
- Prefill xử lý toàn bộ prompt song song - bottleneck là compute, metric là TTFT.
- Decode sinh từng token một - bottleneck là memory bandwidth, metric là ITL.
- Llama-2-13B tốn 800KB KV cache mỗi token, 4K context với batch 8 ngốn 25GB VRAM.
- DeepSeek MLA nén cache xuống 93.3% và tăng throughput 5.76x bằng cách redesign attention từ đầu.
TL;DR
LLM inference gồm hai pha với bottleneck ngược chiều nhau. Prefill xử lý toàn bộ prompt trong một forward pass song song, bị giới hạn bởi compute - đây là lý do bạn chờ token đầu tiên xuất hiện. Decode sinh từng token một, chỉ tính Q cho token mới nhưng phải đọc toàn bộ KV cache từ VRAM mỗi bước - bị giới hạn bởi memory bandwidth. Hiểu sự phân tách này giải thích gần như mọi hiện tượng kỳ lạ trong LLM serving.
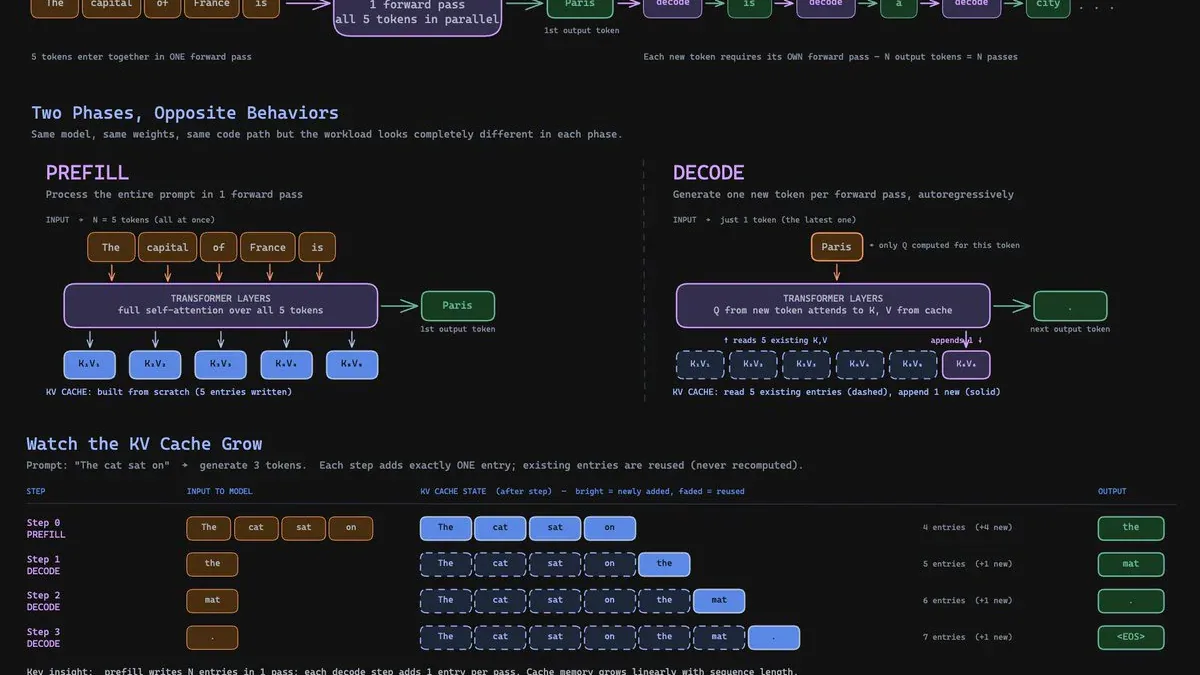
Hai pha, một model, hai bottleneck hoàn toàn khác nhau
Khi bạn gửi một prompt, model không chạy một vòng lặp đơn thuần. Nó đi qua hai giai đoạn hoàn toàn khác nhau về tính chất, dù dùng cùng weights và cùng code path.
Pha prefill xử lý toàn bộ input cùng lúc. Model tính Q, K, V cho mọi token trong prompt song song, chạy full self-attention qua một phép nhân ma trận khổng lồ. GPU làm đúng thứ nó được thiết kế để làm: dense matrix math ở utilization cao. Kết quả: token đầu tiên được sinh ra. Metric đo giai đoạn này là TTFT - Time to First Token.
Pha decode diễn ra sau đó. Để sinh token tiếp theo, model chỉ cần tính Q, K, V cho token mới nhất - vì tất cả token trước đã được cache. Phép tính rất nhỏ: nhân một query vector đơn với toàn bộ key đã cache. Nhưng GPU vẫn phải tải weights và toàn bộ cache từ VRAM để thực hiện phép nhỏ đó. Đây là lý do bottleneck lật ngược - từ compute sang memory bandwidth. Metric là ITL - Inter-Token Latency.
| Pha | Làm gì | Bottleneck | Metric |
|---|---|---|---|
| Prefill | Xử lý toàn bộ prompt song song | Compute-bound | TTFT |
| Decode | Sinh từng token, đọc KV cache | Memory-bandwidth-bound | ITL / TPOT |
GPU utilization cao rồi đột ngột rớt - đây là lý do
Nếu bạn monitor GPU trong khi chạy inference, bạn sẽ thấy utilization spike cao khi prompt vào, rồi rớt xuống thấp khi model bắt đầu stream. Điều này không phải bug - đây là triệu chứng chính xác của sự chuyển pha từ prefill sang decode.
Prefill là compute-bound: GPU bận toán học nặng, utilization cao là bình thường. Decode là memory-bandwidth-bound: compute gần như nhàn rỗi, bottleneck thật sự là tốc độ đọc VRAM. Thêm FLOPs không giúp ích gì ở đây - bạn cần memory nhanh hơn hoặc cache nhỏ hơn. Đây là lý do ném thêm GPU compute vào một model đang stream chậm thường không cải thiện được gì.
Ví dụ với Llama 3.1 70B: ở 32,768 token input, TTFT khoảng 472ms; ở 122,880 token, TTFT leo lên 2.2 giây. Decode thì ITL điển hình trên phần cứng tốt nằm ở 20-100ms mỗi token - tức 10-50 tokens/giây.
KV cache: thứ giúp decode có thể tồn tại
Nếu không có KV cache, mỗi token mới sẽ phải recompute attention trên toàn bộ sequence đang tăng dần - chi phí quadratic theo độ dài, không thể dùng trong production.
KV cache giải quyết bằng cách lưu lại toàn bộ K và V đã tính trong prefill, rồi chỉ append thêm một entry mới sau mỗi decode step. Cache được build một lần duy nhất trong prefill, sau đó grow tuyến tính - một entry mỗi token, existing entries được reuse không recompute.
Đây là optimization cho phép decode viable. Nhưng nó đi kèm chi phí rõ ràng: cache sống trong GPU VRAM và tăng tuyến tính theo context length. Mỗi bước decode phải load toàn bộ cache - đây chính xác là lý do context dài cảm giác chậm không tuyến tính.
800KB mỗi token và bức tường bộ nhớ
Con số cụ thể giúp bức tranh rõ hơn nhiều:
| Model | KV cache per token | GQA reduction | After GQA |
|---|---|---|---|
| Llama-2-7B | 512 KB | - | 512 KB |
| Llama-2-13B | 800 KB | - | 800 KB |
| Llama-2-70B | ~2.5 MB | 8x | 320 KB |
| Mistral-7B | ~512 KB | 4x | 128 KB |
| Gemma-2B | ~144 KB | 8x | 18 KB |
Llama-2-13B với 4096-token context và batch size 8: ~25GB cho cache - gần bằng toàn bộ model weights. Một request Llama 3.1 70B ở 128K context tiêu thụ ~40GB KV cache. Bốn concurrent request như vậy: 160GB chỉ cho cache, nhiều hơn cả model weights.
Context dài cảm giác chậm không phải vì model "hết brainpower" - mà vì mỗi decode step phải đọc một cache ngày càng lớn từ VRAM có bandwidth hữu hạn. Bạn không thể nén thời gian; bạn chỉ có thể nén cache hoặc tăng bandwidth.
Ngành đang phá bức tường đó như thế nào
Constraint này kéo theo cả một chuỗi đổi mới kỹ thuật nhắm thẳng vào KV cache:
- Grouped-Query Attention (GQA) - gom nhóm query heads chia sẻ chung KV thay vì mỗi head có riêng. Llama-2-70B với GQA: cache giảm 8x; Mistral-7B: 4x. Chất lượng tốt hơn MQA (multi-query attention) vốn collapse hết về một KV pair và gây quality drop.
- Sliding Window Attention (SWA) - chỉ giữ W token gần nhất trong cache, evict token cũ. Mistral-7B dùng W=4096, tiết kiệm thêm ~2x so với GQA.
- PagedAttention (vLLM) - phân bổ VRAM cho cache theo block động, không pre-allocate liên tục. Giảm memory waste từ 60-80% xuống còn ~4%, cho phép serving nhiều concurrent request hơn gấp 2-4x trên cùng GPU.
- KV cache quantization - nén từ FP16 xuống INT4: giảm 57% decode latency trên LLaMA3-8B với quality impact tối thiểu.
- DeepSeek MLA (Multi-Head Latent Attention) - thay vì giảm số head, nén K/V thành latent vector 512 chiều (từ ~14.000 values). Kết quả: cache nhỏ hơn 93.3%, throughput tăng 5.76x so với MHA predecessor. Đây là redesign kiến trúc thật sự - không thể retrofit vào model sẵn có.
Khi attention đang được thiết kế lại từ đầu để fit vào cache, bạn biết constraint đó đã shift thành vấn đề cốt lõi của field.
Chẩn đoán khi model chạy chậm
Sự phân tách prefill/decode cho bạn một framework chẩn đoán cụ thể - không phải đoán mò:
- Chậm để bắt đầu (TTFT cao): bottleneck ở prefill, tức compute. Giải pháp nhắm đúng: FlashAttention, chunked prefill (tăng 50% throughput trong thực tế theo benchmark TNG), hoặc scale compute.
- Chậm khi stream (ITL cao): bottleneck ở decode, tức memory bandwidth. Giải pháp: GQA, cache quantization, speculative decoding (3.55x speedup trên Llama 3.3 70B), hoặc chuyển sang kiến trúc cache-efficient hơn.
Throwing thêm FLOPs vào model đang stream chậm là sai chẩn đoán hoàn toàn - giống như tăng tốc CPU khi bottleneck thực sự là disk I/O. Đo TTFT và ITL riêng biệt trước, optimize sau.
Đọc thêm
Bài này tổng hợp từ phân tích của @akshay_pachaar - một first-principles guide đi từ tokenization đến quantization, rất đáng đọc nếu bạn muốn mental model đầy đủ về LLM inference.
Nguồn kỹ thuật tham khảo thêm: Redis: Prefill vs Decode, Vizuara: Decoding MLA, KV Cache Optimization Techniques.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ