
- AI agent tiêu tốn token 10-100x nhiều hơn chatbot vì re-send toàn bộ context mỗi bước - 70% trong số đó là waste.
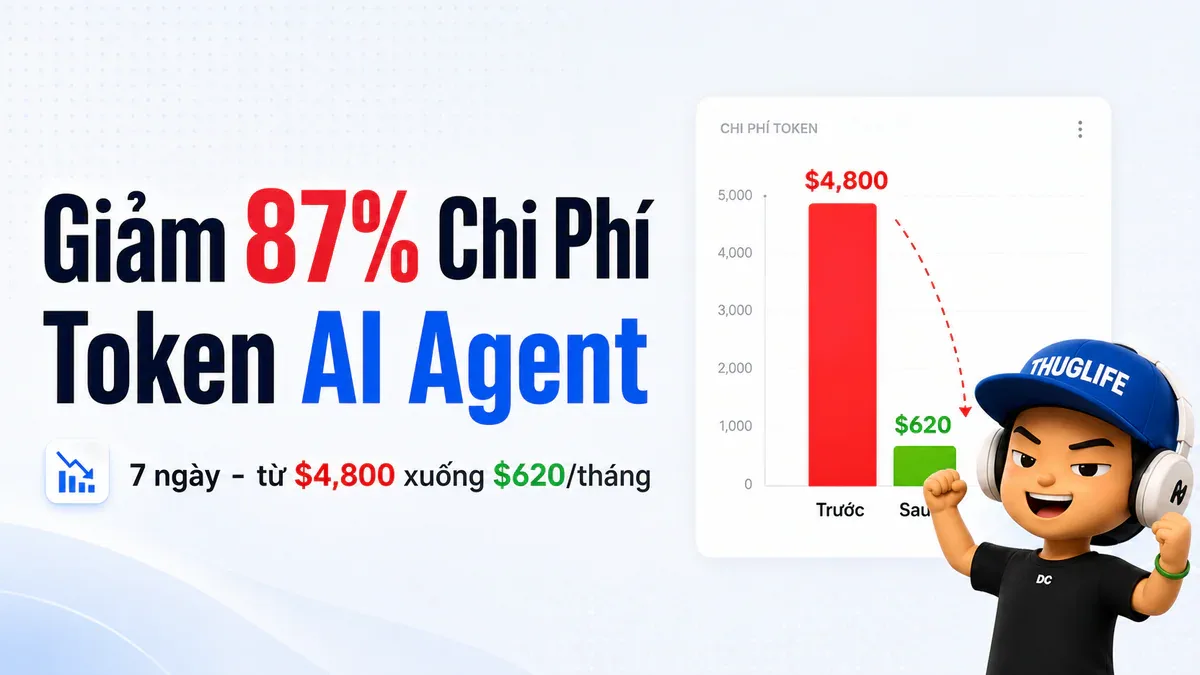
- Playbook 7 ngày giúp giảm bill từ $4,800 xuống $620/tháng (87%) mà không giảm chất lượng output.
- Prompt caching Anthropic giảm 90% chi phí token cached, chỉ cần 1 cache hit để hoà vốn.
- Model routing Haiku/Sonnet/Opus theo task complexity - một team finance tiết kiệm $365,000/năm nhờ thay đổi này.
TL;DR
AI agent không tiêu token như chatbot. Mỗi bước reasoning re-send toàn bộ lịch sử hội thoại, system prompt, và tool definitions - bill tăng phi tuyến. Session bắt đầu với 5,000 tokens có thể lên 200,000 tokens/call ở turn 50.
Playbook 7 ngày dưới đây đưa bill từ $4,800/tháng xuống $620/tháng (giảm 87%) mà không cần đổi model hay viết lại framework.
Vấn đề gốc rễ: Agent không phải chatbot
Chatbot gửi 1 tin nhắn, nhận 1 response, xong. Agent chạy vòng lặp reasoning với tool calls, file reads, validations. Mỗi bước gửi toàn bộ context tích lũy lên LLM - đến bước 20, bạn trả tiền cho cùng system prompt 20 lần.
Số liệu cụ thể trên Claude Sonnet 4.6: agent 5-step tốn $0.158 (45,700 input tokens), chatbot 1-shot cùng task chỉ tốn $0.049 (3.2x đắt hơn). Ở 50 bước: multiplier vượt 30x. Phân tích 42 agent runs cho thấy 70% tokens là waste. Re-sent context chiếm 62% tổng bill, tool definitions 14%, actual reasoning output chỉ 11%.
Ngày 1-2: Đo rồi mới Cache
Ngày 1 - Audit: Không tối ưu cái không đo được. Wire vào Helicone (proxy, free 10K req/tháng), Langfuse (open source MIT, 26M SDK installs/tháng), hoặc Portkey (250+ providers). Track: cost per session, top 5 functions đắt nhất, top 5 users đắt nhất. Một team phát hiện 47% bill đến từ deprecated function được gọi bởi cron job 15 phút/lần - tắt cron, bill giảm 47% ngay lập tức.
Ngày 2 - Prompt Caching: Đây là đòn bẩy lớn nhất. Anthropic cho giảm 90% trên cache reads. Cache write lần đầu tốn +25% (1.25x giá gốc, TTL 5 phút), break-even chỉ sau 1 hit. System prompt 5,000 tokens gửi 200 lần: không cache tốn 1M tokens, có cache chỉ 105,000 tokens - giảm 89.5%.
Thêm "cache_control": {"type": "ephemeral"} vào system prompt content block là đủ. Lưu ý: content động (timestamp, tên user) phải đặt cuối prompt, không đặt đầu - nếu không cache hit rate = 0. Minimum: 1,024 tokens cho Sonnet, 4,096 tokens cho Haiku và Opus.
Ngày 3-4: Compress Context và Route Model
Ngày 3 - Compress: Một agent trước tối ưu gửi ~14,500 tokens/turn (3,200 tool defs + 5,800 telemetry + 2,400 state + 3,100 retrieval). Sau khi nén: 850 tokens/turn - giảm 94%, output quality giữ trong 2% trên 50-example eval. Kỹ thuật: truncate tool results (trả path + 500 chars đầu thay vì full file), summarized scratchpad (200-word summary thay cho 30 tool calls), sliding window giữ N lượt gần nhất.
Ngày 4 - Model Routing: Không phải mọi task cần Opus.
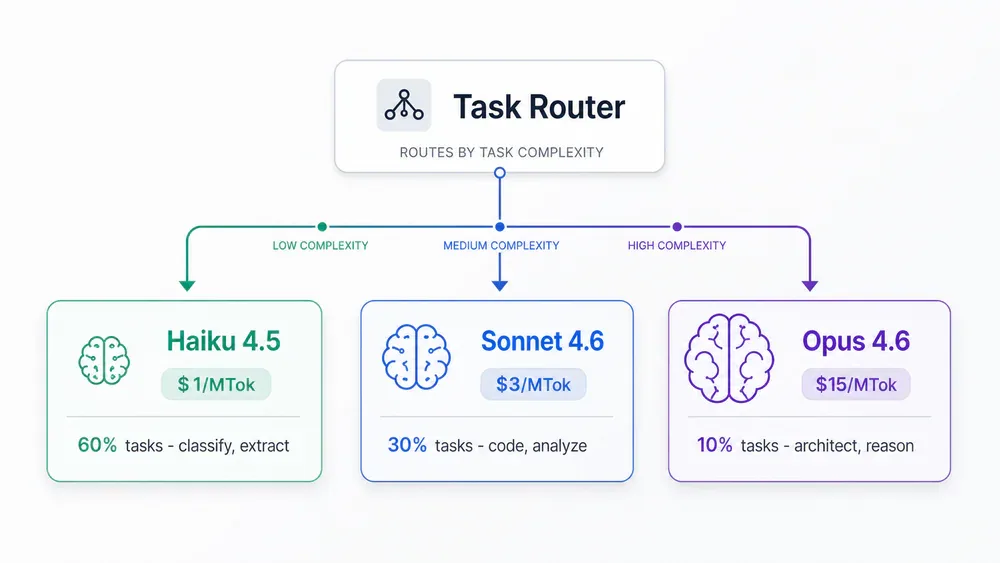
- Haiku 4.5 ($1/MTok) - classify, retrieve, transform. ~60% tasks.
- Sonnet 4.6 ($3/MTok) - code gen, analysis, mid-complexity. ~30% tasks.
- Opus 4.6 ($15/MTok) - architecture, novel reasoning. ~10% tasks.
Workflow 80% Haiku + 20% Opus tốn khoảng 12% so với all-Opus. KanseiLink chuyển high-volume tasks sang Haiku+batch: $54 → $9/workflow (83%). Team finance: $365,000 tiết kiệm/năm. Pattern advisor (Haiku/Sonnet worker, Opus reviewer mỗi N turns): giảm 11% cost, tăng 2% quality.
Ngày 5-7: Chặn Loop, Validate Cache, Khóa Alerts
Ngày 5 - Retry loops: Tháng 4/2026, regression trong Claude Code đẩy API retry rates tăng 80x. Phân tích 6,852 sessions chỉ ra 4 pattern phổ biến: broken tool bị retry vô hạn, harness swallow errors không rõ ràng, agent loop produce same output, thay đổi upstream behavior bị interpret sai. Fix: MAX_STEPS=10 hard bound, structured error results, idempotency keys trên tool calls, abort nếu 3 lượt không tạo artifact mới. Kết quả: giảm 30-60% trên tail cost distribution.
Ngày 6 - Validate cache: Kiểm tra hit rate per route, không phải tổng. Target: stable routes 70-90%, partially stable 30-50%. Dưới 30% = cấu trúc sai. Debug: prefix đủ dài chưa? Có volatile field ở đầu không? TTL có đủ cho traffic pattern? Run audit này hàng tuần.
Ngày 7 - Alerts: Slack cho 1-2x normal spend (điều tra trong giờ làm), PagerDuty cho 5x+ spike (interrupt ngay), email digest hàng tuần. Alert thêm: 1 user chiếm >N% total daily spend (thường là script bị quên). Không có alerts - khoản tiết kiệm sẽ trôi dần khi team ship feature mới.
Kết
Token bill của bạn không phải vấn đề model - đây là vấn đề kỹ thuật. Sau 7 ngày: $4,800 → $620/tháng, cache hit rate 27% → 78%, annual savings ~$50,000. Pricing wars đang chậm lại - team nào xây cost discipline năm nay sẽ còn profitable khi giá API ngừng giảm.
via Himanshu trên X | Anthropic Prompt Caching Docs | LeanOps: Agentic AI Cost Runaway