
- Mỗi setup hardware có recipe engine tối ưu riêng - từ CPU-only server đến cụm 8×H100.
- Benchmark tốt đo TTFT, TPOT, p95 và KV cache hit rate - không phải tok/s single-user.
- Và 10 sai lầm phổ biến nhất mà hầu hết team đều mắc ít nhất một lần.
- Phần cuối trong series 4 bài.
TL;DR
Phần cuối của series tổng hợp ba thứ thực chiến nhất: hardware recipes theo setup, cách benchmark không lãng phí thời gian, và 10 sai lầm phổ biến để tránh ngay từ đầu.
Hardware strategy recipes
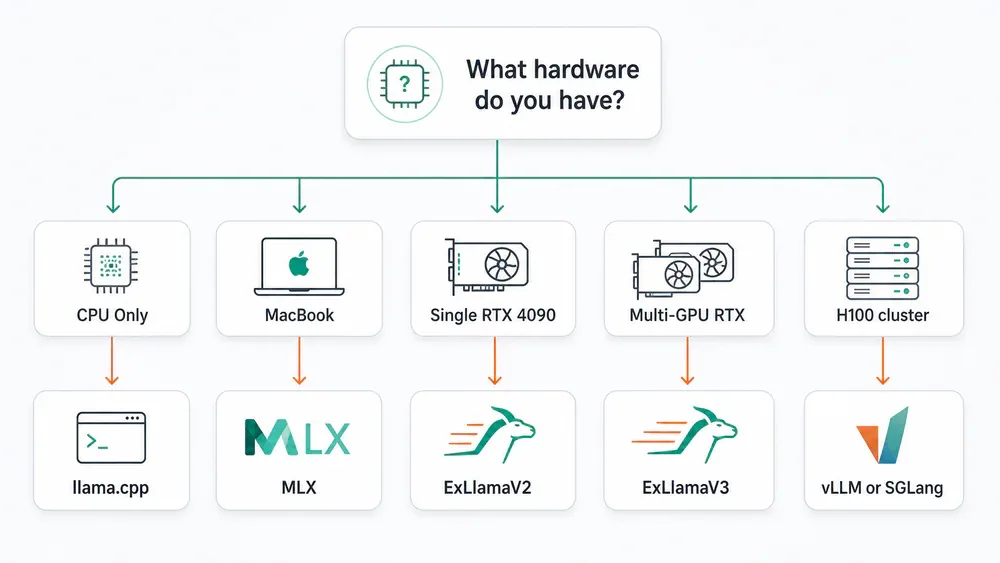
CPU-only server: llama.cpp là lựa chọn đầu tiên. OpenVINO GenAI cho Intel Xeon. ONNX Runtime GenAI nếu deployment vào app hay ONNX workflows.
MacBook / Mac Studio: MLX / MLX-LM cho Mac-native workflows (research, fine-tuning, private AI). llama.cpp cho GGUF portability. Unified memory là lợi thế capacity, không phải bandwidth.
Single RTX 3090 / 4090 / 5090: ExLlamaV2 cho EXL2 local inference tốc độ tối đa. llama.cpp nếu cần GGUF hoặc portability. vLLM nếu serve nhiều user.
Dual hoặc quad consumer RTX: ExLlamaV3 cho multi-GPU quantized inference hoặc MoE local. vLLM/SGLang nếu serving behavior quan trọng hơn.
8×H100 / H200 node: Bắt đầu với vLLM hoặc SGLang. Benchmark TensorRT-LLM nếu NVIDIA-only và performance đủ lý do để invest. Dùng Dynamo khi multi-node orchestration trở thành cần thiết.
B200 / GB200 / GB300-class: Benchmark TensorRT-LLM, SGLang và vLLM. Thêm Dynamo cho fleet-level orchestration, KV-aware routing và autoscaling.
AMD MI300 / MI325 / MI350 / MI355: Bắt đầu với vLLM hoặc SGLang trên ROCm. Đừng assume benchmark NVIDIA transfer sang AMD sạch sẽ.
Intel Xeon / Core Ultra / Arc: OpenVINO GenAI hoặc OpenVINO Model Server. ONNX Runtime GenAI nếu cần app embedding.
Browser, mobile, app-native: MLC LLM / WebLLM hoặc ONNX Runtime GenAI.
Benchmark đúng cách
Benchmark tệ: "Tôi đạt 180 tok/s."
Benchmark tốt bao gồm đầy đủ context:
Model: tên model chính xác, kiến trúc, số parameter, active MoE params
Weights: dtype, quant format, group size, calibration
Engine: version, commit, backend, flags
Hardware: GPU SKU, memory capacity, bandwidth, interconnect, CPU, RAM
Workload: input/output length distributions, concurrency, streaming, shared prefixes, structured output
Metrics: TTFT, TPOT, end-to-end latency, p50/p95/p99, tokens per second, requests per second, GPU memory usage, KV cache hit rate, prefill throughput, decode throughput, cost per 1M tokens
Các quy tắc benchmarking:
Không so sánh engines dựa chỉ trên single-user tokens per second
Test với actual prompt và output distribution của bạn
Test với concurrency thực tế
Tách prefill và decode
Track p95 và p99, không chỉ averages
Đo memory headroom tại target context length
Test cache reuse nếu app có repeated prefixes
Benchmark structured output riêng - grammar thêm overhead đáng kể
Benchmark LoRA và multi-LoRA riêng
Re-test sau khi upgrade driver, CUDA, ROCm, model hoặc engine
10 sai lầm phổ biến
1. Chọn dựa thuần vào VRAM size. VRAM xác định model có fit không. Bandwidth và scheduler xác định tốc độ. Máy unified memory lớn có thể fit model khổng lồ, nhưng H100 decode nhanh hơn nhiều khi model fit - nhờ HBM bandwidth cao hơn.
2. Dùng tensor parallelism trên interconnect yếu. Không có NVLink hay NVSwitch, test pipeline parallelism. vLLM docs ghi rõ điều này cho L40S-like setups. Tensor parallelism cần all-reduce collectives thường xuyên - latency của interconnect nhân lên theo số operation.
3. Bỏ qua KV cache. Long context và concurrency cao có thể khiến KV cache trở thành limiting factor. PagedAttention, prefix caching, KV quantization và disaggregation không phải optional ở scale. Với model 70B và context 200.000 token, KV cache một mình có thể chiếm 40-80 GB VRAM.
4. Treat local engines như production server. llama.cpp server capable. MLX-LM server tiện. Nhưng production nghĩa là security, observability, backpressure, routing, autoscaling và SLA behavior. MLX-LM server tự cảnh báo không khuyến khích cho production. Đừng nhầm lẫn giữa "chạy được" và "sẵn sàng production".
5. Assume mọi quantization format đều portable. GGUF, EXL2, EXL3, AWQ, GPTQ, FP8, FP4, MLX formats và ONNX không hoán đổi cho nhau. Format đúng là format mà engine của bạn có optimized kernels. AWQ không có Marlin kernel: 68 tok/s. AWQ với Marlin kernel: 741 tok/s - cùng weights, gấp 10,9 lần.
6. Bỏ qua kiến trúc model. Dense models, MoE, hybrid attention, multimodal models và long-context variants gây stress các phần khác nhau của engine. Support rộng không có nghĩa mọi optimization đều hoạt động như nhau.
7. Tin benchmark chart mà không xét workload shape. Chart cho Llama 3.1 8B ở 1K input / 128 output nói rất ít về coding agent với 80K context chạy trên Qwen3 27B, hay RAG service với 500 concurrent users.
8. Dùng Ollama cho production. Ollama không có continuous batching thực sự, không tensor-parallel batched serving. Multi-GPU chỉ là model split. Phù hợp laptop và workstation yên tĩnh, không phải concurrent serving quá 1-2 requests cùng lúc.
9. Dùng TGI cho project mới. HuggingFace archived TGI tháng 3/2026 và recommend vLLM, SGLang, llama.cpp hoặc MLX. Existing TGI deployments vẫn chạy được, nhưng không bắt đầu project mới trên TGI.
10. Không re-test sau upgrade. Engine version, driver, CUDA/ROCm, model update đều có thể thay đổi performance profile đáng kể. Số benchmark bạn có từ 6 tháng trước có thể không còn chính xác.
Bản đồ quyết định cuối
Tổng hợp ngắn gọn nhất có thể:
Local AI user: LM Studio / Harbor cho convenience. llama.cpp cho control. MLX trên Mac. ExLlamaV2/V3 cho CUDA local performance
Build local agent: llama.cpp cho portability. MLX nếu user dùng Apple Silicon. vLLM nếu simulate production serving local
Serve internal team: Bắt đầu vLLM. Dùng SGLang nếu structured outputs, long context, multi-LoRA, MoE hoặc routing là vấn đề
Serve customer ở scale: Benchmark vLLM, SGLang và TensorRT-LLM. Nếu routing và disaggregation quan trọng, SGLang và Dynamo cần vào bake-off
NVIDIA datacenter: TensorRT-LLM cho max performance. vLLM cho flexibility. SGLang cho complex serving. Dynamo cho fleet orchestration
Apple Silicon: MLX cho native development. llama.cpp cho GGUF. Unified memory là capacity superpower với bandwidth tradeoffs
Edge, app, browser, Windows-native: llama.cpp, MLC LLM, ONNX Runtime GenAI hoặc OpenVINO tùy stack
Kết: Engine đi theo câu trả lời
Nguyên tắc cuối cùng của series này: Inference Engines have consequences. Không có engine nào tốt nhất cho mọi tình huống. Engine tốt nhất là engine khớp với hardware bạn có, workload shape của bạn, và mục tiêu vận hành của bạn.
Series 4 phần về Inference Engines 2026 kết thúc ở đây. Nếu bạn cần ôn lại nền tảng lý thuyết (prefill, decode, bottlenecks), xem lại Phần 1.
Nếu bạn đang quyết định giữa local engines, xem Phần 2.
Nếu bạn đang evaluate production stack, xem Phần 3.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ