
- Trong 3 tháng, một research agent duy nhất ghi lại hơn 8.000 mảnh bằng chứng có cấu trúc trên 16 chủ đề, giúp toàn bộ 5 agent còn lại trong hệ thống bắt đầu mỗi ngày với nền tảng kiến thức tốt hơn.
- Điểm mấu chốt là scraping thô không phải research thật - nếu dữ liệu không có cấu trúc, các agent khác không dùng được.
- Research vault phân tách rõ ràng: raw input, finding, claim, verified knowledge và task là 4 thứ hoàn toàn khác nhau.
TL;DR
Phần lớn hệ thống multi-agent bắt đầu mỗi vòng lặp gần như từ đầu. Mỗi agent tự tìm thông tin, tự tóm tắt, rồi quên. Kết quả là output nhiều nhưng kiến thức không tích lũy.
Giải pháp là một research agent chuyên biệt đóng vai trò kho bằng chứng có cấu trúc cho toàn bộ hệ thống.
Sau 3 tháng vận hành, hệ thống của tác giả ghi nhận hơn 8.000 mảnh bằng chứng trên 16 chủ đề, với 2.631 claim records, 2.694 findings, và 2.694 source records - tất cả đều có trích dẫn gốc rõ ràng.
Đây không phải scraper. Đây là evidence operator - và sự khác biệt đó là tất cả.
Vấn đề: Agent của bạn không học hỏi theo thời gian
Một research agent điển hình hoạt động thế này: scrape web - tóm tắt - đăng digest - vòng tiếp theo bắt đầu gần như từ đầu, ngoại trừ một ghi chú ngắn.
Trông có vẻ năng suất vì output xuất hiện khắp nơi. Nhưng output không phải là bằng chứng tích lũy.
Một research agent thực sự phải có khả năng trả lời:
Chúng ta biết gì bây giờ mà trước đây chưa biết?
Claim nào vững, claim nào mới chỉ thú vị nhưng chưa đủ bằng chứng?
Nguồn và chủ đề nào thực sự hữu ích?
Niềm tin cũ nào đã lỗi thời?
Nếu các agent trong hệ thống của bạn không chia sẻ chung một evidence-base có cấu trúc, chúng không phải một hệ thống gắn kết - chúng chỉ là tập hợp các công cụ chạy song song.
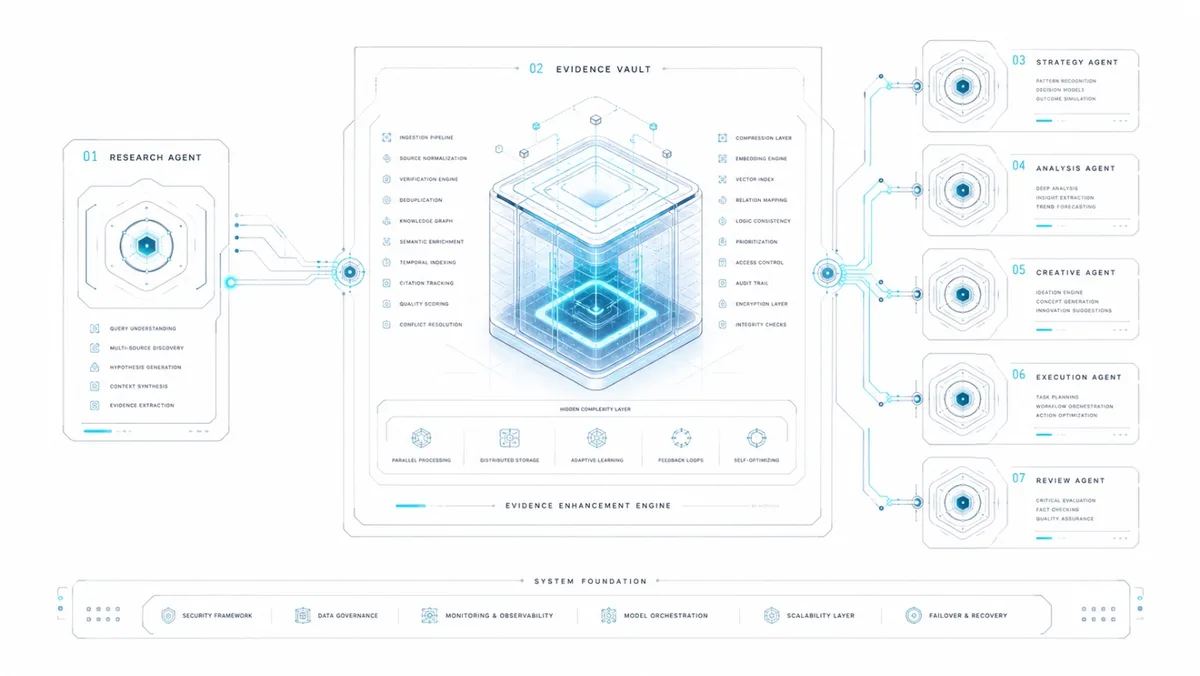
Scraper vs. Evidence Operator: Ranh giới quan trọng nhất
Phiên bản đầu tiên của research agent thường là feed reader. Phiên bản tốt hơn là thủ thư. Phiên bản tốt nhất là evidence operator.
Bỏ qua sự phân biệt này, research bot trở thành hallucination laundry: văn xuôi tự tin nhưng không phân biệt được đâu là quan sát, đâu là claim, đâu là sự thật đã được kiểm chứng.
Research vault giải quyết vấn đề này bằng một chuỗi phân tách cứng:
Raw input khác finding
Finding khác claim
Claim khác verified-knowledge
Verified-knowledge không tự động trở thành task
Task không tự động được approved
Chuỗi này giữ cho hệ thống trung thực. Không có nó, sự không chắc chắn sẽ lẫn vào văn xuôi tự tin.
Bên trong Research Vault: Con số thực tế
Sau 3 tháng vận hành, đây là những gì vault của tác giả chứa:
2.631 claim records: niềm tin ứng viên mà hệ thống đã trích xuất, phân cụm, và theo dõi theo thời gian
2.694 findings: tín hiệu quan sát từ docs, GitHub, feeds, X, và các collector khác
2.694 source evidence records: trail trích dẫn nối findings với URL, loại nguồn, đoạn trích, và timestamp
13 indexed dossiers: file chủ đề sống cho AI-agents, frontier-AI, crypto-rails, memory-orchestration, robotics
18 registered source surfaces: các collector lane mà research agent biết cách theo dõi
36 vault tools + profile wrapper scripts
Cadence refresh mỗi 6 tiếng + 3 delivery jobs mỗi ngày
Con số không phải là mục tiêu. Sự phân tách mới là điểm cốt lõi. Vault có không gian riêng cho mỗi giai đoạn thay vì flatten tất cả thành văn xuôi tự tin.
Kiến trúc thực tế: Mỗi agent nhận gì từ vault
Mọi agent trong hệ thống đều đọc từ research vault trước khi làm bất cứ điều gì:
Main agent: ra quyết định với context mới nhất
Coder agent: nhận docs và changelogs mới trước khi chạm vào code
Content agent: nhận angles, source trail, và timing
QA agent: nhận claims để cross-reference trước khi bất cứ thứ gì được ship
Research-agent không sở hữu toàn bộ máy. Nó thu thập bằng chứng, đánh giá trọng số, ghi nhớ, và routing. Phần còn lại của hệ thống quyết định phải làm gì với thông tin đó.
Khi research, judgment, building, và publishing sụp đổ vào một agent duy nhất, hệ thống bắt đầu xem mọi tín hiệu thú vị là action item. Research agent không được phép làm vậy.
Cấu trúc vault tối thiểu để bắt đầu
Nếu xây dựng lại từ đầu hôm nay, đây là cấu trúc folder tối thiểu cần thiết:
research-vault/
context/ # interest-profile.json, source-plan.md
config/ # collector-config.json, thresholds.json
knowledge/ # claims.jsonl, findings.jsonl, sources.jsonl
dossiers/ # ai_agents.md, frontier_ai.md, ...
queue/ # verification-review.md, buildroom-handoff.json
notes/ # operator-brief.md, daily-summary.md
raw/ # captures chua xu ly
wiki/ # concepts/ - linked pages
health/ # latest-health-check.md
ops/ # source-balance.md, operator-cockpit.htmlMột vài thư mục đáng chú ý mà hầu hết các setup đều bỏ qua:
decisions/: ghi lại quyết định nào được đưa ra, bởi ai, dựa trên bằng chứng gì. Research không có decision ledger sẽ quên lý do tại sao nó thay đổi hướng.
runs/: mỗi refresh để lại một receipt. Nếu không thể replay một run, không thể tin vào output của nó sau này.
raw/: lớp capture chưa xử lý, tách biệt khỏi knowledge/. Đây là sự khác biệt giữa agent tổng hợp và agent làm nhòe ranh giới.
Những gì research agent TUYỆT ĐỐI không được làm
Research agent có thể ảnh hưởng đến hệ thống nhưng không thể nắm tay lái. Danh sách cứng:
Không ra quyết định giao dịch
Không tự động đăng bài công khai
Không thực hiện giao dịch mua bán
Không cam kết partnership
Không chạm vào secrets hoặc auth surfaces
Không biến tín hiệu yếu thành approved task
Không giả vờ dữ liệu stale là fresh
Nó có thể: đọc shared-context, thu thập bằng chứng, đánh giá source-quality, viết dossiers và operator briefs, duy trì verification queue, routing implications đến các agent khác, và surface degraded collectors.
Bắt đầu từ đâu
Thứ tự build đúng:
Vault và identity trước: tạo SOUL.md định nghĩa vai trò, ranh giới, và core loop của agent
Source plan và knowledge ledgers: chọn nguồn theo nguyên tắc - ưu tiên nguồn thay đổi quyết định, không phải nguồn dễ crawl nhất
Verification queue và handoff lanes: claims yếu đi vào queue, không bị bỏ qua và cũng không được promote
Health checks và schedule: 6-hour refresh là baseline hợp lý
Để các agent khác tiêu thụ output: chỉ sau khi vault ổn định
Một agent thông thường trả lời prompt trước mặt nó. Agent tốt hơn nhớ những gì đã xảy ra. Research agent xây dựng evidence base khiến những prompt tương lai thông minh hơn trước khi chúng thậm chí được đặt ra.
Via: Research Vault - DEV Community, Architectural Design Decisions in AI Agent Harnesses.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ