
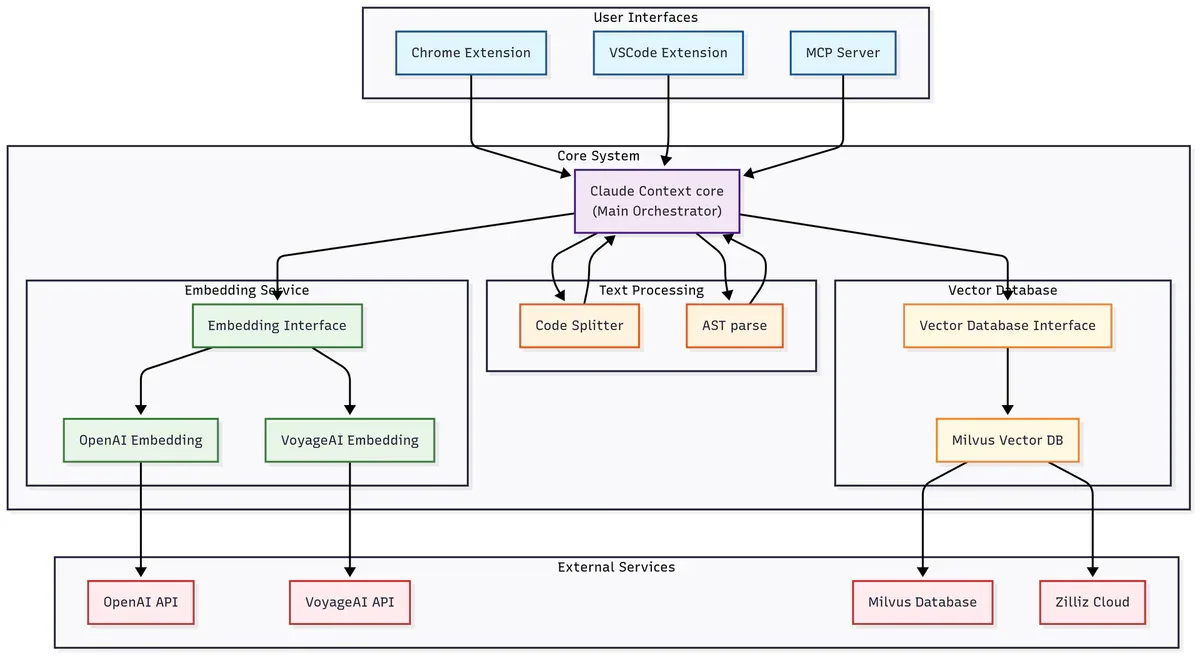
- Claude Context là MCP plugin open-source của Zilliz, thay thế grep-only bằng hybrid BM25 + vector search trên toàn codebase.
- Benchmark chính thức: 44.4K token so với 73.4K (-39.4%) và 5.3 tool calls so với 8.3 (-36.3%).
- Monorepo 12,000 file được index trong 3-6 phút, hỗ trợ OpenAI, VoyageAI, Ollama và Gemini.
- MIT license, self-host hoàn toàn được với Milvus + Ollama, không cần trả thêm gì ngoài ops cost.
TL;DR
Claude Code mặc định dùng grep để tìm code - nghĩa là AI phải gọi tool nhiều lần, kéo cả block code lớn vào context, rồi mới xử lý. Kết quả: tốn token, chậm, và hay lạc đề. Claude Context là MCP plugin open-source của Zilliz giải quyết đúng vấn đề này: index codebase vào vector database, AI truy vấn bằng ngôn ngữ tự nhiên, chỉ nhận về đúng code liên quan.
Benchmark chính thức: -39.4% token (44.4K vs 73.4K) và -36.3% tool calls (5.3 vs 8.3).

Vấn đề với grep-only retrieval
Khi Claude Code cần hiểu một phần codebase, nó làm theo cách thủ công:
Chạy
greptìm từ khóaĐọc cả file hoặc cả thư mục
Lặp lại nhiều lần để thu hẹp context
Với codebase nhỏ, cách này ổn. Nhưng với monorepo hàng chục nghìn file, mỗi lần grep là token bloat: AI phải đọc code không liên quan, gọi tool nhiều lần hơn cần thiết, và đôi khi vẫn bỏ sót đúng file cần tìm vì không match đúng keyword.
Đây là vấn đề Claude Context được thiết kế để giải quyết - thay keyword search bằng semantic understanding.
Cách hoạt động
Claude Context hoạt động theo 3 bước:
Index: Đọc toàn bộ codebase, dùng AST parser (tree-sitter) để chia code thành các chunk theo logic thực sự - theo function, class, method thay vì cắt theo số ký tự. Với ngôn ngữ chưa hỗ trợ AST, fallback về LangChain splitter.
Embed: Chuyển từng chunk thành vector embedding qua OpenAI, VoyageAI, Gemini hoặc Ollama (local). Lưu vào Milvus hoặc Zilliz Cloud.
Retrieve: Khi AI cần tìm code, gửi natural language query, hệ thống chạy hybrid search: BM25 + dense vector - kết hợp keyword precision với semantic similarity, trả về đúng chunk liên quan.
Incremental indexing dùng Merkle DAG - chỉ re-index file đã thay đổi, không phải toàn bộ repo mỗi lần.
Con số đáng chú ý
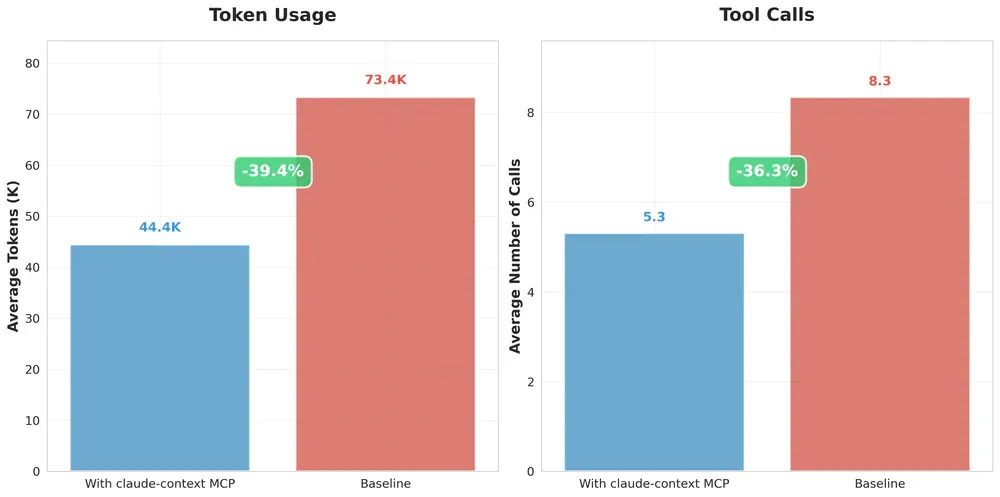
Theo benchmark controlled của Zilliz:
Token usage: 44.4K vs 73.4K → giảm 39.4%
Tool calls: 5.3 vs 8.3 → giảm 36.3%
Monorepo TypeScript 12,000 file: index trong 3-6 phút, output <10,000 chunks
Chi phí embedding ban đầu tốn nhất - nhưng sau đó chỉ cập nhật file đã thay đổi nhờ Merkle tracking.
Ai nên thử ngay
Phù hợp cho:
Team làm monorepo lớn (hàng nghìn file) thường xuyên dùng Claude Code, Cursor, Gemini CLI
Dự án cần onboard developer mới nhanh - hỏi câu hỏi kiến trúc nhận snippet chính xác, giảm ramp-up time 30-50%
Refactoring lớn: tìm toàn bộ semantic usage của deprecated API, kể cả indirect dependencies
Security audit: locate SQL injection patterns, auth vulnerabilities theo concept, không phải exact string
Không phù hợp nếu: codebase nhỏ (grep đủ), yêu cầu offline hoàn toàn không chấp nhận bất kỳ cloud nào (tuy nhiên có thể dùng Ollama + self-hosted Milvus để code không rời khỏi hạ tầng), hoặc cần jump-to-definition chính xác thay vì fuzzy semantic recall.
Chi phí và cài đặt
Claude Context là MIT license, open-source. Chi phí tuỳ theo stack chọn:
Zilliz Free Tier + OpenAI embedding: ~$0-5/tháng
Fully self-hosted (Ollama + Milvus): $0 - chỉ ops cost, code không ra ngoài
Zilliz Paid + embedding: $109+/tháng cho production scale
Cài vào Claude Code bằng 1 lệnh:
claude mcp add claude-context \
-e OPENAI_API_KEY=your-key \
-e MILVUS_TOKEN=your-zilliz-token \
-- npx @zilliz/claude-context-mcp@latestYêu cầu: Node.js 20 hoặc 22 (Node 24 chưa hỗ trợ). Sau khi add, dùng index_codebase để index lần đầu.
Kết
Claude Context đại diện cho hướng đi mới trong Context Engineering - thay vì cố nhồi cả codebase vào prompt, dùng RAG để chỉ lấy đúng thứ AI cần. Kết quả: ít token hơn, ít tool calls hơn, và AI hiểu code tốt hơn vì context liên quan thay vì nhiễu.
Với số liệu -39.4% token và -36.3% tool calls từ benchmark thực tế, đây là plugin đáng thử cho bất kỳ team nào đang dùng Claude Code trên codebase lớn.
via: GitHub - zilliztech/claude-context · Claude Context Guide · Deep Dive: Zilliz Claude Context MCP