
- Hầu hết AI agent tốn kém không phải vì model đắt, mà vì không ai kiểm soát lượng token gửi đi.
- 10 open-source repos này giải quyết vấn đề đó ở 7 layer khác nhau.
- LLMLingua nén prompt tới 20x trước khi gọi API với gần như không mất chất lượng.
- mem0 cô đọng 10,000 token conversation history xuống còn 200 token per agent.
- LiteLLM route tác vụ đơn giản sang Haiku thay vì Sonnet - tiết kiệm 20x chi phí trên cùng một output.
TL;DR
Tweet của @self.dll đặt ra câu hỏi ai cũng bỏ qua: bạn có biết agent đang gửi bao nhiêu token lên API không? Câu trả lời thường là không. 10 repos dưới đây giải quyết bài toán này từ 7 góc độ khác nhau - từ nén prompt, quản lý memory, routing model rẻ hơn, cho tới đo token trước khi bill đến.

Agent tốn kém không phải vì model đắt - mà vì không ai kiểm soát lượng token gửi đi
Vấn đề thật sự không phải model đắt
Mô hình flagship hiện nay có giá $2.50-3 per million input tokens và $10-15 per million output tokens. Output tốn 4-5x so với input. Nhưng budget models như Haiku chỉ $0.15/$0.60 - rẻ hơn 16x cho cùng số token.
Vấn đề là phần lớn agent gửi thừa token: system prompt phình to, conversation history tích lũy, cả codebase được đưa vào context, document 100 trang gửi nguyên. Không phải model tệ - là prompt không được kiểm soát.
10 repos này tackle từng điểm nghẽn đó.
Layer 1: Nén prompt trước khi gọi API
1. microsoft/LLMLingua - 6,200 stars
LLMLingua dùng một small LM (GPT2-small hoặc LLaMA-7B) để tìm và loại bỏ các token không thiết yếu trong prompt trước khi gửi lên model lớn. Kết quả: nén tới 20x, giảm 95% token, gần như không mất chất lượng.
LongLLMLingua: cải thiện RAG performance lên 21.4% chỉ với 1/4 số token
LLMLingua-2: nhanh hơn, dùng data distillation từ GPT-4
Được tích hợp sẵn vào LangChain, LlamaIndex, Microsoft Prompt Flow
Published: EMNLP 2023, ACL 2024, CoLM 2025
Phù hợp nhất khi: prompt chứa few-shot examples dài, RAG context lớn, hoặc system prompt phức tạp.
Layer 2: Thay conversation history bằng memory thông minh
2. mem0ai/mem0 - 55,000 stars
Thay vì gửi toàn bộ lịch sử hội thoại, mem0 cô đọng 10,000 token history xuống còn 200 token - chỉ giữ lại những gì thực sự cần. Tiết kiệm 50x per agent per session.
Algorithm update tháng 4/2026 đạt điểm LoCoMo benchmark 91.6 (+20 điểm) và LongMemEval 93.4 (+26 điểm) với latency dưới 1.1 giây. Hỗ trợ Python/TypeScript, self-hosted hoặc managed cloud.
6. letta-ai/letta - 22,400 stars
Letta (trước là MemGPT) dùng paged memory - chia memory thành các block có nhãn, agent chỉ load block liên quan thay vì đưa toàn bộ lịch sử vào context. Giải quyết đúng bài toán: agent long-running bị crash khi context window đầy và phải retry toàn bộ.
Layer 3: RAG và vector search thay full document
4. run-llama/llama_index - 49,200 stars
Thay vì gửi toàn bộ tài liệu, LlamaIndex index và retrieve: 100-page PDF → 3 chunks liên quan → 98% ít token hơn per query. Hỗ trợ 130+ định dạng document, 300+ integration packages.
5. chroma-core/chroma - 27,800 stars
Vector database thay thế keyword search trên full context. Thay vì gửi hàng nghìn token để tìm thông tin, Chroma tìm closest semantic match và chỉ feed đúng phần đó: 50-200 tokens per query thay vì hàng nghìn.
Layer 4: Route đúng task sang đúng model
3. BerriAI/litellm - 46,000 stars
LiteLLM là AI Gateway kết nối 100+ LLM providers qua một interface thống nhất. Logic cốt lõi: task đơn giản → Haiku, task phức tạp → Sonnet/Opus. Track chi phí per agent, per call, per day.
Ví dụ thực tế: classify intent (task đơn giản) gọi Haiku ở $0.15/M tokens. Generate report phức tạp mới cần Sonnet ở $3/M tokens. Trên cùng một agent pipeline, chênh lệch 20x.
Layer 5: Kiểm soát output, không để model lan man
7. guidance-ai/guidance - 21,400 stars
Structured generation: thay vì viết prompt dài để ép model trả JSON, guidance dùng constrained decoding để output chỉ có thể là JSON hợp lệ ngay từ đầu. Cắt 30-50% output token bloat.
Token fast-forwarding: với các token có thể predict được từ grammar constraint, guidance skip luôn forward pass của model - giảm cả computation lẫn latency. Release v0.3.2 tháng 3/2026.
Layer 6: Chỉ gửi code liên quan, không gửi cả repo
8. Aider-AI/aider - 44,500 stars
Aider build repo map từ toàn bộ codebase, sau đó chỉ gửi những file liên quan đến task thay vì dump cả project. Đây là vấn đề phổ biến với coding agent: developer paste cả codebase vào context vì không biết file nào cần. Aider giải quyết tự động.
13,133 commits, development cực kỳ active.
Layer 7: Đo token trước khi bill đến
9. openai/tiktoken - 18,100 stars
BPE tokenizer chính thức của OpenAI, nhanh hơn 3-6x so với các alternative. Dùng để tính chính xác số token trước khi gọi API - biết cost trước, không sau khi bill đến.
10. simonw/ttok - 389 stars
CLI tool đơn giản nhất trong list: pipe text vào, set budget limit, nhận lại output đã truncate đúng ngưỡng. Không fancy, không config. Chạy được ngay. Đặc biệt hữu ích trong pipeline tự động cần hard cap token.
Stack kết hợp: 80% savings đến từ đâu
Không có tool nào đơn lẻ đạt 80%. Con số đó đến từ việc stack nhiều layer:
Layer | Tool | Savings điển hình |
|---|---|---|
Prompt compression | LLMLingua | 80-95% prompt tokens |
Memory | mem0 | 50x history reduction |
RAG | LlamaIndex + Chroma | 98% document tokens |
Routing | LiteLLM | 16-20x cost per task |
Output | guidance | 30-50% output tokens |
Code context | Aider | Loại bỏ irrelevant files |
Monitoring | tiktoken + ttok | Prevent overrun |
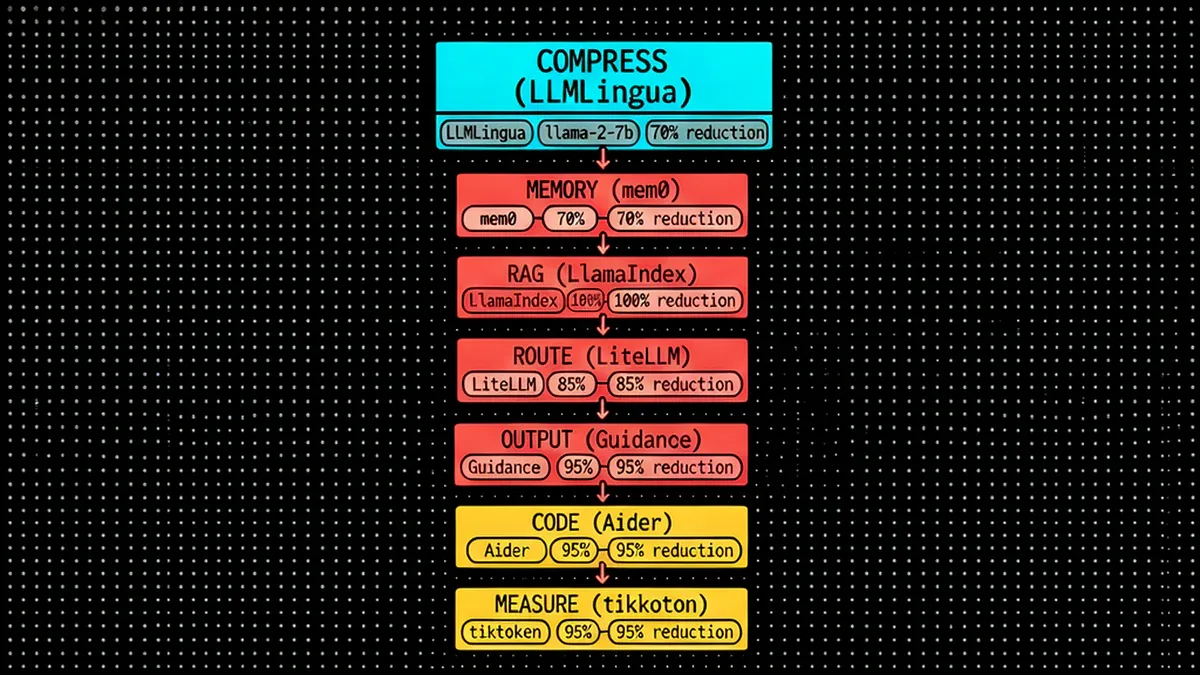
7 layer tối ưu token - từ nén prompt đến đo lường trước khi bill đến
Bắt đầu từ những gì dễ nhất: tiktoken để đo (bạn phải biết đang tốn bao nhiêu trước khi optimize), sau đó mem0 nếu agent có conversation history dài, rồi LiteLLM để routing nếu pipeline có task đa dạng.
Takeaway
Câu kết của tweet nói rõ nhất: "Most agents are expensive not because the model is expensive — because nobody checked what was being sent to it." Token optimization không phải engineering phức tạp. Đa số chỉ cần đo và route đúng.
Cả 10 repos đều MIT/Apache 2.0 license, free to use. Đây không phải hype, là production-tested tooling.
Via: microsoft/LLMLingua, mem0ai/mem0, Redis LLM Optimization Blog.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ