
- 432 lần thử nghiệm cho thấy Gemini 2.5 Flash mất 29-38 điểm VTSR khi harness phức tạp hơn.
- Qwen3.5-122B đạt đỉnh 91.7% VTSR chính xác ở strict harness - ngược hoàn toàn kỳ vọng.
- Model 2B Gemma4:e2B ổn định 91.7% khắp mọi điều kiện - ngang với model mạnh hơn nhiều.
TL;DR
Giả định "harness càng siết cấu trúc càng tốt" vừa bị bác bỏ bởi 432-run experiment với 6 model trên HEAT-24 benchmark.
Với frontier chat model (Gemini 2.5 Flash), harness verbose hơn làm VTSR giảm 29-38 điểm phần trăm.
Với frontier reasoning model (Qwen3.5-122B, extended thinking), strict harness cho kết quả tốt nhất (91.7%) và latency thấp nhất - nghịch lý hoàn toàn.
Model 2B (Gemma4:e2B) match 91.7% của strong-open-tier ở mọi harness condition - nhỏ không có nghĩa là yếu.
Capable model chủ yếu fail do
format_violation; model nhỏ fail dowrong_file. Hai loại bệnh, hai loại thuốc khác nhau.
Giả định cũ - và lý do nó sai
Trong nhiều năm, cộng đồng AI agent vận hành theo một logic ngầm: model càng mạnh thì cần càng ít hướng dẫn, và harness càng có cấu trúc thì agent càng đáng tin cậy hơn.
Từ đó suy ra một "monotone inverse relationship" - model yếu cần harness phức tạp, model mạnh thì để nó tự lo.
Nghe có lý. Nhưng không đúng.
Bài nghiên cứu "It's Not the Capability: Harness Sensitivity Is Non-Monotone Across LLM Agent Tiers" của Yong-eun Cho, submitted ngày 26/5/2026, đã kiểm tra trực tiếp giả thuyết này qua thực nghiệm kiểm soát với quy mô đủ lớn để tạo ra kết quả đáng tin - và phát hiện nó sai trên hai chiều đồng thời.
432 lần chạy, 6 model, 3 kiểu harness
Thiết kế thực nghiệm khá rõ ràng: 6 model được phân vào 4 capability tier (frontier chat, frontier reasoning, strong-open, constrained), mỗi model chạy qua 3 mức harness complexity (light, balanced, strict) trên HEAT-24 - một benchmark gồm 24 task tổng hợp với git-based workspace verification. Metric chính là VTSR (Verified Task Success Rate).
Tổng cộng 432 lần chạy. Kết quả không như ai mong đợi.
Ba phát hiện nghịch lý
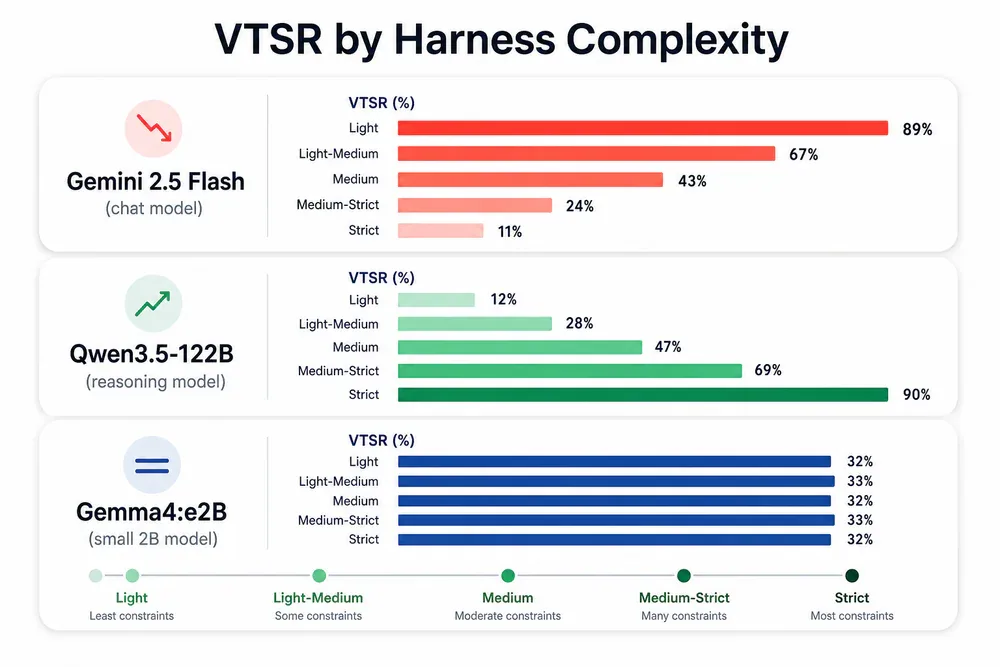
VTSR theo mức harness complexity - ba model, ba xu hướng hoàn toàn khác nhau
1. Harness-complexity paradox với chat model. Gemini 2.5 Flash - một trong những frontier model mạnh nhất hiện tại - mất 29 đến 38 điểm phần trăm VTSR khi harness chuyển từ light sang strict. Không phải cải thiện một chút, không phải giữ nguyên: giảm mạnh. Càng nhiều cấu trúc, model này càng hoạt động kém.
2. Reasoning model phản ứng ngược lại. Qwen3.5-122B với extended thinking bật lên làm điều hoàn toàn trái chiều: strict harness cho VTSR cao nhất (91.7%) và đồng thời latency thấp nhất. Model reasoning muốn được đặt trong khung chặt - và khi có khung đó, nó vừa nhanh hơn vừa chính xác hơn.
3. Model 2B đứng ngang model mạnh hơn nhiều. Gemma4:e2B - chỉ 2 tỷ tham số, thuộc constrained tier - duy trì 91.7% stability khắp tất cả harness condition. Không lên, không xuống theo harness. Đây là con số ngang với strong-open-tier model. Khoảng cách năng lực tuyệt đối không tương đương khoảng cách hiệu suất trong môi trường được thiết kế phù hợp.
Taxonomy lỗi: model mạnh thất bại vì format, model nhỏ vì sai file
Phần đáng chú ý thứ hai của nghiên cứu là failure taxonomy 6 nhãn, trong đó hai nhãn nổi bật nhất là:
format_violation- lỗi chủ đạo ở capable model. Model hiểu task, có thể làm được, nhưng output sai format mà harness yêu cầu.wrong_file- lỗi chủ đạo ở low-capability model. Model không sai format - mà nó tác động nhầm file trong workspace.
Điều này có nghĩa gì trong thực tế? Với model mạnh, vấn đề là harness không truyền đạt được đúng kỳ vọng về format - thêm cấu trúc không giải quyết được điều này, thậm chí tạo thêm nhiễu. Với model nhỏ, vấn đề là khả năng định hướng trong workspace - và đây là chỗ cấu trúc có thể giúp được.
Hai loại bệnh hoàn toàn khác nhau cần hai cách điều trị khác nhau. Áp dụng một công thức cho cả hai là sai từ gốc.
Bức tranh lớn hơn: harness là yếu tố quyết định, không phải model
Kết quả của nghiên cứu này không đứng một mình. Survey lớn về agent harness (Meng et al., tháng 4/2026) tổng hợp bằng chứng từ nhiều tổ chức độc lập:
xAI Grok Code Fast 1: 6.7% → 68.3% trên SWE-bench chỉ từ việc đổi edit-tool format trong harness - model không thay đổi.
LangChain DeepAgents: 52.8% → 66.5% (+26%) trên TerminalBench 2.0 thuần túy từ context engineering - không cập nhật model.
Vercel: giảm tool count từ 15 xuống 2 → task accuracy từ 80% lên 100%.
Cả OpenAI, Stanford/MIT, LangChain và Anthropic đều đang độc lập hội tụ về cùng một kết luận: harness là yếu tố ràng buộc thực sự, không phải model. Model capability là điều kiện cần nhưng chưa đủ.
Đây cũng là lý do benchmark gap ngày càng rộng: METR review 296 AI-generated PR cho thấy maintainer merge rate thấp hơn automated benchmark score trung bình 24.2 điểm phần trăm - và khoảng cách này đang mở rộng thêm 9.6 điểm/năm. Automated grader không nhìn thấy harness coupling problem.
Góc nhìn cá nhân: chúng ta đang đặt nhầm câu hỏi
Điều tôi thấy thú vị nhất trong nghiên cứu này không phải là con số - mà là câu hỏi nó buộc chúng ta phải đặt lại.
Suốt mấy năm qua, câu hỏi mặc định trong cộng đồng AI là: "Nên dùng model nào?" Claude hay GPT-4o? Gemini hay Qwen? Lớn hay nhỏ? Bảng xếp hạng benchmark được cập nhật hàng tuần, và mọi người nhảy vào mỗi lần có model mới ra mắt.
Nhưng nếu kết quả thực tế phụ thuộc nhiều vào cách bạn bọc model hơn là model đó là gì - thì câu hỏi đúng phải là: "Mình đang thiết kế harness cho loại model nào?"
Chat model và reasoning model không phải chỉ là hai điểm trên cùng một trục năng lực. Chúng là hai kiến trúc nhận thức khác nhau với hành vi phản ứng với context hoàn toàn trái chiều nhau.
Gemini 2.5 Flash bị ngợp khi bạn nói quá nhiều - nó muốn không gian để tự suy luận.
Qwen3.5-122B với extended thinking cần khung cứng để hướng dẫn quá trình suy luận dài - thiếu cấu trúc làm nó phân tán.
Và Gemma4:e2B? Có lẽ đáng ngạc nhiên nhất. Ở đúng task, đúng harness, một model 2B có thể match model mạnh hơn nhiều. Đây là tín hiệu cho thấy việc over-invest vào model lớn mà bỏ qua harness design là một quyết định kỹ thuật thiếu thông tin.
Tất nhiên, nghiên cứu này có giới hạn rõ ràng: mỗi tier chỉ có 1 model đại diện. Kết quả nên được đọc là model-specific observations, không phải quy luật universal. Cần nhiều hơn để có thể kết luận mạnh về toàn bộ tier. Nhưng hướng đi thì rõ ràng.
Kết
"It's Not the Capability" là tiêu đề được chọn kỹ - không phải clickbait mà là luận điểm. Capability không phải là biến quyết định duy nhất. Harness sensitivity, model type, và interaction giữa hai thứ đó mới là nơi kết quả thực sự được tạo ra.
Nếu bạn đang build AI agent và câu hỏi hàng đầu của bạn vẫn là "dùng model nào" - có lẽ đã đến lúc chuyển câu hỏi sang "harness của mình phù hợp với model nào, và tại sao".
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ