
- Context engineering quyết định thứ gì vào model window, không phải cách viết prompt.
- Single-agent đánh bại multi-agent trong 64% benchmark task với chi phí thấp hơn 2x.
- Evals biến agent thành sản phẩm thật thay vì demo.
- MCP là giao thức chuẩn kết nối tool - học shape của nó, bỏ qua phần còn lại.
TL;DR
Model AI thay đổi mỗi tuần. Kỹ năng prompting lỗi thời sau mỗi release. Nhưng 7 primitives này - context engineering, tool design, evals, single-agent first, file system as state, MCP, sandboxing - vẫn còn giá trị bất kể bạn đang dùng Claude, GPT hay bất cứ model nào ra mắt tháng tới.
Đây không phải tutorial. Đây là map để bạn biết mình đang học đúng thứ.
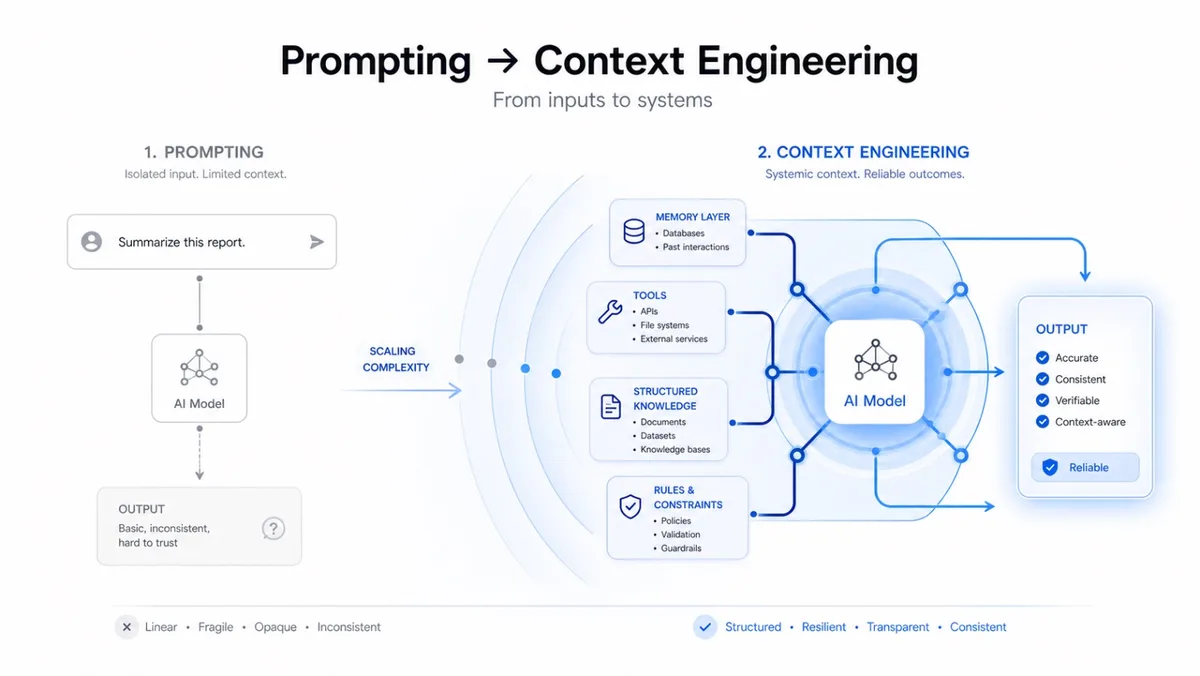
Prompting Đã Cũ - Context Engineering Mới Là Game
Prompting là cuộc chơi cũ. Cuộc chơi thật là quyết định thứ gì bước vào model window ở mỗi bước.
Trong mỗi lượt chạy của agent, context window chứa đồng thời: system rules, tool schemas, retrieved docs, prior tool output, scratchpad state, compressed history.
Tất cả thứ đó cộng lại trở thành agent.
Context xấu làm model tốt trông như model tồi.
Anthropic gọi hiện tượng này là context rot - khi token count tăng, độ chính xác giảm do transformer phải xử lý n² mối quan hệ pairwise.
Agent dài hơi bị "quên" context cũ không phải vì model dở mà vì harness thiết kế sai.
Ba kỹ thuật giải quyết: compaction (tóm tắt history trước khi đầy window), structured note-taking (agent ghi chú ra file ngoài, load lại khi cần), subagent isolation (mỗi subagent trả về 1.000-2.000 token tóm tắt thay vì dump toàn bộ exploration).
Tool Design: Tên Hàm Là UX, Error Message Là Bước Retry
Tên tool là một phần của interface. Error message là một phần của retry loop.
getUserData- mơ hồ, agent không biết dùng lúc nàofetch_customer_invoice_by_email- rõ ràng, tự documentError 400- agent bí, dừngmax tokens exceeded, summarize first- agent có hướng dẫn sửa, tự retry
5 tool thiết kế tốt đánh bại 25 tool thông minh.
Thiết kế tốt nghĩa là: self-contained, không overlap, nếu bạn không xác định được tool nào fit situation thì agent cũng không xác định được.
Toàn bộ một API phức tạp có thể expose qua 2 tool dưới 1.000 token nếu agent tự write code thay vì navigate từng tool riêng lẻ.
Evals: Ranh Giới Giữa Agent Và Demo
Nếu bạn không đo được agent, bạn đang ship demo, không phải sản phẩm.
Quy trình tối thiểu:
Lấy 20-50 real traces từ production hoặc testing
Label failures - cái gì sai, sai ở đâu
Biến failures thành regression set
Từ đó, mỗi thay đổi prompt, mỗi lần swap model, mỗi lần edit tool phải earn its way in bằng cách cải thiện regression set. Anthropic phân biệt 3 loại grader: code-based (nhanh, rẻ, objective nhưng brittle), model-based (linh hoạt, đắt hơn), human (gold standard, chậm nhất).
Metric thực tế: pass@1 = 50% nghĩa là agent thành công ở một nửa task trong lần thử đầu tiên. Khi score đạt 100%, eval bão hòa - đã đến lúc viết test khó hơn.
Cảnh báo quan trọng: grader bug nguy hiểm hơn model bug.
Một case trên CORE-Bench, grader cứng nhắc & spec mơ hồ báo Opus 4.5 đạt 42% - sau khi fix grader, con số thực là 95%.
Bạn có thể đang đánh giá sai agent của mình mà không biết.

Architecture Sống Sót: Boring Nhưng Đúng
Multi-agent trông đẹp trong demo. Multi-agent vỡ trong production.
Lý do: shared state biến thành conflicting decisions.
Khi orchestrator tích lũy context từ 4+ subagent, context window overflow.
Khi orchestrator misclassify task, worker sai nhận việc - lỗi nhân lên theo chiều sâu.
Số liệu: single agent match hoặc vượt multi-agent trong 64% benchmark task khi dùng cùng tool và context.
Multi-agent chỉ cộng thêm 2,1 percentage point accuracy nhưng tốn gấp đôi compute.
Pattern sống sót:
Một orchestrator sở hữu toàn bộ write operations
Subagent chỉ làm research read-only hẹp
Orchestrator synthesize kết quả cuối cùng
Default là một agent cho đến khi context pressure buộc bạn phải tách.
Harness Là Sản Phẩm - Model Chỉ Là Engine
Model stateless. Harness là sản phẩm.
Agent tốt nhất không thông minh hơn nhờ một magic prompt.
Chúng thông minh hơn vì harness nhớ những gì model không thể: log mọi action, checkpoint công việc ở mỗi bước, mỗi step replayable, quyết định lưu ngoài chat window.
File system là state management đủ tốt cho nhiều agent - không cần database phức tạp, mỗi file là một checkpoint, mỗi thư mục là một workflow.
MCP (Model Context Protocol) là chuẩn kết nối giữa agent và hệ thống bên ngoài. Học protocol shape: tools, resources, auth, transport.
Khi bạn hiểu shape đó, phần lớn agent tooling market trông như custom plumbing với logo riêng.
MCP registries đang nổi lên để catalog capabilities ở scale - ngành đang coalescing quanh chuẩn này từ Q1/Q2 2026.
Sandboxing Không Optional - Stack 2026 Và Bước Tiếp
Agent có thể chạy code, browse web, hoặc touch files cần boundaries ngay từ đầu:
Network egress restriction
Secret scoping
Process isolation
Permission checks trên MCP config - agent không được tự edit harness của mình
Bolt sandboxing on later và enterprise buyer sẽ bắt bạn rebuild từ đầu.
Dữ liệu từ adversarial testbed: restrictive policy đạt 0% attack success rate so với 74,6% dưới policy permissive.
Agent tự edit được MCP config của mình có thể leo thang permission tự động - block từ ngày đầu.
Stack 2026 để ship một narrow agent thực sự:
Orchestration: LangGraph hoặc Pydantic AI
Tools: MCP
Observability: Langfuse (open source, self-hostable) hoặc LangSmith
Sandboxes: E2B hoặc Browserbase
State: Postgres hoặc files
Model: Claude hoặc GPT - dựa trên evals của bạn, không dựa trên hype
Bỏ qua weekly launch panic.
Học primitives.
Build một agent hẹp di chuyển một business metric.
Trace mọi thứ, ship cho user, để real failures chỉ bạn học gì tiếp theo.
Via: Anthropic - Context Engineering, Anthropic - Evals, @alphabatcher.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ