
- Jim Fan (NVIDIA) công bố 3 đột phá: WAM (World Action Models), EgoScale với 21.000 giờ video egocentric, và DreamDojo - engine physics thần kinh trained trên 44.711 giờ dữ liệu người.
- Robots học đi trong 2 giờ tương đương 10 năm kinh nghiệm.
- Physical Turing Test dự kiến đạt được năm 2028-2029; Physical Auto-Research vào 2040 với độ tin cậy 95%.
TL;DR
Jim Fan, NVIDIA Director of AI và Co-Lead Project GR00T, vừa trình bày "Robotics: Endgame" tại Sequoia AI Ascent 2026 - phần tiếp theo của talk "Physical Turing Test" năm ngoái. Luận điểm cốt lõi: robotics đang đi theo đúng con đường của LLM - pre-train trên dữ liệu khổng lồ, fine-tune với hành động, scale với RL. NVIDIA giới thiệu 3 đột phá lớn: WAM (World Action Models), EgoScale, và DreamDojo. Physical Turing Test dự kiến đạt được trong 2-3 năm tới.
The Great Parallel - Copy homework từ LLM
Fan gọi lộ trình của robotics là "The Great Parallel" - một bản sao có chủ đích từ thành công của LLM:
- Pre-training trên video = pre-training LLM trên text
- Action fine-tuning = instruction tuning
- Physical RL = RLHF
- WAM (World Action Model) = Large Language Model của thế giới vật lý
Tại sao lại copy? Fan lập luận: "Be a good scientist, copy homework." AlexNet ra đời năm 2012, đến 2026 chúng ta đang bàn về agentic AI - 14 năm. Thêm 14 năm nữa ta đến 2040. Đó là endgame.
Tại sao VLA không đủ - WAM ra đời
Vision-Language-Action (VLA) models - hướng tiếp cận phổ biến hiện tại - có điểm yếu cơ bản: chúng xử lý việc tạo hành động giống như tạo ngôn ngữ. Nhưng thế giới vật lý không phải token văn bản.
World Action Model (WAM) giải quyết điều này bằng cách giải mã đồng thời hai thứ:
- Trạng thái thế giới tiếp theo (video prediction)
- Hành động tiếp theo (motor signals)
"Dream Zero" là WAM đầu tiên được triển khai. Fan dự báo 2026 sẽ đi vào lịch sử là năm đầu tiên Large World Models đặt nền tảng thực sự cho robotics - tương tự vai trò của GPT-3 đối với LLM.
EgoScale và định luật scaling cho sự khéo léo
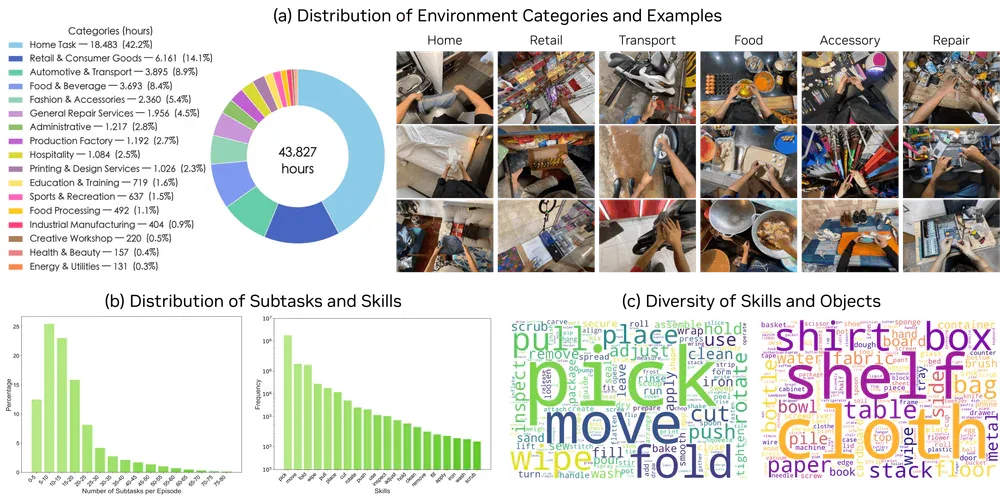
Một trong những phát hiện quan trọng nhất là EgoScale - bộ dữ liệu 21.000 giờ video egocentric (góc nhìn thứ nhất) thu thập từ người trong đời thực. Điểm độc đáo: không dùng một giờ dữ liệu robot nào cho pre-training.
Thay vào đó, model học dự đoán khớp ngón tay và tư thế cổ tay từ video người. Kết quả fine-tuning chỉ cần:
- 50 giờ motion capture độ chính xác cao
- 4 giờ teleoperation
- Tổng cộng <0,1% tổng lượng training data
Team NVIDIA phát hiện một neural scaling law cho dexterity - càng nhiều dữ liệu egocentric, robot càng khéo léo theo quy luật nhất định. Đây là bằng chứng rằng dữ liệu người (không phải dữ liệu robot) là nhiên liệu thực sự của Physical AGI.
DreamDojo - Engine physics thần kinh
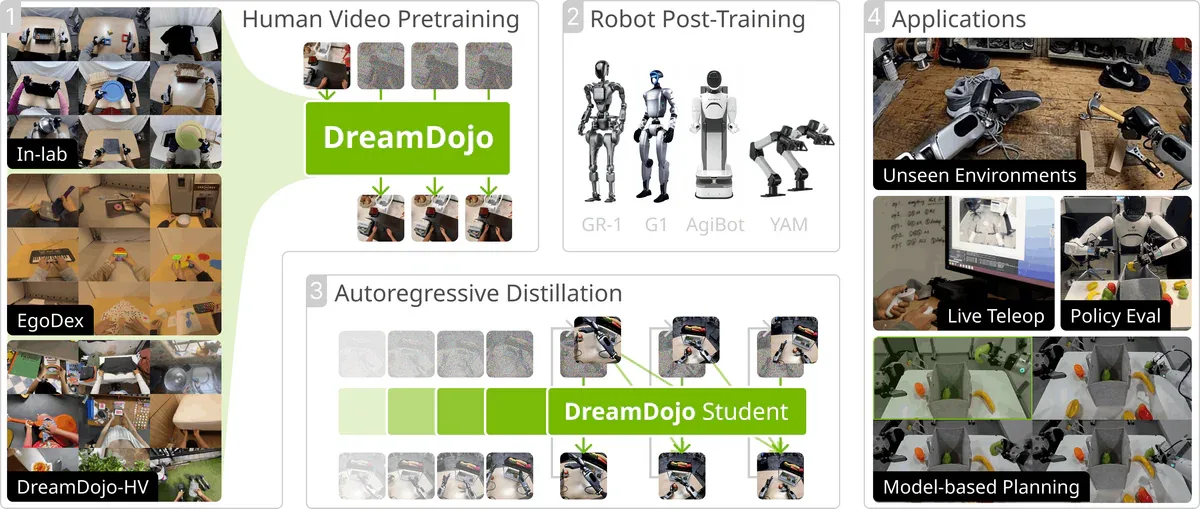
NVIDIA phát hành DreamDojo tháng 2/2026 - một neural physics engine hoàn toàn open-source. Thay vì dùng physics engine truyền thống (cần mesh, dynamics, hand-authored rules), DreamDojo học physics trực tiếp từ pixel. Fan gọi đây là "Simulation 2.0".
Quy mô training:
- 44.711 giờ video egocentric của người
- 6.015 task độc lập trên 1.135.000 trajectory
- 15× thời lượng, 96× số skill, 2.000× số scene so với dataset lớn nhất trước đó
- Pretrained trên 256 H100 GPU (100.000 GPU-hours)
Kiến trúc gồm 700M-parameter spatiotemporal Transformer VAE trích xuất "latent actions" 32 chiều từ video - hardware-agnostic, có thể transfer sang các loại robot khác nhau. Model có 2 variant: 2B và 14B parameters. Distillation version chạy real-time ở 10,81 FPS (giảm từ 35 xuống 4 denoising steps).
Con số đáng chú ý
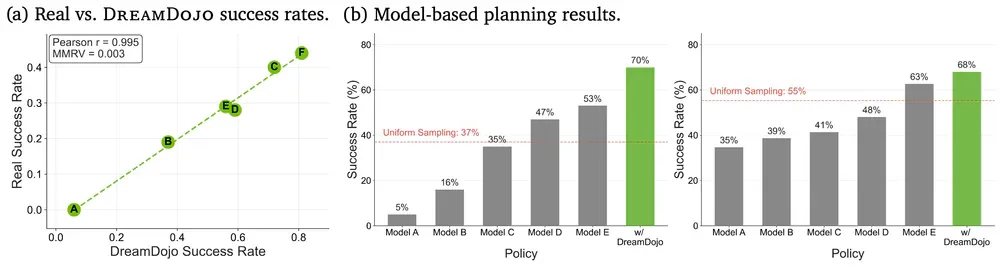
- Tương quan simulation vs thực tế: Pearson r=0,995
- Model-based planning (fruit-packing): 70% vs 37% baseline - tăng gần gấp đôi
- Physics Correctness: 62,5% (2B), 73,5% (14B)
- Humanoid học đi trong 2 giờ simulation = 10 năm kinh nghiệm thực
- Robot control chỉ cần 1,5 triệu parameters
- Real-time speed: 10,81 FPS, ổn định 60 giây liên tục (600 frames)
Lộ trình và dự đoán
Fan đặt ra 3 mốc cho Physical AGI:
- Physical Turing Test (2028-2029): Robot không thể phân biệt với người trong các task có giá trị kinh tế. Ví dụ: về nhà thấy phòng sạch, bữa tối chuẩn bị sẵn - không biết người hay máy làm.
- Physical API (đầu thập niên 2030): Lights-out factories, wet labs tự động hoàn toàn - robot thực thi task theo lệnh API như phần mềm thực thi function call.
- Physical Auto-Research (2040): Robots tự nghiên cứu, tự cải tiến. Fan đặt 95% xác suất điều này xảy ra.
Một chi tiết ít người biết trong talk: Fan là người chứng kiến trực tiếp buổi ký kết DGX-1 tại OpenAI năm 2016 với Jensen Huang và Elon Musk - điểm khởi đầu của "kỷ nguyên GPU cho AI" mà ông nói sẽ sớm được trưng bày tại Computer History Museum.
Kết
Bài talk của Jim Fan không chỉ là roadmap - đây là bản tuyên ngôn rằng Physical AGI không còn là khoa học viễn tưởng. Với 3 công cụ cốt lõi (WAM, EgoScale, DreamDojo) đã có mặt và open-source, cộng đồng nghiên cứu giờ có đủ nền tảng để tham gia vào cuộc đua.
DreamDojo hiện có thể download và post-train trên dữ liệu robot riêng. Xem talk đầy đủ tại Sequoia AI Ascent 2026 - YouTube. Paper & demo: dreamdojo-world.github.io. Code: github.com/NVIDIA/DreamDojo.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ