
- Benchmark mới nhất test 10.000 tài liệu SEC qua 5 LLM lớn cho thấy Reflexive đạt F1 cao nhất nhưng tốn gấp 2.3 lần chi phí.
- Hierarchical Supervisor là lựa chọn tốt nhất cho hầu hết workload production với 98.5% độ chính xác tại 60.7% chi phí.
- Parallel nhanh hơn Sequential tới 1.84 lần nhưng là pattern kém hiệu quả token nhất.
- Gartner dự báo hơn 40% pilot AI agent sẽ bị huỷ vào 2027 - kiến trúc mới là nguyên nhân.
TL;DR
Thêm agent không tự động tốt hơn. Nghiên cứu của Siddhant Kulkarni và Yukta Kulkarni (arXiv:2603.22651, tháng 3/2026) benchmark 4 kiến trúc multi-agent trên 10.000 tài liệu SEC qua 5 LLM cho thấy:
Reflexive đạt F1 cao nhất (0.943) nhưng tốn 2.3x chi phí và p99 latency lên tới 247 giây
Hierarchical Supervisor cho tỷ lệ cost-accuracy tốt nhất - 98.5% F1 của Reflexive tại 60.7% chi phí
Parallel nhanh nhất (1.84x so với Sequential) nhưng kém hiệu quả token nhất do xử lý dư thừa
Sequential đơn giản nhất, ổn định nhất khi scale lên 100.000 tài liệu/ngày
Khi kết hợp semantic caching, model routing và adaptive retry, Hierarchical-Optimized đạt F1=0.924 tại chỉ 1.15x chi phí baseline
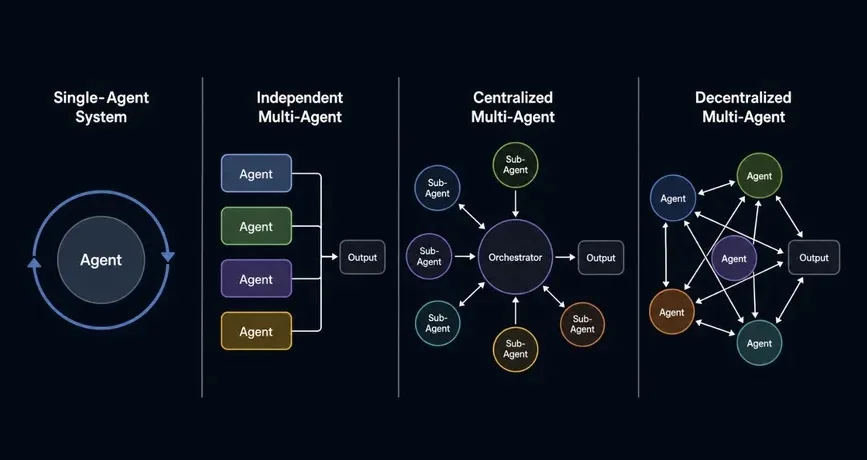
Khi một agent không đủ
Workflow LLM đơn giản hoạt động tốt khi nhiệm vụ nhỏ và rõ ràng. Nhưng khi task phức tạp lên - tài liệu dài, nhiều domain khác nhau, yêu cầu kiểm tra chéo - một agent bắt đầu gặp vấn đề: context window bị giới hạn, risk hallucination tăng khi lý luận quá dài, không có cơ chế phát hiện lỗi tích hợp.
Multi-agent giải quyết điều này bằng cách chia task thành các phần nhỏ hơn, mỗi agent chuyên hoá một việc. Nhưng câu hỏi thực sự không phải là có nên dùng multi-agent không, mà là kết nối các agent đó theo cách nào. Đây chính là bài toán orchestration - và đây là nơi hầu hết hệ thống fail trong production.
Dữ liệu Princeton NLP cho biết một agent đơn được cấu hình tốt match hoặc vượt multi-agent trên 64% task benchmark khi được cung cấp cùng tool. Multi-agent chỉ thêm khoảng 2.1 điểm phần trăm accuracy - nhưng ở gấp đôi chi phí và 10-30 lần latency. Câu hỏi đầu tiên phải đặt ra: task này có thực sự cần nhiều agent không?
Benchmark với 10.000 tài liệu thực
Để so sánh 4 pattern trực tiếp, Kulkarni xây dựng một dataset gồm 10.000 hồ sơ SEC (4.000 bản 10-K, 4.000 bản 10-Q, 2.000 bản 8-K) và đặt mục tiêu trích xuất 25 trường dữ liệu trong 3 domain: chỉ số tài chính, cấu trúc quản trị và thù lao lãnh đạo.
5 LLM được test: GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Pro, Llama 3 70B và Mixtral 8x22B. Đánh giá theo 5 chiều: field-level F1, document-level accuracy, latency, cost per document và token efficiency.
Điều quan trọng: mọi kiến trúc dùng chung cùng một bộ agent nguyên tử (document parser, field extractor, table analyzer, cross-reference resolver, confidence scorer và output formatter). Điểm khác biệt là cách các agent đó được kết nối và điều phối.
Bốn pattern, bốn chiến lược
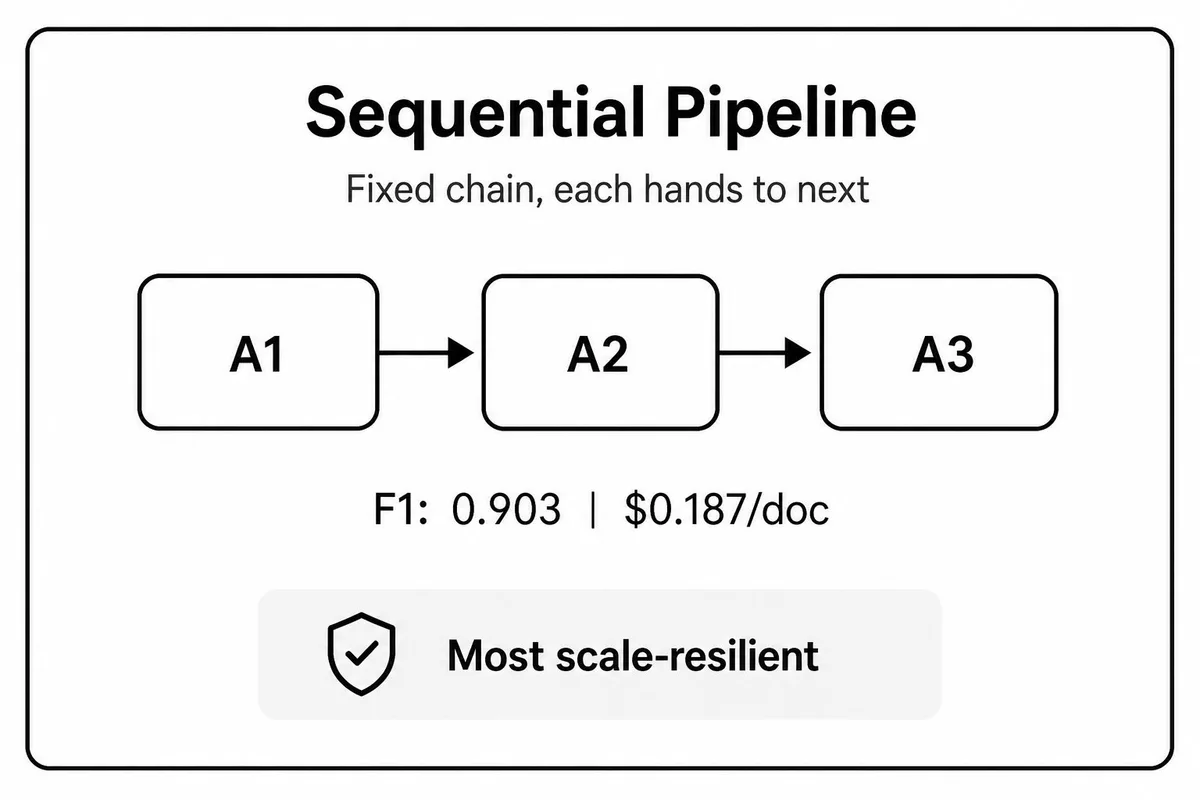
Sequential Pipeline - Mô hình đơn giản nhất: Agent A hoàn thành rồi chuyển context tích luỹ sang Agent B, B chuyển sang C. Thứ tự thực thi cố định, dễ debug, chi phí thấp nhất và ổn định nhất khi scale. Nhược điểm: token tăng dần theo chuỗi vì mỗi agent nhận toàn bộ context từ các bước trước. Khi Agent A trích xuất sai, Agent B và C đều kế thừa lỗi đó.
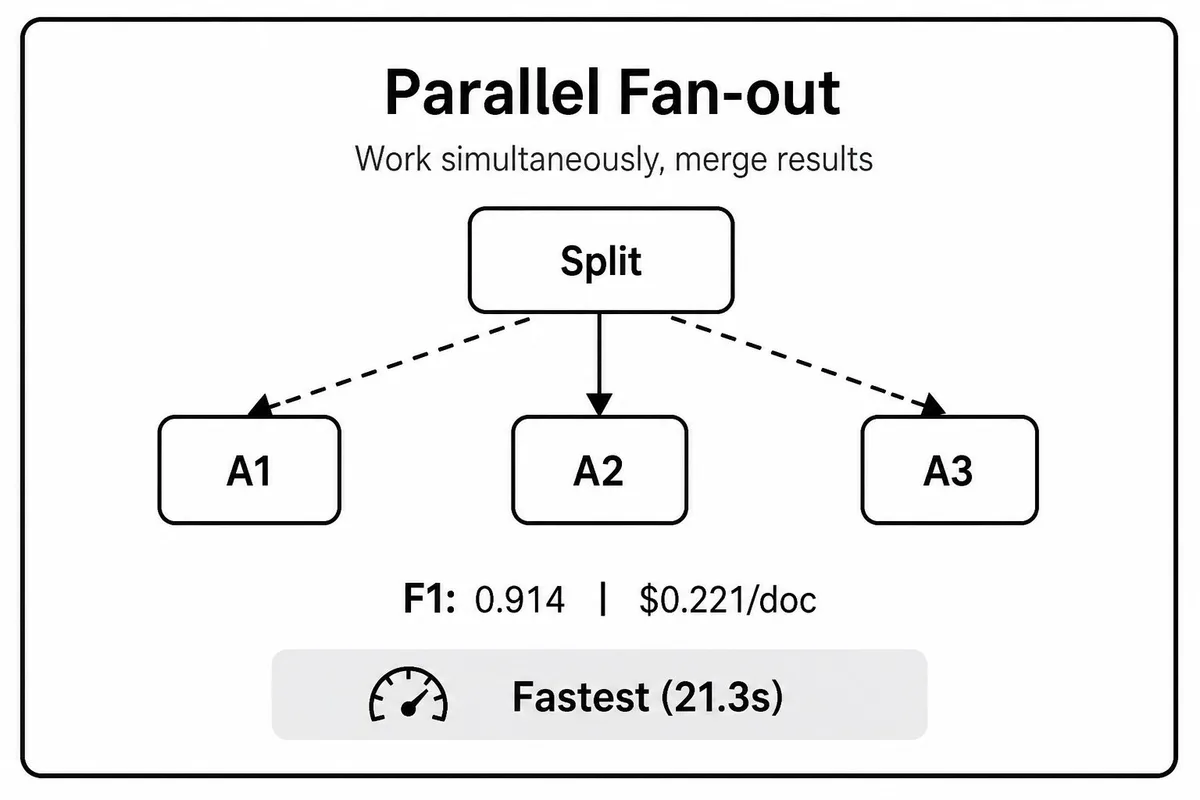
Parallel Fan-Out với Merge - Router gửi các task độc lập đến nhiều agent cùng lúc. Sau khi hoàn thành, một merge agent tổng hợp kết quả. Latency thấp nhất vì giới hạn bởi branch chậm nhất cộng với thời gian merge. Nhưng là pattern kém hiệu quả token nhất (2.43%) do các branch xử lý context chồng chéo nhau. Bước merge cũng có thể phức tạp khi các branch trả về kết quả mâu thuẫn.
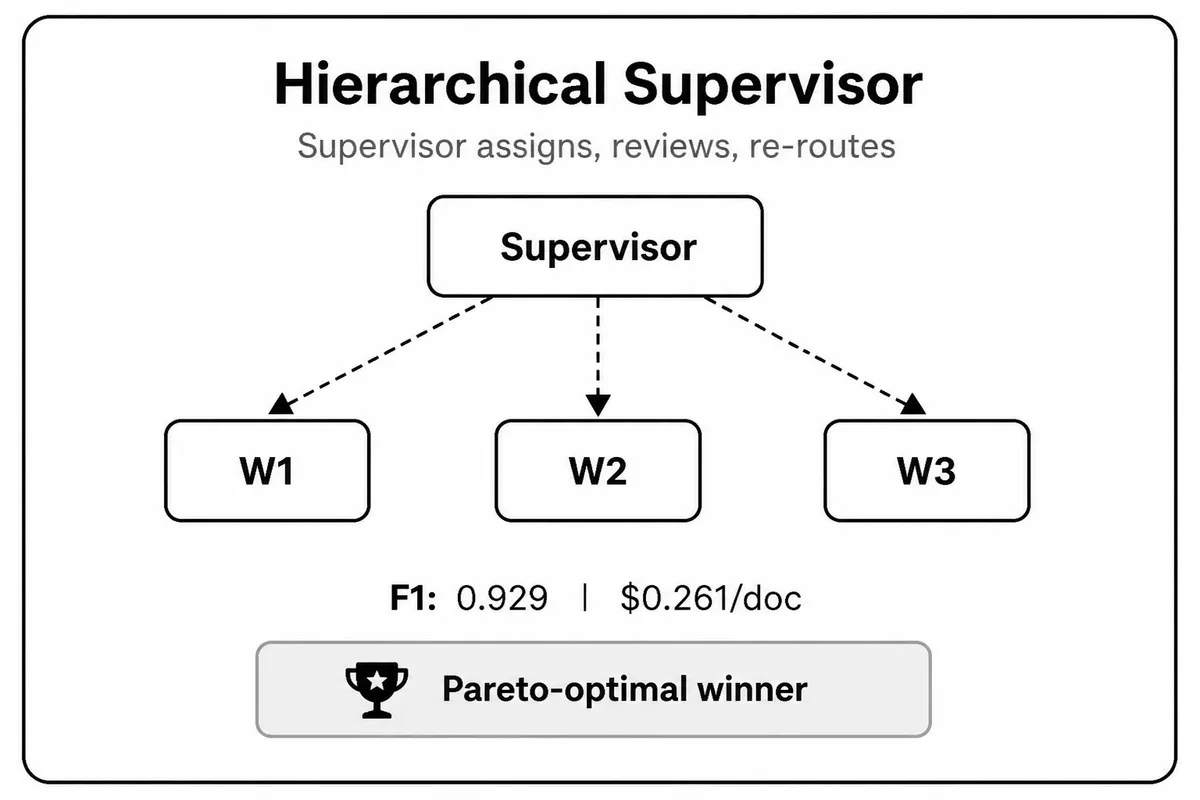
Hierarchical Supervisor-Worker - Supervisor phân công task cho các worker, nhận kết quả kèm confidence score. Nếu score thấp hơn ngưỡng, supervisor giao lại cho worker khác hoặc model mạnh hơn. Đây là kiến trúc linh hoạt nhất cho production: có thể route task đơn giản sang model rẻ và task phức tạp sang Claude hoặc GPT-4o. Chi phí token hiệu quả hơn vì mỗi worker chỉ nhận context cần thiết.
Reflexive Self-Correcting Loop - Agent trích xuất kết quả, một verifier agent độc lập đánh giá và phê bình. Nếu fail, vòng lặp tiếp tục tối đa 3 lần. Độ chính xác cao nhất do có cơ chế phát hiện lỗi tích hợp, nhưng chi phí cao nhất và latency không dự đoán được - p99 với Claude 3.5 Sonnet lên tới 247 giây, gấp 3.34 lần p50.
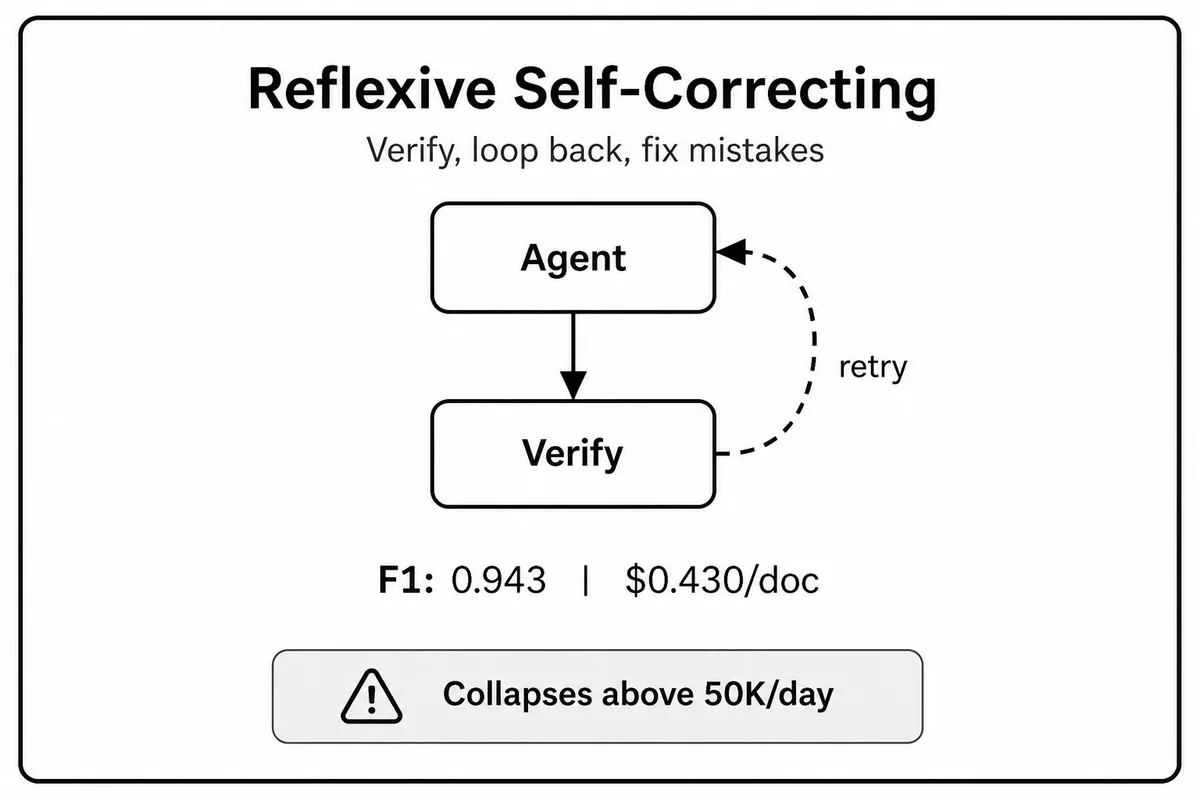
Số liệu thực tế (Claude 3.5 Sonnet)
Kiến trúc | F1 | Latency p50 | Chi phí/doc |
|---|---|---|---|
Sequential | 0.903 | 38.7s | $0.187 |
Parallel | 0.914 | 21.3s | $0.221 |
Hierarchical | 0.929 | 46.2s | $0.261 |
Reflexive | 0.943 | 74.1s | $0.430 |
Hierarchical-Optimized | 0.924 | 30.2s | $0.148 |
Khi scale lên 50.000 tài liệu/ngày trên cùng cluster, Reflexive tụt xuống dưới Hierarchical và tại 100.000 tài liệu/ngày trở thành kiến trúc kém nhất - vì correction loop tạo queuing delay khiến vòng lặp bị cắt ngắn bởi timeout. Sequential có độ suy giảm nhỏ nhất (chỉ 0.017 F1) từ 1K đến 100K docs/ngày.
Nên chọn pattern nào?
Hướng dẫn thực tế từ benchmark:
Sequential - task đơn giản (<10 trường), tài liệu ngắn, budget chặt, hoặc volume >75.000 docs/ngày
Parallel - latency là yêu cầu ưu tiên, các domain trích xuất độc lập nhau, workload bursty
Hierarchical - workload enterprise từ 10K-50K docs/ngày, cần cân bằng cost-accuracy; cũng là điểm khởi đầu tốt nhất cho hầu hết production
Reflexive - accuracy tuyệt đối là yêu cầu số 1, volume thấp (<10K docs/ngày), downstream process không chấp nhận lỗi
Nếu muốn tốt hơn nữa mà không bỏ thêm nhiều tiền: Hierarchical-Optimized (thêm semantic caching, 2-tier model routing và adaptive retry) cho F1=0.924 tại $0.148/doc - đây là cấu hình thực tế nhất của toàn bộ nghiên cứu.
Sự thật về production
Nghiên cứu 70 dự án agent thực tế của Hu Wei (arXiv:2604.18071) xác nhận điều mà nhiều team đã biết qua thực tiễn đắt giá: kiến trúc xung quanh model quan trọng không kém bản thân model. Model mạnh hơn không tự động tạo ra hệ thống an toàn hơn hay ổn định hơn.
5 failure mode phổ biến nhất trong production multi-agent:
Hallucination cascade - Agent A hallucinate, Agent B coi đó là sự thật đã xác nhận và xây tiếp lên đó
Context overflow - context window đầy, model âm thầm bỏ qua constraint cũ - không throw error
Unbounded loop - evaluator không đạt quality bar, retry vô hạn đốt hết API budget
Tool misuse - agent gọi tool với parameter sai format, interpret error message như content, retry lại với cùng parameter sai
Cascading timeout - một API chậm block cả pipeline, orchestrator retry trong khi các agent khác cũng timeout song song
Dữ liệu từ Camunda: 73% tổ chức có khoảng cách lớn giữa tầm nhìn và thực tế production với AI agent. Chỉ 11% use case thực sự đến được production. Gartner dự báo hơn 40% pilot sẽ bị huỷ vào 2027 - không phải vì model fail mà vì orchestration layer fail.
Tiếp theo
Các hướng nghiên cứu tiếp theo từ benchmark paper bao gồm dynamic architecture switching (tự phân loại complexity của document để chọn pattern phù hợp - ước tính đạt F1>0.935 tại <$0.180/doc), fine-tuned specialist model nhỏ hơn cho từng domain trích xuất cụ thể (60-70% task có thể xử lý bởi model nhỏ hơn mà không mất chất lượng), và streaming architecture cho phép trích xuất từ các section đầu trong khi section sau vẫn đang parse (giảm 40-60% latency cho tài liệu dài như 10-K).
Bức tranh lớn hơn: orchestration không chỉ là kết nối agent lại. Đó là thiết kế xung quanh các giới hạn thực của workload - cost, latency, accuracy, scale và failure recovery. Pattern ấn tượng trong demo có thể trở thành gánh nặng chi phí khi push vào production. Bắt đầu bằng pattern đơn giản nhất đủ đáp ứng yêu cầu, thêm hierarchy khi cần routing thông minh hơn, và chỉ thêm reflexive loop khi risk đủ cao để justify chi phí.
Via: arXiv:2603.22651 (Kulkarni & Kulkarni, tháng 3/2026), arXiv:2604.18071 (Hu Wei, tháng 4/2026), Azure AI Agent Design Patterns.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ