
- Routing 80% task coding thông thường sang model rẻ hơn giúp tiết kiệm 70-97% chi phí API.
- DeepSeek V3 qua OpenRouter chỉ $0.14/M token, rẻ hơn Claude Sonnet 100 lần.
- RouteLLM (ICLR 2025) chứng minh đạt 95% chất lượng GPT-4 với chỉ 14% GPT-4 calls.
- Kiến trúc 3 tier Fast-Smart-Power giúp phân luồng task tự động mà không cần thay đổi code.
TL;DR
Nếu bạn đang trả $500-$1,800/tháng cho AI coding tools, có thể bạn đang dùng model $15/M token cho những task chỉ cần model $0.14/M token. Router architecture là pattern giúp phân luồng tự động: task đơn giản sang model rẻ, task phức tạp mới đụng đến model đắt. Kết quả thực tế: tiết kiệm 70-97% chi phí, chất lượng giữ nguyên trên 95%.
Vấn đề thực sự
Hầu hết developer dùng AI coding tool theo kiểu mặc định: mọi prompt đều gửi lên model mạnh nhất. Claude Opus, GPT-4 Turbo, hay Gemini Ultra đều xử lý tốt - nhưng giá token cũng tương ứng: $15-$60 mỗi triệu token.
Thực tế, khoảng 80% task trong một phiên coding không cần model đó:
- Autocomplete boilerplate, generate unit test, viết docstring
- Giải thích đoạn code đơn giản, đổi tên biến, format lại file
- Câu hỏi syntax nhanh, debug lỗi hiển nhiên
Chỉ 20% task thực sự cần model mạnh: thiết kế architecture, debug race condition phức tạp, security review, hoặc xử lý logic business đặc thù. Vấn đề là không có gì tự động phân luồng hai nhóm này cho bạn.
Router là gì
LLM router là một layer nằm giữa application của bạn và các AI provider. Thay vì hard-code "luôn dùng Claude Opus", router phân tích từng request và quyết định model nào xử lý.
Quyết định dựa trên các tín hiệu:
- Độ phức tạp của prompt: độ dài, từ khóa, cấu trúc câu
- Loại task: extraction, generation, reasoning, code review
- Ngữ cảnh: đây là lần đầu hỏi hay follow-up phức tạp?
Toàn bộ quá trình phân tích xảy ra dưới 1ms, không thêm latency đáng kể cho user.
Kiến trúc 3 tier
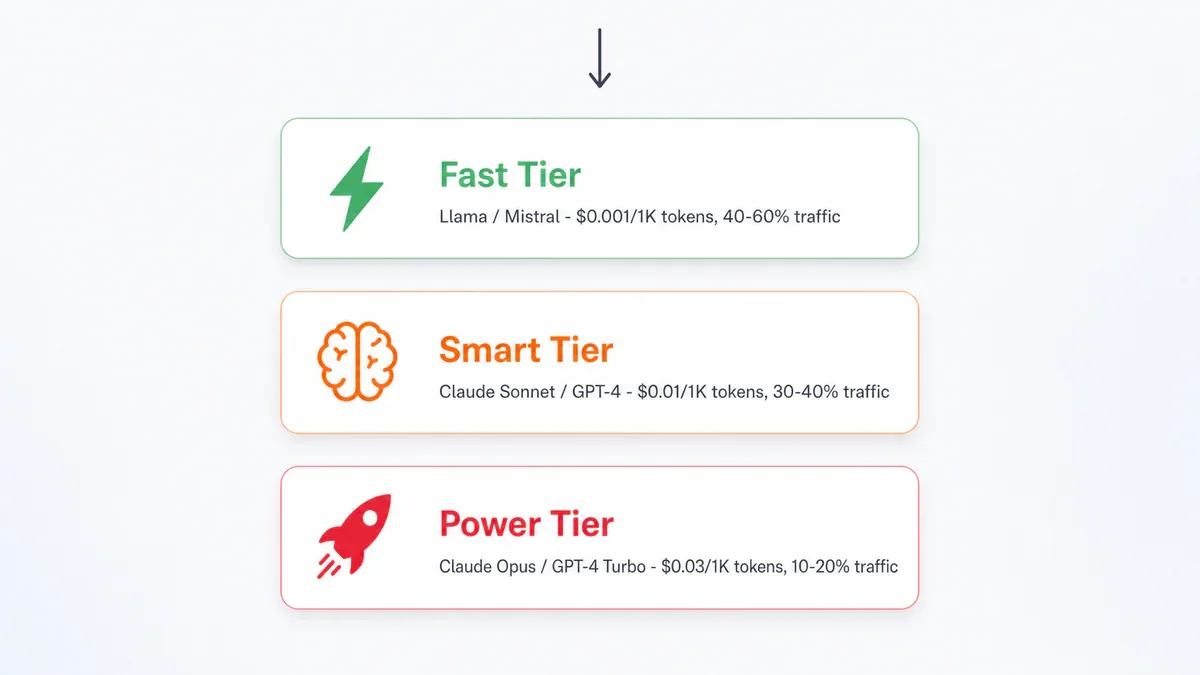
Pattern phổ biến nhất là kiến trúc 3 tầng:
Fast Tier - Llama 3 8B, Mistral 7B, Gemma 3 12B ($0.001-$0.002/1K tokens, latency <500ms): xử lý 40-60% traffic. Dùng cho autocomplete, boilerplate, câu hỏi syntax nhanh.
Smart Tier - Claude Sonnet, GPT-4, Gemini Pro ($0.01-$0.03/1K tokens, 1-3s): xử lý 30-40% traffic. Dùng cho code generation có context, debug cơ bản, giải thích logic.
Power Tier - Claude Opus, GPT-4 Turbo ($0.03-$0.10/1K tokens, 5-10s): chỉ 10-20% traffic. Dùng cho architecture design, security review, và các task reasoning phức tạp.
Chỉ cần shift 40-60% traffic sang Fast Tier là đã tiết kiệm được phần lớn chi phí.
Số liệu thực tế
RouteLLM (ICLR 2025, nghiên cứu từ UC Berkeley, Anyscale, Canva) là framework học thuật đầu tiên đo lường vấn đề này hệ thống. Kết quả:
- Matrix factorization router: đạt 95% chất lượng GPT-4 với chỉ 26% GPT-4 calls
- Với data augmentation: đạt 95% chất lượng với chỉ 14% strong model calls - giảm 75-85% chi phí
ESKOM.ai (production case study): cost per task giảm từ $8.20 xuống $2.44 (70% reduction). Với 30,000 task/tháng, tương đương tiết kiệm $324,000/năm. Đáng chú ý: quality score thực ra tăng nhẹ từ 4.1 lên 4.2/5 vì model phù hợp xử lý nhanh hơn, ít timeout hơn.
Setup nhanh với OpenRouter
Cách đơn giản nhất để bắt đầu là dùng OpenRouter làm router gateway. OpenRouter là unified API cho 100+ model, cho phép bạn swap model bằng một biến môi trường.
Với Claude Code, chỉ cần:
export ANTHROPIC_BASE_URL=https://openrouter.ai/api/v1
export ANTHROPIC_API_KEY=your_openrouter_key
export ANTHROPIC_MODEL=deepseek/deepseek-chatDeepSeek V3 qua OpenRouter: ~$0.14/M input token, so với Claude Sonnet ~$9-18/M. Với 20 ngày làm việc nặng mỗi tháng:
| Setup | Chi phí/tháng |
|---|---|
| Claude Sonnet native | $900-$1,800 |
| DeepSeek V3 via OpenRouter | $21-$42 |
| Tiết kiệm | ~97% |
Chiến lược thực tế: dùng DeepSeek V3 hoặc Gemini Flash cho 80% task thông thường, chỉ switch về Claude Sonnet/Opus khi cần. OpenRouter còn có free tier với Llama 3.3 70B và Gemma 3 12B nếu muốn test trước.
Công cụ cho production
Nếu bạn cần routing thông minh hơn cho hệ thống production (không chỉ AI coding cá nhân), có ba tool phổ biến:
- LiteLLM: unified interface cho 100+ model, hỗ trợ fallback chain và load balancing. Drop-in replacement dễ nhất.
- Portkey: production-grade với observability, request logging, A/B testing giữa các model. Phù hợp team.
- RouteLLM: dành cho team muốn train router riêng từ preference data. Công sức nhiều hơn nhưng kết quả tốt nhất.
Ngoài routing theo model, semantic cache cũng giúp tiết kiệm thêm 20-40%: cache response cho các query tương tự, không cần gọi API lần thứ hai.
Hạn chế cần biết
Router architecture không phải silver bullet. Một số điều cần lưu ý:
- Free models trên OpenRouter (Llama, Gemma) latency cao hơn 4-6x, không phù hợp khi cần phản hồi nhanh
- DeepSeek V3 chậm hơn vào giờ cao điểm, phản hồi 2s có thể thành 8-12s
- Tool calls (function calling) không ổn định với mọi model - nên test kỹ trước khi dùng trong production
- Confidence threshold của router cần calibrate theo workload thực tế, không có giá trị universal
- Escalation rate nên target dưới 2.8% - cao hơn nghĩa là Fast Tier đang nhận task quá khó
Kết
Router architecture không phải kỹ thuật phức tạp - về bản chất đây chỉ là "dùng đúng công cụ cho đúng việc". Nhưng hầu hết developer chưa làm điều đó vì thiếu tooling và không biết bắt đầu từ đâu.
Điểm khởi đầu thực tế nhất: setup OpenRouter + DeepSeek V3 cho Claude Code, dùng thử một tuần. Nếu output vẫn đủ tốt cho 80% công việc hàng ngày, bạn vừa tìm được cách tiết kiệm vài trăm đô mỗi tháng mà không cần thay đổi workflow.
via OpenRouter - Claude Code Integration Guide | via RouteLLM ICLR 2025 Paper
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ