
- 70-87% tokens trong một coding agent session là waste - không phải code generation.
- Kỹ thuật context engineering đúng có thể giảm chi phí từ $6-8 xuống $1.50-2.70 mỗi session.
- Model routing 3 tầng tiết kiệm 51% so với chạy đồng nhất Opus 4.6.
- Kimi K2.6 vượt GPT-5.4 trên SWE-Bench Pro với chi phí input thấp hơn 8.3 lần.
TL;DR
Andrej Karpathy đặt ra thuật ngữ context engineering vào tháng 6/2025 - và nó đang định hình lại cách developer thực sự tiết kiệm tiền AI. Không phải prompt engineering. Không phải chọn model rẻ hơn. Mà là: gửi đúng thứ, đúng lúc, đúng lượng.
Số liệu thực tế: 70-87% tokens trong một coding agent session là waste. Chỉ 5-15% là code generation - thứ bạn thực sự trả tiền. Phần còn lại là file scanning, code discovery, context re-sending - những thứ bạn không cần gửi.
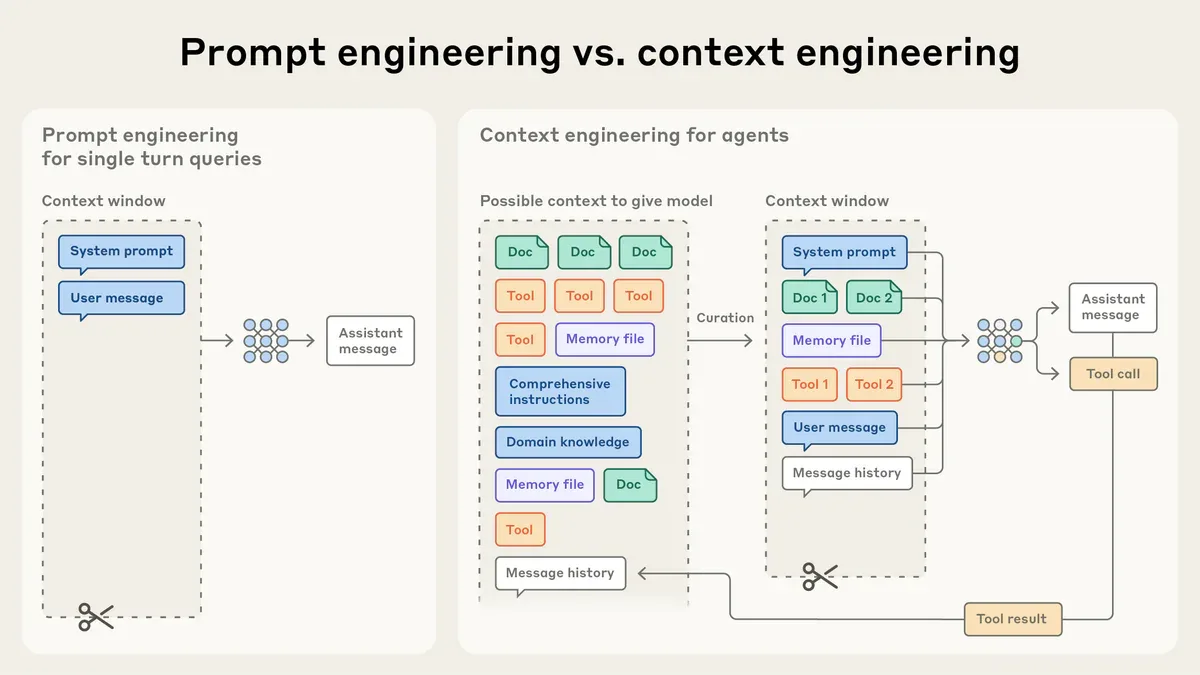
Context engineering là gì - và tại sao khác với prompt engineering
Karpathy định nghĩa chính xác (X post, 25/6/2025):
"Context engineering is the delicate art and science of filling the context window with just the right information for the next step."
Phân biệt quan trọng: prompt engineering hướng dẫn model phải làm gì ngay bây giờ. Context engineering định hình cách model hiểu thế giới của nó.
Trong 2025 LLM Year in Review, Karpathy xác định hai nhiệm vụ cốt lõi của LLM app hiện đại:
- Context engineering - preprocessing và packaging domain-specific context
- Multi-call orchestration - kết nối nhiều LLM call thành DAG phức tạp, cân bằng performance và cost
Ba failure mode phổ biến mà context kém gây ra:
- Context poisoning: lỗi sớm lan truyền qua memory, làm hỏng cả session
- Context distraction: quá nhiều thông tin không liên quan chôn vùi key details
- Context clash: instructions mâu thuẫn gây mất ổn định response
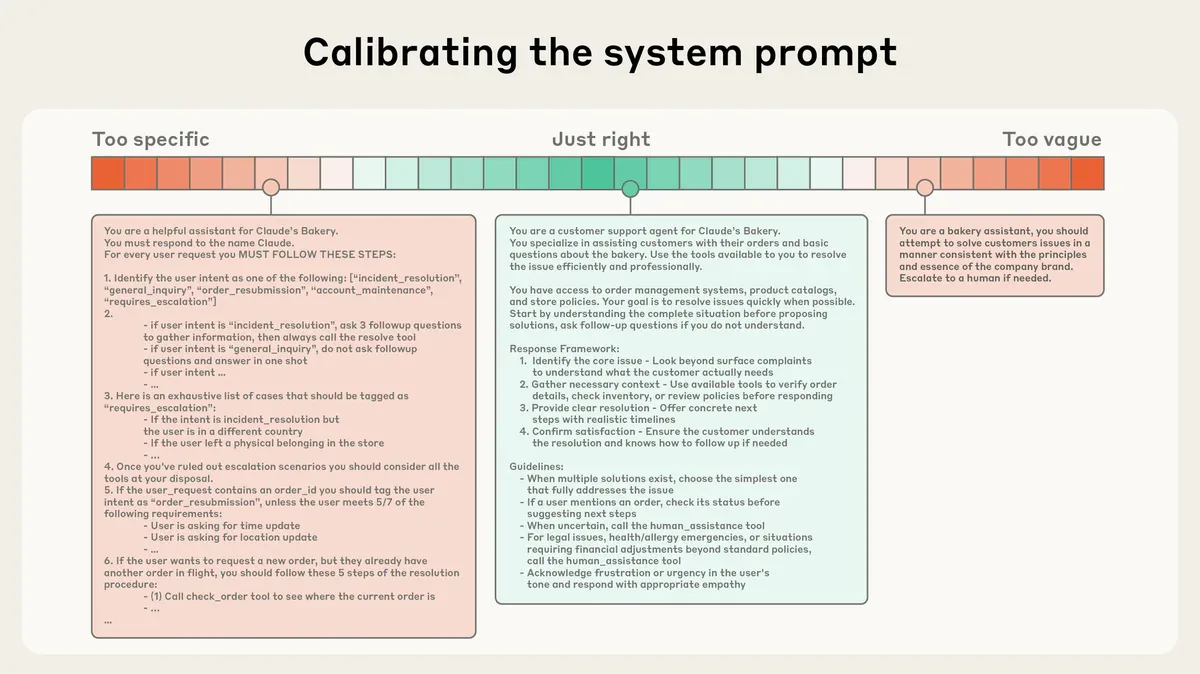
Con số đáng sợ: bạn đang lãng phí bao nhiêu
Dữ liệu từ nhiều nghiên cứu độc lập:
| Nguồn | Số liệu |
|---|---|
| DEV Community (42 agent runs) | 70% coding agent tokens là waste |
| Phân tích riêng biệt | 87% tokens đi vào "discovering code" thay vì viết code |
| CostLayer semantic study | 8,200 tokens/query → 2,100 tokens (74% giảm) |
| Morph lazy loading | 95% context reduction khả thi |
| MindStudio CLI custom | 132,000 tokens → 2,000 tokens (66x reduction) |
Breakdown token điển hình trong một coding agent session:
- File reading / code search: 35-45%
- Tool output: 15-25%
- Context re-sending: 15-20%
- Reasoning/planning: 10-15%
- Code generation thực sự: chỉ 5-15%
Cost impact cụ thể: với team 500 queries/ngày, generic prompts tốn $22,448/năm. Semantic prompts tốn $5,744/năm. Chênh lệch: $16,704/năm - từ việc thay đổi cách viết prompt.
7 kỹ thuật giảm token waste ngay hôm nay
1. Scoped prompts thay vì generic
Thay vì: "Review auth middleware"
Dùng: "Review /src/middleware/auth.ts lines 45-89, check token expiry logic"
CostLayer ghi nhận mức giảm 74% tokens chỉ từ kỹ thuật này - include exact file paths, decision boundaries, output constraints.
2. AGENTS.md / SKILL.md layering
Layer 1 - AGENTS.md (<100 lines, always-on): architecture, conventions, hard constraints.
Layer 2 - CLAUDE.md (<20 lines): reference AGENTS.md, Claude-specific hints.
Layer 3 - SKILL.md (on-demand): load chỉ khi relevant.
Rule quan trọng: "Every line should pass this test: would removing this cause the agent to make a mistake it cannot recover from?" Nếu không - xóa đi.
3. Context compaction khi session dài
Khi context > 128k tokens: summarize 20 turns cũ nhất thành JSON, giữ 3 turns cuối raw. Sub-agents trả về condensed summaries 1,000-2,000 tokens cho parent agent - không phải full conversation.
4. .claudeignore đúng cách
Exclude node_modules, build artifacts, binaries - giảm context consumption 80%+. Claude Code dùng 5.5x ít tokens hơn Cursor cho equivalent tasks, một phần nhờ cơ chế này.
5. Prompt caching trên stable prefix
System prompt cố định (architecture docs, coding conventions) - cache write một lần, reads sau với 90% discount. Anti-pattern cần tránh: include timestamps như "Current time: 2026-05-13T08:27:00Z" trong system prompt - invalidate cache mỗi request.
6. MCP aggregation thay vì raw data dumps
Thay vì get_all_sales_records (50 fields), expose get_sales_summary_by_region (3-5 fields). Giảm payload tokens 80-90%.
7. Batch API cho non-urgent work
50% flat discount cho tasks không cần real-time response, processed trong 24 giờ.
Model routing - chiến lược nhân đôi tiết kiệm
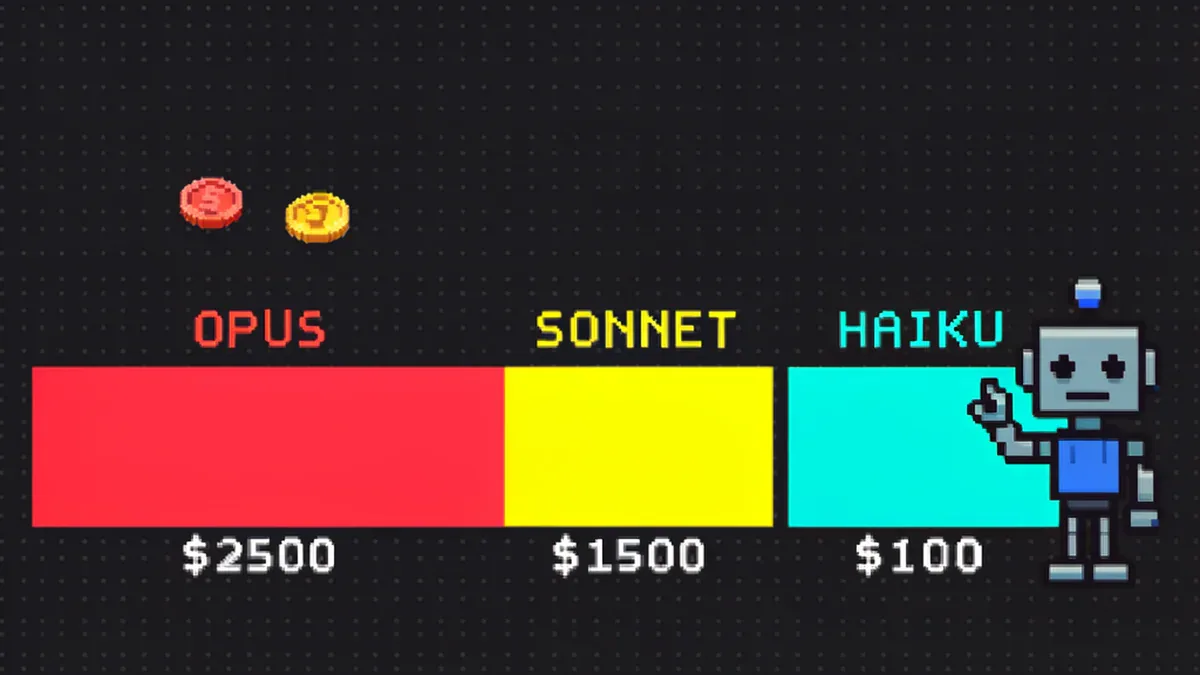
Pricing API tháng 4/2026:
| Model | Input $/MTok | Output $/MTok |
|---|---|---|
| Claude Opus 4.6 | $5.00 | $25.00 |
| Claude Sonnet 4.6 | $3.00 | $15.00 |
| Claude Haiku 4.5 | $1.00 | $5.00 |
| Kimi K2.6 | $0.60 | $2.50 |
| GPT-5-mini | $0.25 | $1.00 |
Framework routing theo role (theo Augment Code):
- Coordination / Planning → Claude Opus 4.6 (SWE-bench 80.84%, MCP Atlas 59.5%)
- Code Implementation → Claude Sonnet 4.6 (79.6% SWE-bench, 34% fewer tool calls)
- File Navigation, lint, format → Claude Haiku 4.5 (3x rẻ hơn Sonnet input)
- Code Review async → GPT-5.2 (deeper investigation)
Savings cụ thể: Uniform Opus 4.6 tốn $2.02/session (200-call). Three-tier routing: $0.98/session. Tiết kiệm 51% - phần lớn từ routing file operations: $0.66 → $0.14 mỗi session.
Kết hợp cả 5 kỹ thuật optimization (model routing + context compaction + scoped prompts + prompt caching + batch API): baseline $6-8/session giảm xuống $1.50-2.70/session - tức 55-70% savings.
Kimi K2.6 và mặt trận open-source
Tháng 4/2026, Kimi K2.6 đạt 58.6% trên SWE-Bench Pro - vượt GPT-5.4 (57.7%) và Claude Opus 4.6 (53.4%) với chi phí input rẻ hơn 8.3 lần so với Opus. Trên LiveCodeBench v6: 89.6% (Opus: 88.8%).
Tuy nhiên có một caveat quan trọng: K2.6 thinking mode sinh ~170M output tokens trong benchmark evaluation, so với median 47M của các model tương đương. Output cost dominates - và có thể xóa sổ hoàn toàn lợi thế input pricing. Routing mindset vẫn áp dụng: K2.6 tốt nhất cho bulk implementation tasks, không phải cho mọi thứ.
Lời cảnh báo từ ETH Zurich
Nghiên cứu ETH Zurich (tháng 2/2026) trên context files đưa ra kết quả đáng ngạc nhiên: human-written context files cải thiện success rate chỉ ~4% - nhưng tăng inference cost hơn 20%. LLM-generated context files thậm chí giảm success rate ~3%. CLAUDE.md 300+ lines: agent follows inconsistently.
Bài học: context engineering không phải "viết thật nhiều vào CLAUDE.md". Mà là viết đúng thứ cần thiết, không hơn. Mỗi dòng tốn token mỗi turn - chi phí ẩn tích lũy nhanh hơn bạn nghĩ.
Routing mindset - khoảng cách thực sự
Trong 12 tháng tới, khoảng cách giữa developer shipping ở $200/tháng và $4,000/tháng sẽ không phải là kỹ năng viết code. Sẽ là routing mindset: biết gửi đúng thứ, đúng model, đúng lúc.
Bốn thứ thực sự compound theo thời gian:
- Context discipline - grep trước khi fetch, always
- Prompt caching trên mọi stable prefix
- Multi-model routing (Haiku default, Opus cho 10% quan trọng nhất)
- SKILL.md files cho specialized procedures - viết một lần, tiết kiệm mỗi execution
Khoảng cách $200 vs $4,000/tháng không đến từ việc ai dùng AI nhiều hơn. Đến từ việc ai hiểu rằng 90% hóa đơn là context không cần gửi - và làm gì đó với nó.
via Anthropic Engineering · CostLayer · Morph · Augment Code
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ