
- Tại Google Cloud Next 2026, Google giới thiệu thế hệ TPU thứ 8 với hai chip riêng biệt: TPU 8t cho training (121 FP4 exaflops/pod, nhanh gấp 2.8x Ironwood) và TPU 8i cho inference (1,152 chip/pod, tối ưu cho agent swarms).
- Đây là lần đầu Google tách hai workload này ra phần cứng chuyên biệt.
TL;DR
Google vừa công bố thế hệ TPU thứ 8 tại Google Cloud Next 2026 (Las Vegas, 22–24/04/2026). Lần đầu tiên, Google tách chip AI thành hai dòng riêng: TPU 8t (training, codename Sunfish, đồng thiết kế với Broadcom) và TPU 8i (inference, codename Zebrafish, đồng thiết kế với MediaTek). TPU 8t đạt 121 FP4 exaflops/pod (~2.8x Ironwood), TPU 8i đóng gói 1,152 chip/pod với 384 MB SRAM trên mỗi chip — tối ưu cho các “swarm” hàng triệu AI agent chạy đồng thời.

What’s new
Suốt 10 năm qua, mỗi thế hệ TPU đều là một chip “vạn năng”: vừa train model vừa phục vụ inference. Với thế hệ 8, Amin Vahdat (SVP & Chief Technologist, AI & Infrastructure của Google) nói thẳng: khi AI agent bùng nổ, hãy để mỗi chip tập trung vào một việc.
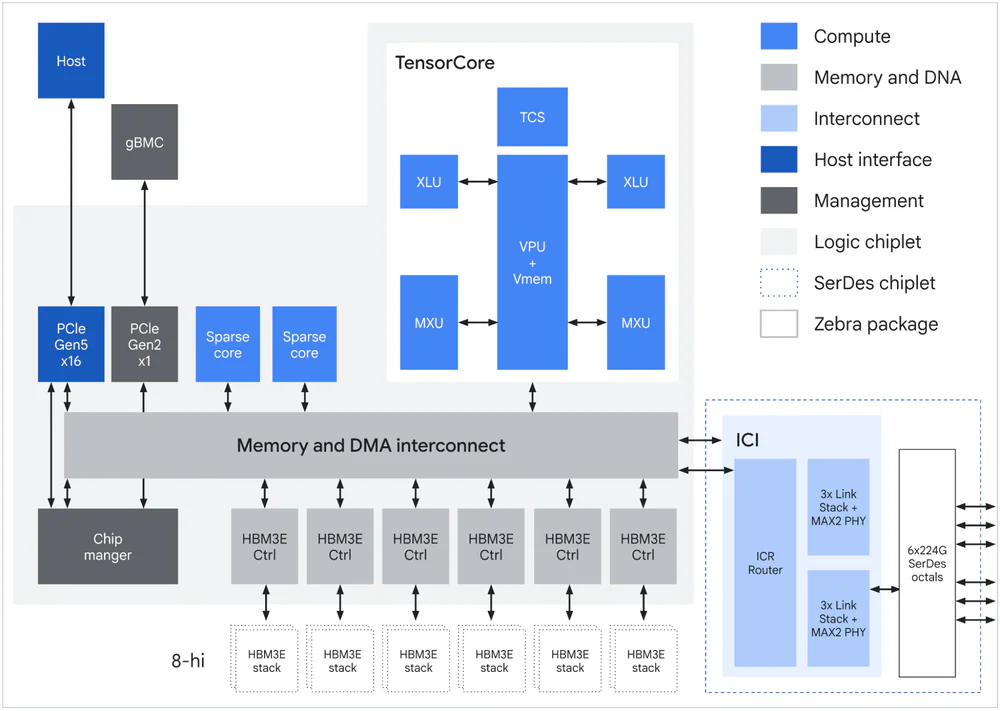
- TPU 8t: thiết kế cho pre-training ở quy mô frontier model — superpod 9,600 chip, topology 3D torus, native FP4, SparseCore cho embedding, TPUDirect RDMA + TPU Direct Storage.
- TPU 8i: thiết kế cho sampling, serving và reasoning agent — pod 1,152 chip, topology Boardfly mới (lấy cảm hứng Dragonfly), Collectives Acceleration Engine (CAE) thay thế 4 SparseCore còn lại 2 Tensor Core + 1 CAE trên chiplet.
- Cả hai chip dùng chung Arm-based Axion CPU làm host, gấp đôi số CPU host/server so với Ironwood.
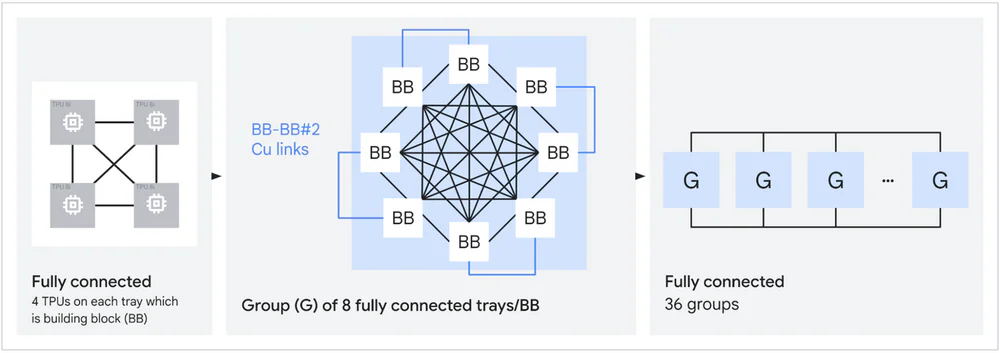
- Đi kèm là Virgo Network — fabric scale-out mới có thể nối 134,000 chip trong một data center và hơn 1 triệu chip TPU 8t xuyên nhiều data center cho các training cluster cỡ lớn nhất thế giới.
Why it matters
Training và inference bị đẩy xa nhau bởi workload agentic. Training cần throughput thô và bandwidth khổng lồ giữa hàng chục nghìn chip; inference cần latency thấp, SRAM lớn để giữ KV cache và “short-term memory” của agent ngay trên silicon. Một chip gánh cả hai nghĩa là luôn compromise.
Microsoft dự báo 1.3 tỷ AI agent sẽ vận hành vào 2028. Với qui mô đó, chip inference chuyên dụng không còn là lựa chọn hay — mà là điều kiện sống còn về kinh tế vận hành. Google tuyên bố TPU 8i rẻ hơn 80% trên mỗi đơn vị hiệu năng so với Ironwood — một con số thay đổi hoàn toàn bài toán unit economics cho các công ty chạy agent ở quy mô lớn.
Technical facts
| Thông số | TPU 8t (training) | TPU 8i (inference) |
|---|---|---|
| Chip/pod | 9,600 | 1,152 |
| Compute/pod | 121 FP4 exaflops | — |
| Peak FP4 PFLOPs/chip | 12.6 | 10.1 |
| HBM/chip | 216 GB | 288 GB |
| On-chip SRAM | 128 MB | 384 MB (3x Ironwood) |
| HBM bandwidth | 6,528 GB/s | 8,601 GB/s (~1.3x 8t) |
| Chip-to-chip (ICI) | 19.2 Tbit/s scale-up | 19.2 Tb/s (doubled) |
| Topology | 3D torus | Boardfly |
| CPU host | Arm Axion | Arm Axion (2x host/server) |
Một số con số đáng chú ý:
- 2 petabytes HBM trên mỗi superpod TPU 8t.
- TPUDirect Storage (với Managed Lustre 10T): truy cập storage nhanh 10x so với Ironwood bằng cách bypass CPU host và DRAM.
- Virgo Network: 47 petabits/sec bi-sectional bandwidth trong một fabric, 1.6 triệu ExaFlops near-linear scaling.
- Target goodput > 97% cho training cluster (thời gian compute có ích trên tổng uptime).
Comparison vs Ironwood
Google không công bố benchmark trực tiếp với Nvidia, chỉ so với thế hệ trước.
| Metric | Ironwood (TPU v7) | TPU 8t | TPU 8i |
|---|---|---|---|
| Compute/pod | 42.5 exaflops | 121 exaflops (~2.8x) | — |
| HBM/chip | 192 GB | 216 GB | 288 GB |
| On-chip SRAM | baseline | 128 MB | 384 MB (3x) |
| Chip/pod (inference) | 256 | — | 1,152 (4.5x) |
| Perf/$ large-scale training | baseline | +2.7x | — |
| Perf/$ inference | baseline | — | +80% |
| Perf/watt | baseline | 2x | 2x |
Cái “đáng sợ” nhất là Boardfly. Với một pod 1,024 chip, 3D torus cần 16 hops để một packet đi từ góc này sang góc kia; Boardfly chỉ cần 7 hops — giảm 56% đường kính mạng, dịch sang 50% latency thấp hơn cho các workload all-to-all điển hình của MoE và reasoning model.
Use cases
- Google DeepMind dùng 8t/8i để train và serve world model như Genie 3 — cho phép hàng triệu agent luyện tập trong môi trường giả lập.
- Anthropic ký hợp đồng multi-gigawatt với Google + Broadcom dùng TPU để scale Claude.
- Citadel Securities tuyên bố giảm 30% chi phí hệ thống trading nhờ chạy quant research trên TPU.
- 17/17 phòng thí nghiệm quốc gia của U.S. Department of Energy chạy phần mềm “AI co-scientist” trên TPU.
- Với 134,000 chip trong một data center, enterprise có data-residency requirement có thể train frontier model tại chỗ — một điểm bán quan trọng ở EU và khu vực regulated.
Limitations & pricing
- Giá cụ thể chưa công bố — Google chỉ nói về perf-per-dollar vs Ironwood.
- GA “later this year” (nửa cuối 2026), không có ngày chính xác.
- Google tránh so sánh trực tiếp với Nvidia — khách hàng muốn numbers vs H100/B200/Groq sẽ phải tự benchmark.
- Vendor lock-in vẫn là câu chuyện thực tế: một khi đã vào stack JAX + Pathways + AI Hypercomputer, rời sang Nvidia tốn kém.
- Ecosystem CUDA vẫn dẫn đầu — TPU mạnh nhất khi bạn sống trong GCP.
What’s next
Kiến trúc modular 8t/8i mở đường cho các cluster training >1 triệu chip xuyên data center. Google đang chạy nội bộ ở quy mô lớn cho Gemini; khách hàng cloud có thể dùng trong H2 2026. Tin rò rỉ từ supply chain cho biết thế hệ post-TPUv8 có thể có sự tham gia của Marvell, bên cạnh Broadcom và MediaTek.
Nguồn: Google Cloud Blog, CNBC, ITPro, Techzine.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ