
- Mỗi coding agent quên hết context sau khi session kết thúc - đây không phải lỗi của bạn, mà là giới hạn kiến trúc cơ bản.
- Context window 1M token không giải quyết được vì context rot bắt đầu suy giảm từ 200K-400K tokens.
- Agentmemory (20k GitHub Stars, Apache 2.0) là memory engine chuyên cho coding agents: auto-capture 12 hooks, hybrid search BM25+Vector+Graph, giảm 92% token so với CLAUDE.md.
- Đây là P1 - kiến trúc và vấn đề nền tảng.
TL;DR
Mỗi lần mở Claude Code hay Codex, bạn lại phải giải thích lại stack, kiến trúc, những quyết định thiết kế từ tuần trước. Nguyên nhân không phải model kém - mà là context window, dù có đến 1M token, vẫn không phải bộ nhớ dài hạn. Agentmemory là open-source engine giải quyết đúng vấn đề này: tự động capture mọi thứ agent làm, compress thành database có thể search, và inject đúng context khi session mới bắt đầu - không cần bạn làm gì cả. Tính đến cuối tháng 5/2026, project đạt 20k stars trên GitHub và là memory engine cho coding agents được benchmark cao nhất hiện tại (R@5: 95.2% trên LongMemEval-S).
Đây là phần 1 trong series 3 phần, tập trung vào vấn đề và kiến trúc. Phần 2 đi sâu vào cài đặt và cách dùng. Phần 3 là benchmark, 5 bẫy thường gặp, và kết luận thực tế.
Vòng lặp mệt mỏi mỗi buổi sáng
Kịch bản này chắc bạn không lạ: mở Claude Code lên, gõ "tiếp tục từ chỗ hôm qua", nhận về "Bạn có thể tóm tắt lại project cho tôi không?" Rồi lại mất 5-10 phút giải thích architecture, stack, những cái đã quyết định, những bug đã fix.
Ngày hôm qua bạn đã tốn 2 tiếng debug cái N+1 query trong Supabase, cuối cùng tìm ra cách fix bằng eager loading. Hôm nay Claude Code không biết chuyện đó. Bạn mô tả lại vấn đề, nó lại đề xuất cách fix tương tự - rồi bạn lại phải giải thích "thử cái này rồi, không được".
Không phải lỗi của bạn. Không phải lỗi của model. Đây là giới hạn cơ bản của cách AI coding agents được thiết kế hiện tại.
Một developer đã viết:
"Only 30 days of your Claude Code session history is saved on your computer by default, you have to set that longer if you want to have memory over all of them."
30 ngày lưu trữ - nhưng là lưu dạng chuỗi văn bản, không phải dạng context có thể gọi ra được. Bạn có thể đọc lại, nhưng model không tự lấy ra được. Đây là hai thứ rất khác nhau.
Context window lớn không bằng bộ nhớ tốt
Vào tháng 5/2026, các model hàng đầu có context window như sau:
- Claude Opus 4.7: 1M token (mở rộng từ 200K)
- GPT-5.5: 1M token (API) / 400K trên Codex CLI
- Gemini 3.1 Pro: 1M token
Tính theo tiếng Việt, 1M token tương đương khoảng 1.4 triệu chữ - đủ chứa nhiều cuốn sách. Nhìn con số này, dễ nghĩ "vậy thì nhét hết vào context là xong".
Nhưng Anthropic đã viết thẳng trong engineering blog của mình:
"Khi số lượng token trong context window tăng lên, khả năng của model trong việc recall chính xác thông tin từ context đó giảm xuống."
Đây là hiện tượng gọi là context rot - bộ nhớ bị "thối rữa" khi context quá dài. Trong thực tế, sự suy giảm này bắt đầu rõ rệt từ khoảng 200K-400K token. Bạn nhét 1M token vào, nhưng model chỉ thực sự "nhớ tốt" trong khoảng 200K đầu.
Anthropic mô tả context như một tài nguyên có "attention budget" - tương tự giới hạn working memory của con người. Mỗi token mới đưa vào đều tiêu thụ budget đó. via Anthropic Engineering
Kết luận: physical size tăng ≠ precision tăng. Cuộc đua về context window không giải quyết được vấn đề nhớ dài hạn.
Claude Code và vụ sụp đổ tháng 4/2026
Để thấy context rot không phải chuyện lý thuyết, hãy nhìn vào sự kiện thực tế xảy ra đầu năm 2026.
Ngày 23/4/2026, Anthropic công bố postmortem chính thức về một bug nghiêm trọng đã âm thầm ảnh hưởng Claude Code suốt nhiều tuần. via Anthropic
Ngày 26/3, họ deploy một thay đổi: khi session idle hơn 1 tiếng, xóa phần thinking cũ để giảm latency khi user resume. Ý tưởng hợp lý. Nhưng implementation có bug - thay vì chỉ xóa một lần, nó xóa thinking trên mọi turn tiếp theo trong suốt session đó.
Kết quả:
- Tháng 1/2026: median thinking length = 2.200 ký tự
- Tháng 3/2026: median thinking length = 600 ký tự
- Giảm 73% - trong 1 tháng
Claude Code vẫn chạy, vẫn dùng tool, vẫn ra output. Nhưng nó làm vậy mà không biết tại sao - không nhớ reasoning của turn trước. Users báo cáo model trở nên lặp lại, hay quên, đưa ra quyết định kỳ lạ. Nhiều người cảm thấy bị "gaslit" vì công ty không thừa nhận ngay.
Bug được fix ngày 10/4. Nhưng bài học quan trọng hơn fix: context rot không chỉ do user dùng sai - platform-side changes cũng có thể gây ra bất cứ lúc nào. CLAUDE.md dù có viết kỹ đến đâu cũng không chống được.
Agentmemory là gì - và tại sao khác biệt
Tháng 5/2026, một project tên Agentmemory (GitHub: rohitg00/agentmemory) bắt đầu viral trong cộng đồng developer. Từ ~4.000 stars ngày 10/5, lên 8.800 stars ngày 15/5, và tính đến cuối tháng đã vượt 20.000 stars.
License: Apache 2.0. Ngôn ngữ: TypeScript (82.4%). Không gửi dữ liệu ra ngoài - hoàn toàn self-hosted trên máy của bạn.
Lead developer Rohit Ghumare (@ghumare64) mô tả triết lý cốt lõi trong một dòng:
"Built this with agentmemory: persistent memory for AI coding agents. Same core idea: stop re-deriving, start compiling."
"Stop re-deriving, start compiling" - đây là điểm khác biệt về mặt triết học so với CLAUDE.md hay auto-memory của Claude Code.
CLAUDE.md là "input để AI tự suy luận lại mỗi session" - mỗi lần bắt đầu, model đọc lại file đó, tự diễn giải lại ngữ cảnh, rồi lại quên. Agentmemory thay vòng lặp "suy luận rồi quên" đó bằng lớp bộ nhớ đã được compile - lưu trữ ngoài context window, chỉ inject phần liên quan khi cần.
Kiến trúc 3 lớp của Agentmemory
Agentmemory hoạt động theo pipeline 3 bước:
Lớp 1: Capture (thu thập tự động)
12 lifecycle hooks tích hợp sẵn cho Claude Code (22 hooks cho OpenCode) tự động ghi lại mọi thứ agent làm - không cần bạn gọi memory_save() thủ công.
Ví dụ những gì được capture:
- SessionStart: project path, session ID
- UserPromptSubmit: prompt của user (đã qua privacy filter)
- PostToolUse: tên tool, input, output
- PostToolUseFailure: error context
- Stop: tóm tắt cuối session
- PreCompact: inject memory trước khi compaction
Điểm mấu chốt: zero manual effort. Bạn không phải quyết định "cái này có đáng ghi nhớ không". Agentmemory tự làm.
Lớp 2: Pipeline (xử lý)
Raw observations được xử lý qua 3 bước: khử trùng lặp (dedup) → privacy filter tự động loại bỏ API key, password, PII → AI compression nén lại thành dạng semantic.
Privacy filter là lý do bạn không cần lo lắng về việc secrets bị lưu vào memory. Mọi thứ chứa API key, email, hay content trong tag <private> đều bị drop trước khi đến storage.
Lớp 3: Retrieval (tìm kiếm hybrid)
Đây là phần kỹ thuật nhất. Thay vì dùng một loại search, Agentmemory kết hợp 3 luồng song song:
- BM25: keyword matching với stemming và synonym expansion - tìm theo từ khóa chính xác
- Vector: cosine similarity trên dense embeddings - tìm theo nghĩa, không cần từ giống hệt
- Graph: knowledge graph traversal - tìm theo mối quan hệ giữa các entities
Ba luồng này được hợp nhất bằng Reciprocal Rank Fusion (RRF k=60) - một thuật toán đảm bảo nếu một luồng bỏ lọt kết quả, luồng kia sẽ bắt được. Kết quả được trả về với session-diversification (tối đa 3 kết quả từ mỗi session), tránh tình trạng cùng một session chiếm hết top results.
Trên benchmark LongMemEval-S (ICLR 2025, 500 câu hỏi): R@5 = 95.2%, R@10 = 98.6%, MRR = 88.2%. Latency p50: 14ms (chạy local SQLite nên nhanh).
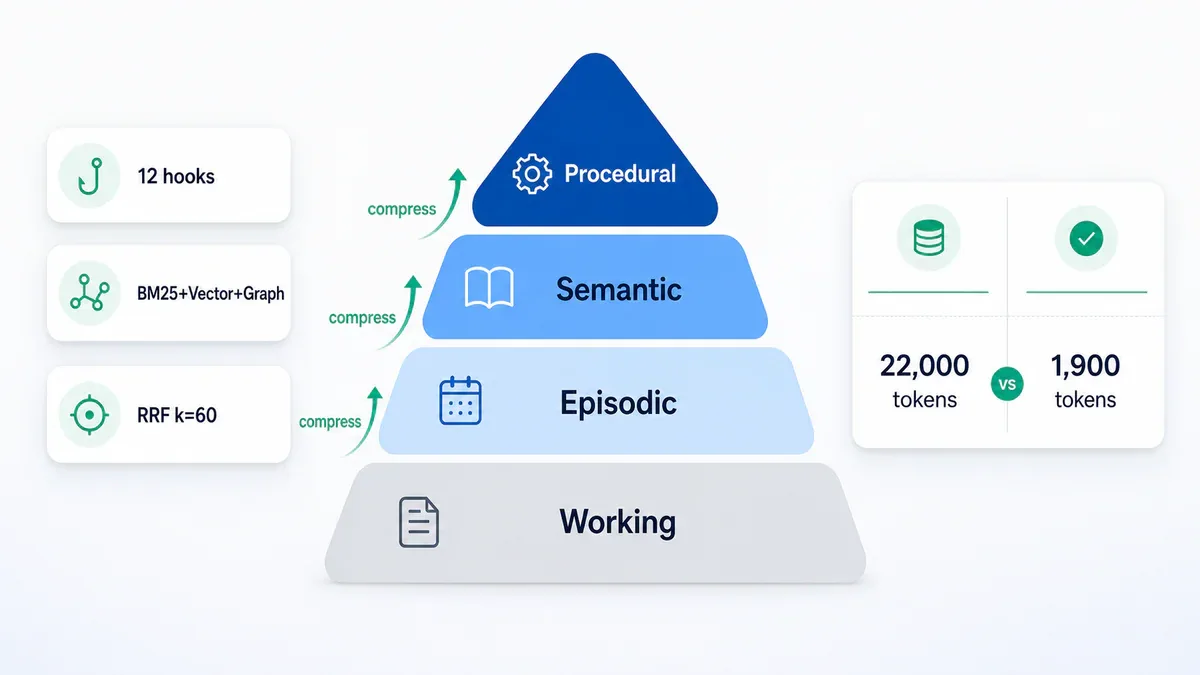
4 tầng bộ nhớ - thiết kế theo Ebbinghaus
Ngoài kiến trúc 3 lớp, Agentmemory có hệ thống phân cấp bộ nhớ 4 tầng lấy cảm hứng từ nghiên cứu tâm lý học của Hermann Ebbinghaus:
| Tầng | Nội dung | Mô tả |
|---|---|---|
| Working | Ngắn hạn | Tool execution logs, error contexts, command outputs từ session hiện tại |
| Episodic | Lịch sử session | "Điều gì đã xảy ra" - tóm tắt từng session |
| Semantic | Kiến thức trích xuất | "Tôi biết điều gì" - patterns, facts rút ra từ nhiều sessions |
| Procedural | Quy trình | "Tôi làm như thế nào" - workflows đã được tự động hóa |
Cơ chế hoạt động: khi session kết thúc (Stop hook), pipeline compress Working → Episodic. Theo thời gian, nhiều Episodic sessions được distill thành Semantic. Những pattern lặp lại trong Semantic được "compile" thành Procedural.
Quan trọng hơn: bộ nhớ được truy cập thường xuyên sẽ được củng cố. Bộ nhớ không được dùng sẽ decay theo đường cong Ebbinghaus và tự động bị xóa. Đây là lý do tại sao Agentmemory không bị "phình" ra vô hạn dù bạn dùng nhiều năm.
Session bắt đầu với 2.000 tokens context budget mặc định - đủ để inject "bộ nhớ liên quan" mà không tốn nhiều. So sánh: CLAUDE.md thủ công có thể ngốn 22.000+ tokens khi có 240 observations. Agentmemory giảm con số này xuống còn ~1.900 tokens/session - giảm 92%.
Kết - Phần 1
Vấn đề context rot là có thật, được Anthropic chính thức thừa nhận, và không phải lỗi của bạn khi dùng AI coding agents. Context window 1M token không giải quyết được, vì physical size ≠ recall precision.
Agentmemory giải quyết ở một layer khác: thay vì mở rộng context window, nó xây dựng external memory layer hoạt động như "bộ não thứ hai" - lưu bên ngoài context, chỉ gọi vào khi cần, và tự động "trưởng thành" theo thời gian giống bộ nhớ người.
Phần 2: Hướng dẫn cài đặt đầy đủ (Claude Code, Codex CLI, Cursor, Cline) + 3 action cơ bản + workflow thực tế cho người dùng đa tool.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ