
- 4 khái niệm kỹ thuật cốt lõi phân biệt người dùng AI và người xây dựng AI: Tokenization, Embeddings, Attention Mechanism và Fine-tuning.
- Chuyên gia fine-tuning (LoRA, RLHF) đang kiếm $350-$700/giờ freelance 2026.
- Cộng thêm RAG - kỹ năng sinh tiền nhất để build private AI assistants - và cách deploy lên production thực tế.
TL;DR
Sau khi có nền tảng Python và Neural Networks từ Phần 1, đây là những gì thực sự phân biệt người dùng AI và người xây dựng AI: 4 khái niệm kỹ thuật cốt lõi và 2 kỹ năng sinh tiền nhất - RAG và Deployment. Nhóm người nắm được những thứ này đang charge $125-$250/giờ, trong khi nhóm chỉ biết "dùng ChatGPT" không có chỗ trong thị trường này.
Tokenization - AI đọc text như thế nào?
LLM không đọc từ như con người. Chúng tách văn bản thành các "token" - đơn vị nhỏ hơn từ, có thể là chuỗi ký tự, âm tiết hoặc từ nguyên vẹn.
Ví dụ câu "Artificial Intelligence is powerful" có thể thành: ["Artific", "ial", " Intell", "igence", " is", " powerful"].
Ba tokenizer phổ biến nhất:
- BPE (Byte Pair Encoding): dùng trong GPT, chia nhỏ dần từ ký tự đến subword thông dụng
- SentencePiece: dùng trong Llama, hoạt động trực tiếp trên byte - hỗ trợ tốt đa ngôn ngữ kể cả tiếng Việt
- WordPiece: dùng trong BERT, tối ưu theo từ vựng đích
Hiểu tokenization giúp bạn tối ưu prompt (ít token = giảm chi phí API), debug lỗi encoding đa ngôn ngữ và thiết kế pipeline xử lý text chính xác hơn.
Embeddings - biến ngôn ngữ thành toán học
Sau khi tokenize, mỗi token được chuyển thành một vector số thực nhiều chiều gọi là embedding. Vector này mã hóa ý nghĩa của từ trong không gian toán học.
Kết quả: "King" và "Queen" có vector gần nhau; "King" - "Man" + "Woman" ≈ "Queen". Mô hình có thể tính toán sự tương đồng và quan hệ giữa các khái niệm mà không cần quy tắc cứng được lập trình trước.
Embedding là nền tảng của hai ứng dụng cực kỳ thực tế: semantic search (tìm kiếm theo nghĩa thay vì keyword) và hệ thống RAG (tìm tài liệu liên quan để cung cấp ngữ cảnh cho LLM).
Attention Mechanism - phép màu của Transformer
Self-attention là lý do Transformer vượt trội mọi kiến trúc trước đó. Thay vì đọc text tuần tự như RNN, Transformer phân tích đồng thời mối quan hệ giữa mọi cặp token trong câu.
Ví dụ câu: "Con mèo ngồi trên chiếc thảm vì nó mệt" - self-attention cho mô hình biết "nó" đang chỉ "con mèo" chứ không phải "chiếc thảm", dù hai từ cách nhau xa trong câu.
Multi-head attention chạy nhiều "đầu" song song, mỗi đầu học một loại quan hệ khác nhau (cú pháp, ngữ nghĩa, tham chiếu...). Đây là điểm mấu chốt giải thích tại sao LLM hiểu ngữ cảnh phức tạp tốt đến vậy - và cũng là lý do tại sao attention có độ phức tạp O(n²) khiến context dài trở nên đắt đỏ.
Fine-tuning - customize model cho nhu cầu riêng
Bạn không cần train model từ đầu để có AI chuyên biệt. Fine-tuning cho phép lấy model mã nguồn mở sẵn có và "dạy thêm" nó với dữ liệu domain cụ thể.
Các use case thực tế:
- AI pháp lý: fine-tune trên hàng nghìn hợp đồng và văn bản pháp luật
- AI y tế: fine-tune trên tài liệu y khoa và case bệnh nhân
- AI customer support: fine-tune trên FAQ và lịch sử ticket của công ty
- AI tài chính: fine-tune trên báo cáo và phân tích thị trường
Model mã nguồn mở phổ biến: Meta Llama, Mistral, Falcon, Gemma. Kỹ thuật hiệu quả nhất: LoRA và QLoRA - fine-tune chỉ một phần nhỏ tham số, giảm đáng kể yêu cầu GPU và chi phí. Chuyên gia fine-tuning đang kiếm $350-$700/giờ freelance, Staff/Principal engineers tại công ty lớn kiếm $250K-$350K+ với equity nặng.
Bước 4: RAG - kỹ năng đáng giá nhất năm 2026
Retrieval-Augmented Generation (RAG) là cách doanh nghiệp build ChatGPT riêng với dữ liệu nội bộ. Thay vì train model mới tốn kém, RAG cho LLM "tra cứu" tài liệu liên quan trước khi trả lời.
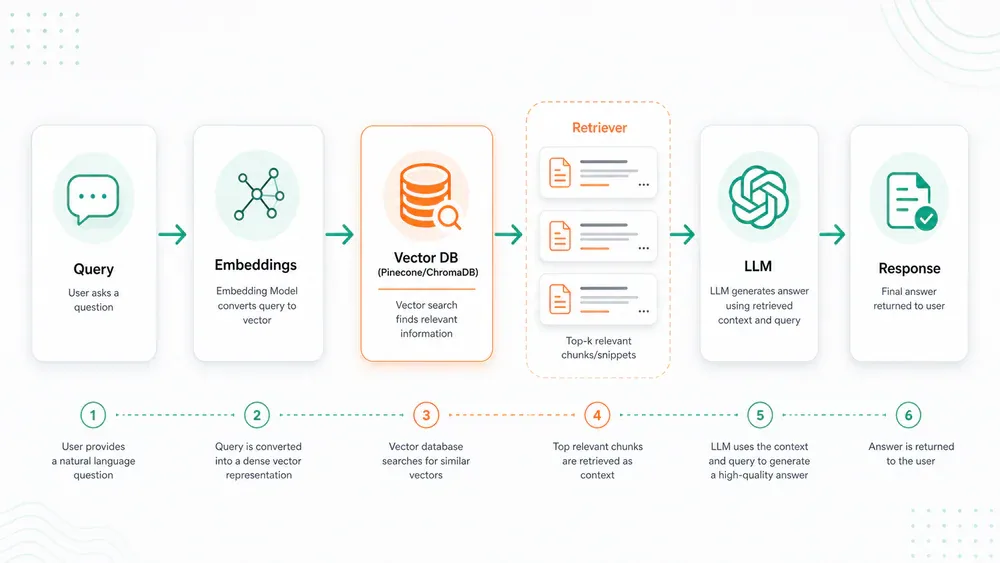
Kiến trúc RAG cơ bản gồm 4 thành phần:
- Embedding Model: chuyển câu hỏi và tài liệu thành vector
- Vector Database: lưu trữ và tìm kiếm vector nhanh - Pinecone, Weaviate, ChromaDB
- Retriever: tìm các đoạn tài liệu liên quan nhất với query
- LLM Generator: trả lời dựa trên ngữ cảnh đã truy xuất
RAG có giá trị đặc biệt vì giải quyết vấn đề cốt lõi của doanh nghiệp: AI có thể trả lời câu hỏi về dữ liệu nội bộ mà không cần expose dữ liệu ra ngoài. Engineer có kinh nghiệm deploy RAG production thực tế kiếm nhiều hơn $40-$80/giờ so với người chỉ build prototype trong notebook.
Bước 5: Triển khai thực tế - nơi tiền thật xuất hiện
Đây là bước mà hầu hết người học bỏ qua - và chính xác là lý do tại sao Platform Engineers được trả cao nhất. Notebook Jupyter không phải là sản phẩm.
Để triển khai LLM thực tế, bạn cần:
- FastAPI: serve model như một REST API có thể gọi từ bất kỳ đâu
- Docker: đóng gói môi trường để chạy nhất quán mọi nơi
- Kubernetes: orchestrate và scale nhiều container tự động
- GPU optimization: inference batching, quantization để giảm latency và chi phí
- Cloud: AWS, Google Cloud hoặc Azure cho infrastructure production
Platform Engineer - người sở hữu retrieval layer, eval harness, cost monitoring và on-call - là vai trò được tuyển dụng nhiều nhất trong thị trường LLM 2026. Theo KORE1, đây là loại "LLM engineer" mà hầu hết công ty thực sự cần, với base salary $210K-$290K cho vị trí senior. Công ty sẵn sàng trả giá này vì mỗi sai lầm trong production AI có thể tốn $10K+ mỗi giờ downtime.
Kết - Preview Phần 3
Nắm được 4 khái niệm cốt lõi và 2 bước triển khai này, bạn đã có đủ nền tảng kỹ thuật để bắt đầu xây sản phẩm AI thực sự. Phần 3 sẽ đi vào phần thực hành và kinh doanh: những project nên build đầu tiên, 5 con đường kiếm tiền cụ thể với LLM skills và lộ trình 12 tháng chi tiết từ zero đến remote engineer kiếm USD.
via DataCamp Transformers Guide · KORE1 Hiring Guide 2026 · Second Talent Rates 2026
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ