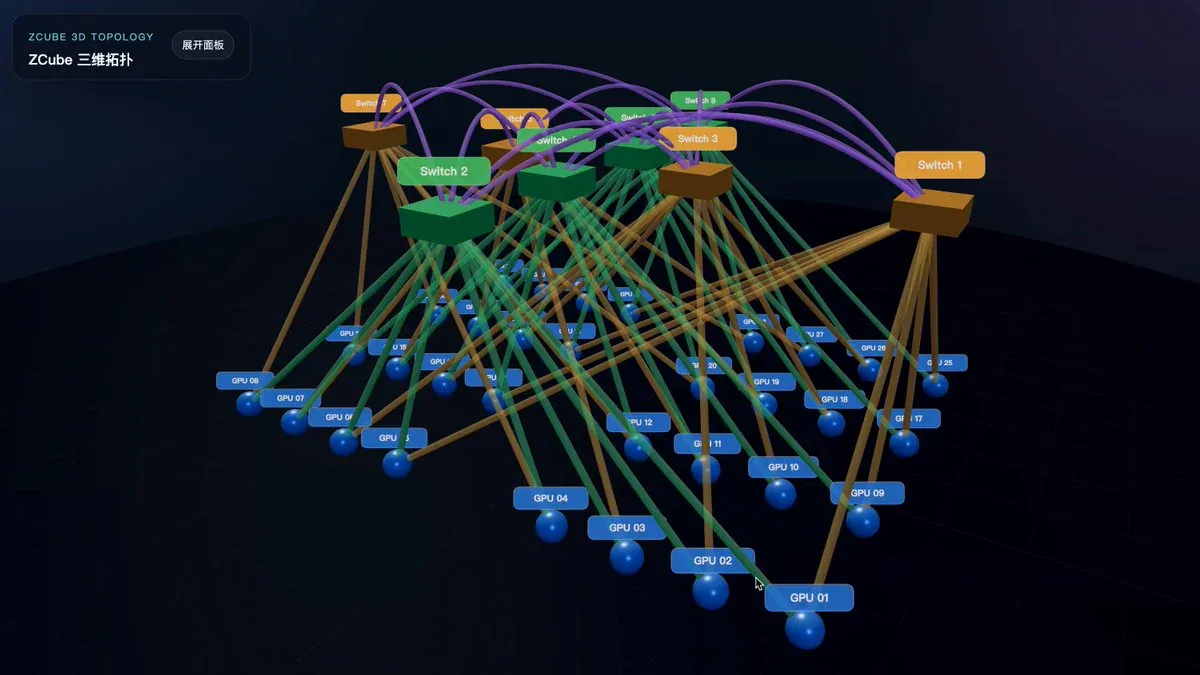
- ZCube là kiến trúc mạng flattened topology do Z.ai, Harnets.AI và Đại học Tsinghua phát triển, được công bố tại ACM SIGCOMM 2025.
- Triển khai thực tế trên cluster ngàn GPU chạy GLM-5.1, ZCube giảm 33% CapEx switch và optical module mà không thay đổi GPU hay phần mềm.
- Throughput inference tăng 15%, TTFT P99 giảm 40.6% - chỉ bằng cách nâng cấp kiến trúc mạng.
- Với cluster 10,000 GPU, ZCube tiết kiệm khoảng 210-640 triệu RMB chi phí phần cứng mạng.
TL;DR
Mạng từng là thành phần ít quan trọng nhất trong một cụm inference. Điều đó không còn đúng nữa. Z.ai, Harnets.AI và Đại học Tsinghua vừa triển khai ZCube lên môi trường sản xuất thực tế - kiến trúc mạng flattened topology được phát hiện qua pipeline tối ưu hóa tự động ATOP, trình bày tại ACM SIGCOMM 2025.
Kết quả trên cluster ngàn GPU chạy GLM-5.1 coding inference:
- -33% CapEx switch và optical module (GPU, phần mềm, ứng dụng không thay đổi)
- +15% average GPU inference throughput
- -40.6% TTFT P99 tail latency
Khi mạng trở thành nút thắt cổ chai
Với long-context inference và Prefill-Decode (PD) disaggregation ngày càng phổ biến, mạng nội cụm đã leo lên vị trí quan trọng bậc nhất trong chuỗi serving: mỗi token sinh ra đều phải đi qua ít nhất một lần chuyển giao KV Cache giữa các node Prefill và Decode.
Để định lượng tác động, nhóm nghiên cứu thực hiện ablation study trên cluster 512 GPU - giữ nguyên mọi thứ, chỉ thay đổi băng thông NIC:
- Tăng băng thông 100Gbps lên 200Gbps → throughput tổng tăng ~19%, TTFT giảm ~22%
Số liệu này xác nhận một điều: băng thông mạng đã trở thành một trong những yếu tố then chốt giới hạn hiệu năng LLM serving.
Vấn đề cốt lõi: traffic bất đối xứng
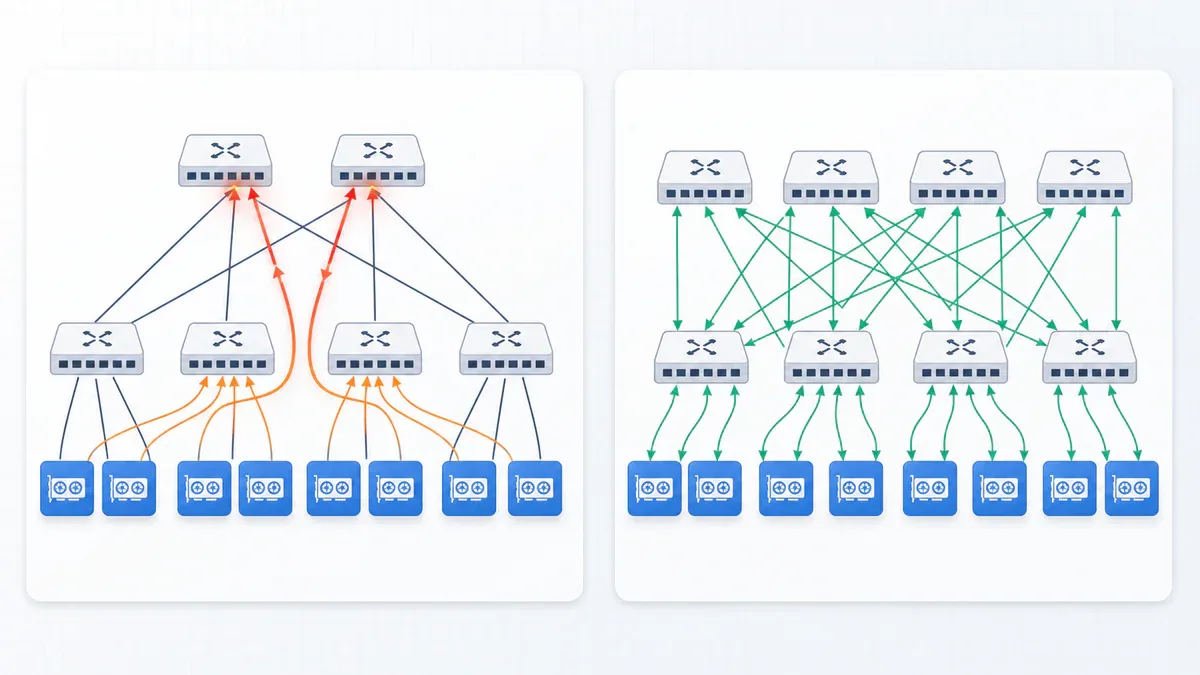
Kiến trúc mạng ROFT (Rail-Optimized Fat-Tree) - chuẩn công nghiệp hiện tại - được thiết kế cho traffic huấn luyện tương đối đều và có thể dự đoán. Nhưng PD disaggregated inference tạo ra một loại traffic hoàn toàn khác: KV Cache transfer có nguồn-đích thay đổi liên tục, khối lượng không đồng đều, và phân phối tải trên NIC rất lệch nhau.
Trong ROFT, static topology và port mapping cố định dẫn đến traffic tập trung lên một số ít Leaf switch - gây hotspot, queue buildup, và PFC backpressure lan rộng. Kết quả là: tổng băng thông nhìn thì đủ, nhưng tắc nghẽn cục bộ xảy ra liên tục.
Phân biệt hai loại tắc nghẽn quan trọng để hiểu tại sao ZCube hiệu quả:
- Tắc nghẽn không tránh được: nhiều GPU cùng gửi data đến một đích - phải dùng congestion control để giảm nhẹ.
- Tắc nghẽn tránh được: do thiết kế topology, traffic mapping, hoặc multipath không cân bằng - đây là vấn đề kiến trúc, cần giải quyết từ gốc.
ZCube tấn công loại thứ hai.
ZCube hoạt động như thế nào
ZCube loại bỏ hoàn toàn lớp Spine switch - điểm khác biệt căn bản so với mọi kiến trúc Clos/Fat-Tree truyền thống. Thay vào đó:
- Chia toàn bộ Leaf switch thành 2 nhóm bằng nhau (lẻ và chẵn)
- Kết nối bipartite đầy đủ giữa 2 nhóm: mỗi switch nhóm lẻ nối với tất cả switch nhóm chẵn
- Mỗi GPU NIC (2 port) kết nối với 1 switch nhóm lẻ và 1 switch nhóm chẵn theo hybrid single-rail / multi-rail
- Đường kính mạng: 2 switch hop cho mọi cặp GPU
Thiết kế này đảm bảo mỗi cặp GPU có một đường đi tối ưu duy nhất, loại bỏ xung đột multipath. Quan trọng hơn, tổ hợp single-rail/multi-rail kép tạo ra load balancing tự nhiên với cả training traffic (AllReduce, All-to-All) lẫn inference traffic bất đối xứng của PD disaggregation.
Kết quả: traffic vốn sẽ va chạm trong ROFT có thể đi trên các đường riêng biệt trong ZCube, tránh tắc nghẽn ngay từ nguồn.
Con số từ triển khai thực tế
Nhóm đã nâng cấp một cluster ngàn GPU đang chạy GLM-5.1 coding inference service từ ROFT sang ZCube. Đây là lần đầu tiên kiến trúc này được triển khai ở quy mô sản xuất thực sự. Kết quả đo sau migration:
| Chỉ số | Thay đổi |
|---|---|
| Switch + optical module CapEx | -33% |
| Average GPU inference throughput | +15% |
| TTFT P99 tail latency | -40.6% |
Điểm đáng chú ý: toàn bộ cải thiện đến từ việc thay đổi duy nhất kiến trúc mạng - GPU, model weight, software stack, và ứng dụng đều giữ nguyên. ZCube cluster này đã chạy ổn định hơn 2 tuần phục vụ GLM-5.1 tính đến thời điểm công bố.
Ở quy mô lớn hơn, sử dụng 1 lớp switch 51.2T (128 x 400Gbps port), ZCube kết nối được 16,384 NIC 400Gbps. Với cluster 10,000 GPU, tiết kiệm ước tính 210-640 triệu RMB chi phí phần cứng mạng so với ROFT.
Ai nên quan tâm
Đội ngũ vận hành AI infrastructure quy mô lớn là đối tượng hưởng lợi trực tiếp nhất. Nếu bạn đang vận hành cluster hàng trăm GPU trở lên với PD disaggregation, ZCube mở ra cơ hội cải thiện throughput và latency đáng kể mà không cần mua thêm GPU hay thay đổi phần mềm.
Nhà thiết kế data center có thể tính toán lại bài toán chi phí: ZCube cho phép dùng ít switch và optical module hơn trong khi duy trì - thậm chí cải thiện - hiệu năng mạng.
Researcher và kỹ sư systems quan tâm đến hướng co-design network với inference workload có thể xem ATOP (pipeline tối ưu hóa topology tự động) là một hướng nghiên cứu có triển vọng - ZCube chỉ là một trong những topology được ATOP khám phá.
Lưu ý thực tế: migration từ ROFT sang ZCube không phải drop-in upgrade. Cabling, IP addressing, routing policies và switch config cần thiết kế lại hoàn toàn. Harnets.AI đã phát triển bộ automation tools (ZCube Controller, layout design tool, cabling verification) để giải quyết vấn đề này trong production deployment đầu tiên.
Kết: mạng là core của inference
ZCube là ví dụ điển hình cho một xu hướng lớn hơn: LLM inference đang chuyển từ tối ưu hóa từng điểm sang co-design toàn hệ thống. Coupling giữa network và inference engine ngày càng chặt chẽ - KV Cache transfer, PD disaggregation, và sắp tới là Attention-FFN disaggregation đều đặt ra yêu cầu mới cho lớp mạng.
Hướng tiếp theo mà nhóm ZCube hướng tới: thiết kế mạng không còn dừng lại ở lớp kết nối GPU chung chung, mà tiến đến model-traffic-driven system co-design - nơi network topology, communication library và scheduling policy được tối ưu cùng nhau quanh traffic thực của model. Đó là bài toán mở và là frontier tiếp theo của AI infrastructure.
Paper gốc: From ATOP to ZCube - ACM SIGCOMM 2025 | via Z.ai