
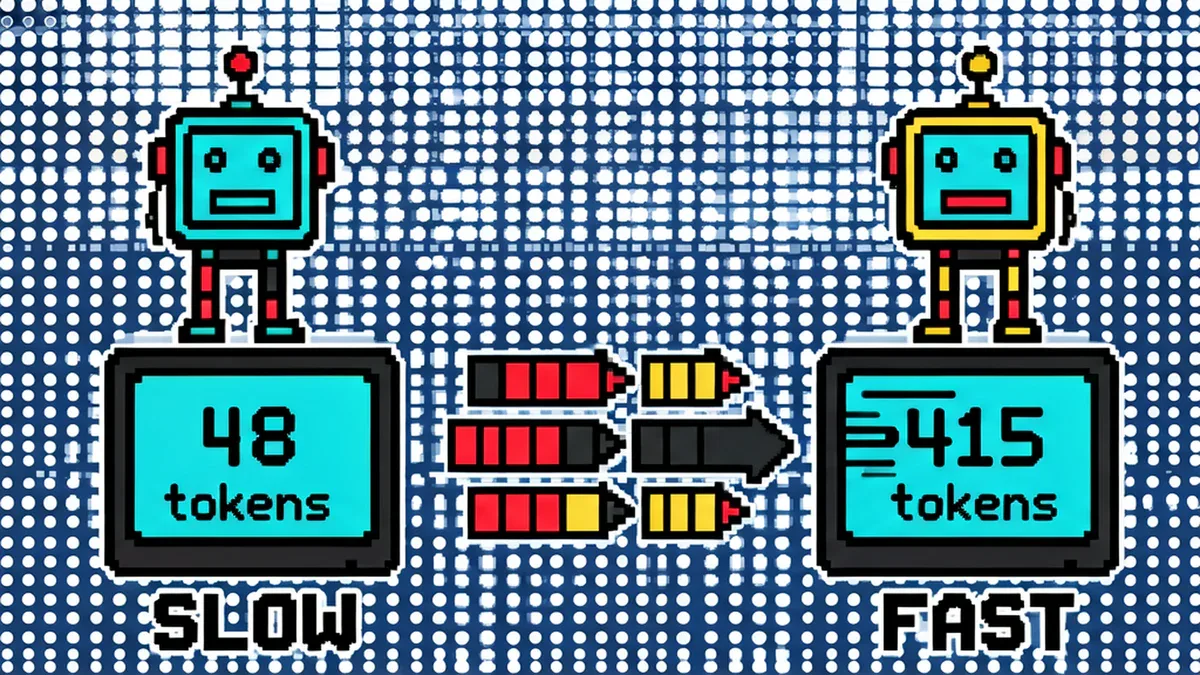
- DFlash đạt 415.7 tokens/sec trên Qwen3-8B, nhanh hơn 8.5x so với baseline 48.5 tokens/sec mà hoàn toàn lossless.
- Block diffusion model sinh toàn bộ token block trong 1 forward pass duy nhất - chi phí draft không đổi dù suy đoán bao nhiêu token.
- Nhanh hơn 2.5x so với EAGLE-3, SOTA trước đó.
- MIT license, đã hỗ trợ vLLM v0.20.1+, SGLang, Transformers với 18 model phổ biến.
TL;DR
DFlash là kỹ thuật mới từ Z Lab (tháng 2/2026) thay thế autoregressive drafter trong speculative decoding bằng một block diffusion model nhỏ gọn. Thay vì tạo token tuần tự, DFlash sinh cả một block token trong 1 forward pass duy nhất - đồng thời conditioning trên hidden features từ nhiều layer của target model. Kết quả thực đo: 415.7 tokens/sec trên Qwen3-8B so với 48.5 tokens/sec của autoregressive baseline, nhanh hơn 8.5x lossless.
Vấn đề mà speculative decoding truyền thống chưa giải quyết được
Speculative decoding là kỹ thuật tăng tốc LLM bằng cách dùng một model nhỏ (drafter) đoán trước nhiều token, sau đó target model lớn xác nhận toàn bộ trong 1 forward pass song song. Nếu token nào sai, giữ lại phần đúng và bắt đầu lại từ đó. Điểm mạnh: kỹ thuật này không bao giờ làm kết quả tệ hơn decoding thông thường - rejection sampling đảm bảo phân phối giống hệt target model.
Vấn đề nằm ở drafter: dù target model đã chạy song song, drafter vẫn sinh token tuần tự theo kiểu autoregressive. Mỗi token phải đợi token trước hoàn thành. Nghĩa là bottleneck không bị xóa - chỉ dịch chuyển từ target sang drafter, giới hạn tốc độ tăng thực tế ở 2-3x ngay cả với EAGLE-3, phương pháp SOTA trước DFlash.
DFlash: cơ chế hoạt động
DFlash phá vỡ giới hạn này bằng 2 đổi mới kết hợp:
- Block diffusion parallel drafting: Thay drafter autoregressive bằng một block diffusion model nhỏ gọn, sinh toàn bộ block k token trong 1 forward pass duy nhất bằng cách denoising một masked sequence. Chi phí drafting hoàn toàn flat - không đổi dù suy đoán 4 hay 16 token. Đây là điểm khác biệt cốt lõi so với mọi speculative decoding trước đó.
- Target-conditioned context features: Hidden features từ nhiều layer của target LLM được extract và inject vào mọi layer của draft model qua KV projection. Draft model nhận được ngữ cảnh sâu từ chính target model mà nó đang hỗ trợ, cho ra draft quality cao hơn nhiều so với drafter hoạt động độc lập từ đầu.
Hai yếu tố này cộng hưởng: parallel generation giải phóng bottleneck, còn target conditioning đảm bảo acceptance rate cao - ít phải rollback, nhiều token được giữ lại hơn mỗi vòng.
Những con số đáng chú ý
Benchmark thực đo trên cùng Qwen3-8B, cùng hardware:
- Vanilla autoregressive: 48.5 tokens/sec (baseline)
- SDAR-8B (block diffusion, lossy): 97.5 tokens/sec - nhanh nhưng mất chất lượng
- EAGLE-3 (SOTA lossless trước DFlash): 114.2 tokens/sec
- DFlash: 415.7 tokens/sec - lossless, nhanh hơn 8.5x baseline, 3.6x EAGLE-3
Trên range rộng model và task (GSM8K, MATH-500, HumanEval, MBPP, MT-Bench):
- 6x+ lossless acceleration nhất quán
- 2.5x cao hơn EAGLE-3 trên hầu hết task
- Acceptance length: duy trì 3-4+ tokens
- Qwen3-Coder-30B kết hợp DDTree: lên tới 8.22x speedup
- Reasoning models với thinking mode: xấp xỉ 4.5x
Speedup đạt tốt nhất ở low-to-medium QPS (memory-bound) - đây cũng là điều kiện phổ biến nhất khi serving thực tế cho end-user.
Ai nên dùng ngay
DFlash là MIT license, open-source hoàn toàn, code và models public. Draft models có sẵn trên HuggingFace cho 18 model:
- Qwen series: Qwen3-4B, Qwen3-8B, Qwen3.5-4B đến 122B, Qwen3.6, Qwen3-Coder
- Frontier models: Kimi-K2.5, MiniMax-M2.5 (Preview), gpt-oss-20b, gpt-oss-120b
- Classic: LLaMA-3.1-8B-Instruct, Gemma-4-26B-A4B-it, Gemma-4-31B-it
- Coming soon: DeepSeek-V4 variants, MiniMax-M2.7, GLM-5.1
Backend hỗ trợ:
- vLLM v0.20.1+: Production serving (Gemma4 cần Docker image riêng)
- SGLang: Production serving song song
- Transformers: Prototyping nhanh
- MLX: Apple Silicon
Nếu bạn đang chạy LLM serving với bất kỳ model nào trong danh sách trên ở medium-to-low QPS và muốn giảm latency đáng kể mà không cần thêm GPU - DFlash là upgrade rõ ràng và dễ tích hợp nhất hiện tại.
Kết
DFlash giải quyết đúng vấn đề cốt lõi mà speculative decoding chưa hoàn thiện: bottleneck dịch chuyển sang drafter vì drafter vẫn autoregressive. Bằng cách dùng block diffusion parallel + target-conditioned features, kỹ thuật này đẩy tốc độ lên 8.5x trong điều kiện lossless - điều mà EAGLE-3 hay các phương pháp trước không đạt được.
Roadmap tiếp tục: thêm model (DeepSeek-V4, GLM-5.1) và DDTree - kết hợp DFlash với draft tree structure - đã demo 8.22x trên Qwen3-Coder-30B. Hướng này hứa hẹn còn đẩy được cao hơn nữa.
Paper, code, models: ArXiv 2602.06036 · GitHub z-lab/dflash · HuggingFace Models · via @_avichawla


