16 đến 23/4/2026 là tuần hiếm thấy trong lịch sử AI: ba ông lớn cùng ra mắt flagship model trong vòng một tuần.
Claude Opus 4.7 (16/4): Anthropic ra model bridge cho production coding agent. Điểm nổi bật - SWE-bench Pro nhảy 10 điểm lên 64.3%, tool use dẫn đầu thị trường (MCP-Atlas 77.3%), độ phân giải vision tăng 3x lên 3.75 megapixels.
Kimi K2.6 (20/4): Moonshot AI tung open-weight 1 nghìn tỷ tham số (32B active/token). Điểm đặc biệt - Agent Swarm 300 sub-agent, 4.000 bước song song, chạy tự động 12 giờ liên tục không cần can thiệp. Giá rẻ hơn Opus 4.7 khoảng 5-6 lần.
GPT-5.5 (23/4): Base model được retrain toàn bộ đầu tiên của OpenAI kể từ GPT-4.5. Dẫn đầu Intelligence Index tổng thể (60 điểm), thống trị Terminal-Bench 2.0 (82.7%) và web research BrowseComp (90.1% với Pro).
Kimi K2.6 - worker của swarm
Kimi K2.6 không cạnh tranh bằng điểm benchmark thuần túy - nó cạnh tranh bằng khả năng xử lý khối lượng lớn với giá thấp nhất thị trường.
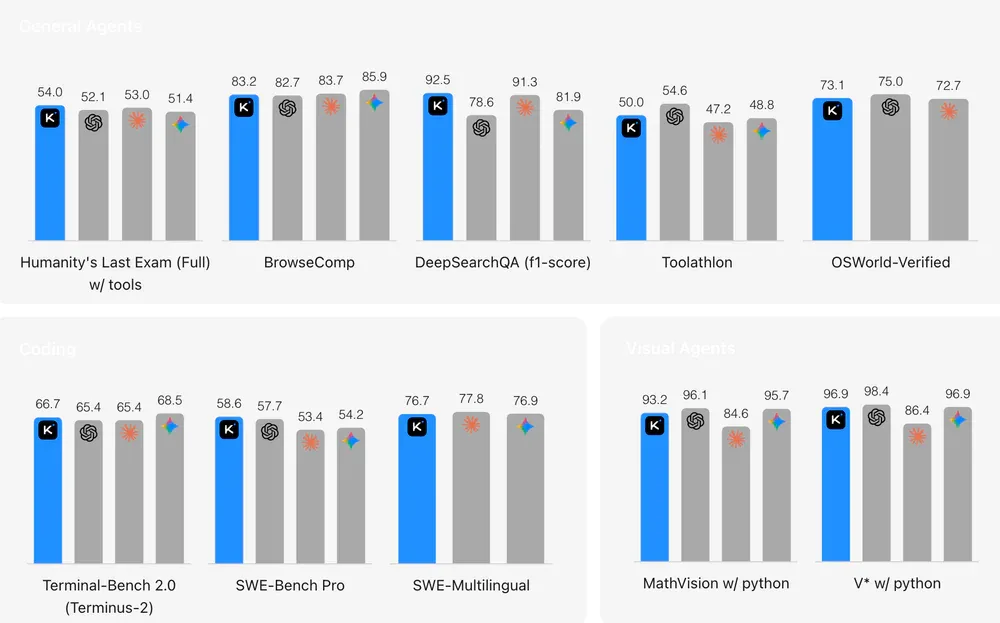
Kiến trúc: 1 nghìn tỷ tham số tổng, 32 tỷ active per token, 384 expert (8 routed + 1 shared), context window 262.144 token. Benchmarks đáng chú ý: SWE-bench Pro 58.6% (ngang GPT-5.5), HLE with tools 54.0% (dẫn đầu tất cả model), DeepSearchQA 92.5% F1, SWE-bench Verified 80.2%.
Agent Swarm là điểm khác biệt hoàn toàn không có đối thủ: 300 sub-agent chạy song song, mỗi agent xử lý subtask riêng biệt, coordinator tổng hợp kết quả - tất cả từ một prompt duy nhất.
Moonshot AI demo nội bộ: chạy Kimi K2.6 làm autonomous agent 5 ngày liên tục quản lý monitoring, incident response và system operations mà không cần human.
Case study thực tế: K2.6 tự cải tiến một financial matching engine 8 năm tuổi trong 13 giờ - 12 chiến lược tối ưu, hơn 1.000 tool calls, 4.000+ dòng code, kết quả tăng 185% medium throughput. Một agent swarm khác: 100 agent đối chiếu 1 CV với 100 job posting và trả về 100 resume được customize.
Open-weight (Modified MIT) - tự host được trên 4x H100 INT4. Dùng qua Cloudflare Workers AI, Together.ai, DeepInfra, Fireworks, hoặc API chính thức tại platform.moonshot.ai.
Claude Opus 4.7 - kỹ sư senior
Opus 4.7 là lựa chọn khi độ chính xác quan trọng hơn tốc độ: code production, hợp đồng pháp lý, phân tích tài chính, workflows dùng nhiều tool MCP phức tạp.
SWE-bench Pro 64.3% - dẫn đầu, cách Kimi & GPT-5.5 tới 10 điểm
MCP-Atlas 77.3% - tool use tốt nhất thị trường hiện tại
Vision 3x - xử lý ảnh lên 2.576px, visual acuity tăng từ 54.5% lên 98.5%
OSWorld-Verified 78.0% - computer use, tự điều hướng GUI thực
Finance Agent v1.1 64.4% - dẫn đầu phân tích tài chính
Tính năng mới của 4.7: model tự verify output trước khi báo hoàn thành - viết test, chạy test, fix lỗi, rồi mới trả kết quả. Trong môi trường agent, lỗi logic bị bắt trước khi đến tay bạn.
Lưu ý: tokenizer mới tạo ra 1.0-1.35x token nhiều hơn Opus 4.6 cho cùng input. Rate card $5/$25 nhưng chi phí thực tế cao hơn một chút tùy prompt.
GPT-5.5 - nhà nghiên cứu & operator
GPT-5.5 dẫn đầu Intelligence Index tổng thể (60 điểm vs Opus 57 vs Kimi 54). Hai thế mạnh rõ nhất: web research và CLI/DevOps automation.
Terminal-Bench 2.0: 82.7% - vs Opus 69.4% vs Kimi 66.7% - không có đối thủ trên terminal
BrowseComp (Pro): 90.1% - web research tốt nhất hiện tại trong tất cả model
GDPval: vượt chuyên gia trong 84.9% trong số 44 ngành nghề
OpenAI thiết kế GPT-5.5 dùng ít output token hơn cho cùng task - giá $5/$30 trông đắt nhưng cost per task thực tế thấp hơn trên những task phù hợp. Điểm yếu: thua Opus trên code chất lượng thực tế (SWE-bench Pro 58.6% vs 64.3%), thua Kimi về giá cho bulk work.
Routing: phân công đúng người đúng việc

Đây là chiến lược cốt lõi: không trung thành với một model - route đúng task đến đúng model mỗi 5 giây quyết định.
Giao Kimi K2.6: coding khối lượng lớn, frontend generation từ prompt hoặc ảnh, agent swarm research, chạy tự động qua đêm, batch processing bất kỳ thứ gì cần làm rẻ và nhiều. Cần 50 function, 100 trang research, full-stack app scaffold, hoặc agent chạy 12 giờ unattended - Kimi là lựa chọn.
Giao Claude Opus 4.7: code production cần đúng ngay từ lần đầu, hợp đồng pháp lý, enterprise workflows, task dùng nhiều tool MCP, vision & phân tích tài chính. Khi sai một lần tốn nhiều hơn cả tháng token - Opus là lựa chọn.
Giao GPT-5.5: toán học, web research cần duyệt nhiều nguồn, CLI & DevOps automation, knowledge work đòi hỏi lý luận độ sâu cao.
Công cụ routing sẵn có: claude-code-router (interface Claude Code, route tới Kimi/GPT-5.5 qua OpenRouter), RouteLLM của Berkeley/Anyscale (85% cost reduction giữ 95% chất lượng), OpenRouter (model:floor = rẻ nhất, model:nitro = throughput cao nhất).
Chi phí thực tế
Scenario một solo engineer dùng 15 triệu token API/tháng:
Setup | Chi phí/tháng |
|---|---|
100% Claude Opus 4.7 | ~$495 |
100% GPT-5.5 | ~$165 |
Smart routing (Kimi xử lý bulk work) | <$60 |
Smart routing tiết kiệm 88% so với dùng toàn Opus - từ $495 xuống dưới $60/tháng. Trong benchmark code độc lập, Kimi K2.6 chạy $0.30/run so với Opus 4.7 ở $1.10/run (3.6x rẻ hơn), điểm chất lượng chỉ cách nhau 10/100.
Kết
Ba model, ba thế mạnh riêng biệt.
Kimi K2.6 là worker giá rẻ cho bulk work và agent swarm. Opus 4.7 là kỹ sư senior cho task đòi hỏi độ chính xác cao. GPT-5.5 là nhà nghiên cứu và operator CLI.
Route đúng - tiết kiệm 88% chi phí mà chất lượng không đổi. Một tuần setup, workflow thay đổi vĩnh viễn.
Via: Anthropic, Kimi-K2.org, OpenAI, Miraflow AI.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ