
- Sim2Reason (CMU + Lambda) biến mô phỏng vật lý thành cỗ máy sinh dữ liệu QA vô hạn để fine-tune LLM bằng RL.
- Kết quả: +17.9pp trên JEEBench, +5-10pp trên IPhO, zero-shot sang bài thật, không cần một dòng chú thích người viết.
TL;DR
Nhóm CMU + Lambda vừa công bố Sim2Reason (arXiv 2604.11805, 13/04/2026): thay vì đi săn dữ liệu QA vật lý do người viết, họ dùng thẳng MuJoCo làm máy sinh bài tập. Một domain-specific language (DSL) random hoá scene graph, mô phỏng chạy ra đáp án, LLM được fine-tune bằng reinforcement learning trên dữ liệu tổng hợp đó.
Hệ quả rất cụ thể: Qwen2.5-32B bật từ 34.38% lên 52.28% trên JEEBench (+17.9pp), IPhO Mechanics cải thiện +5 đến +10 điểm xuyên suốt các kích thước mô hình, và đáng chú ý nhất — mô hình còn cải thiện cả ở những bài vật lý mà MuJoCo không mô phỏng được. Code mở nguồn.
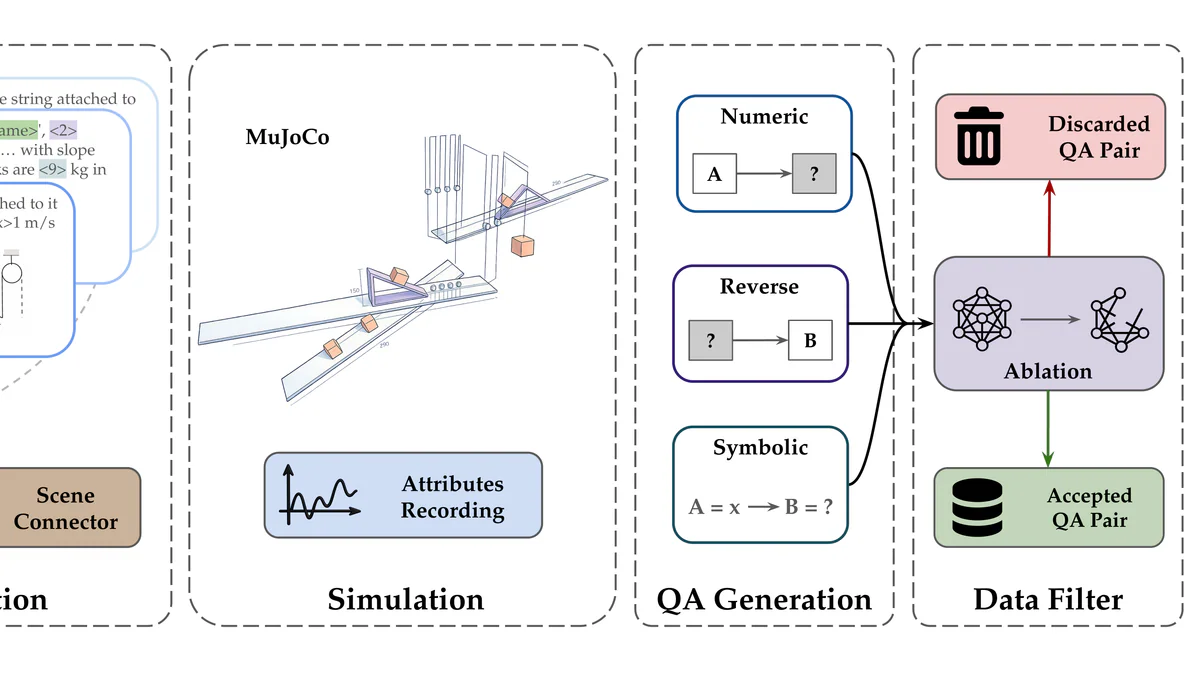
Có gì mới
LLM reasoning bùng nổ nhờ DeepSeek-R1, nhưng gần như toàn bộ tiến bộ đó đến từ QA pairs internet — tức là toán. Theo AlphaSignal, dưới 2% training pairs của DeepSeek-R1 chạm đến STEM. Với vật lý, bộ dữ liệu QA chất lượng cao đơn giản là không đủ.
Sim2Reason chặt đứt phụ thuộc vào data người. Ý tưởng gọn: mô phỏng vật lý đã encode sẵn các định luật tự nhiên, tại sao không lấy nó làm giáo viên?
Pipeline 3 phần:
- Random Scene Generation: DSL (YAML) sinh scene graph trong MuJoCo. Chỉ random các tham số thực sự ảnh hưởng tới động lực học — khối lượng, ma sát, góc nghiêng. Những thứ kiểu độ dài tuyệt đối của sợi dây pulley bị loại khỏi random vì không đổi vật lý.
- Auto QA Generation: scene được mô tả bằng natural language, câu hỏi hình thành bằng cách chọn ngẫu nhiên một đại lượng vật lý của một vật thể, đáp án tính bằng việc cho simulation chạy.
- RL Fine-tuning: dùng dữ liệu tổng hợp đó chạy reinforcement learning trên Qwen2.5 và Qwen3.
Ba kiểu câu hỏi được hỗ trợ: Numeric (hỏi giá trị), Reverse (cho kết quả, hỏi tham số), Symbolic (biểu diễn đại lượng bằng ký hiệu, giải mối quan hệ).
Tại sao nó quan trọng
Đây là lần đầu có một recipe rõ ràng chứng minh simulator có thể thay thế dữ liệu QA người viết cho một domain reasoning khó. Hai hệ quả:
- Bottleneck dữ liệu biến mất. Bạn không cần săn lùng 10k bài vật lý curated nữa — chạy MuJoCo là ra data.
- Chi phí benchmarking rơi xuống đất. Task tổng hợp có tương quan mạnh với IPhO ở 6 mô hình frontier (Claude Sonnet 4.5, GPT-5 Nano/Mini/High, Gemini 2.5 Flash, Qwen3-30B). Muốn đánh giá khả năng suy luận vật lý của một model mới? Không cần thuê expert chấm điểm — chạy synthetic là đủ predict.
Số liệu kỹ thuật
Qwen2.5 trên IPhO Mechanics (baseline → RL):
| Model | Baseline | After RL | Δ |
|---|---|---|---|
| Qwen2.5-3B | 5.68% | 13.15% | +7.5 |
| Qwen2.5-7B | 10.7% | 15.1% | +4.4 |
| Qwen2.5-14B | 16.07% | 20.45% | +4.4 |
| Qwen2.5-32B | 19.8% | 25.2% | +5.4 |
| Qwen3-30B | 35.6% | 40.0% | +4.4 |
Trên synthetic task riêng (Qwen2.5-32B): Numeric 8.9% → 21.9% (+13.0), Symbolic 5.6% → 10.4% (+4.8) — tức là RL trên simulator không chỉ giúp mô hình giải bài mô phỏng mà còn dịch chuyển thói quen suy luận.
Theo mô tả của nhóm tác giả, sau fine-tune: "Lỗi số học biến mất gần hết, và quan trọng hơn, các phương trình được chọn dựa trên setup vật lý chứ không áp dụng máy móc".
So với cách cũ
Qwen2.5-32B Instruct trên benchmark thật (baseline → RL):
| Benchmark | Baseline | After RL | Δ |
|---|---|---|---|
| JEEBench | 34.38% | 52.28% | +17.90 |
| PHYSICS | 39.42% | 43.09% | +3.67 |
| OlympiadBench | 41.41% | 44.53% | +3.12 |
| AIME 25 | 10.83% | 12.50% | +1.67 |
| MATH 500 | 78.4% | 82.8% | +4.4 |
Điểm đáng chú ý: JEEBench gồm các bài kỳ thi đại học Ấn Độ, 100% do người viết, có mặt trên internet từ lâu. Một mô hình chỉ được RL trên scene MuJoCo random vẫn nhảy +17.9 điểm ở đây — tức là kỹ năng học được từ mô phỏng tổng quát hoá sang bài thi do người viết.
Ứng dụng

- Nhóm nghiên cứu LLM: có recipe cụ thể để nâng physical reasoning mà không cần dataset người viết.
- Đánh giá mô hình rẻ: dùng synthetic Sim2Reason làm proxy IPhO — rẻ, nhanh, reproducible.
- Mở rộng sang domain khác: recipe DSL + simulator + RL có thể copy sang chemistry engine, fluid dynamics, hoặc bất kỳ môn nào có simulator đáng tin.
Giới hạn & chi phí
- Domain khoá chặt: hiện chỉ chạy trên những gì MuJoCo mô phỏng được (cơ học cứng, pulley, lò xo, đạn đạo, va chạm). Quang học, điện từ, lượng tử — chưa trong scope trực tiếp.
- Ba kiểu câu hỏi: numeric, reverse, symbolic. Câu hỏi thiết kế thí nghiệm hay giải thích hiện tượng kiểu essay chưa có.
- Chi phí: code mã nguồn mở, miễn phí. Chi phí thực tế nằm ở RL compute cho fine-tune Qwen family — không công khai con số.
- Peer review: hiện là preprint arXiv, chưa qua review chính thức.
Tiếp theo là gì
Tác giả chưa công bố roadmap. Những hướng tự nhiên để theo dõi: mở rộng DSL sang electromagnetism / fluids, tích hợp với vision LLM để đọc đề có hình vẽ (IPhO phần lớn có sketch), và áp dụng cùng công thức sang chemistry simulator.
Với những ai muốn thử: code đã mở, Qwen2.5/3 là backbone có sẵn trọng số, MuJoCo free cho nghiên cứu. Chi phí entry gần như chỉ còn GPU cho RL.
Nguồn: sim2reason.github.io, arXiv 2604.11805, AlphaSignal.


