
- Anthropic vừa ra mắt Claude Sonnet 5 - model Sonnet agentic nhất từ trước đến nay, đạt 63.2% SWE-bench Pro cao hơn Sonnet 4.6 (58.1%) và gần bằng Opus 4.8 (69.2%).
- Giá introductory $2/M input token và $10/M output token, rẻ hơn GPT-5.5 và Gemini 3.1 Pro.
- Context window 1 triệu token, adaptive thinking bật mặc định, là model mặc định cho Free lẫn Pro plan.
- Tokenizer mới có thể tăng token count lên 1.35x so với Sonnet 4.6 - cần tính lại chi phí khi migrate.
TL;DR
- Anthropic vừa ra mắt Claude Sonnet 5 - Sonnet agentic nhất từ trước đến nay
- SWE-bench Pro: 63.2% - cao hơn Sonnet 4.6 (58.1%), xấp xỉ Opus 4.8 (69.2%)
- Giá introductory: $2/M input, $10/M output - rẻ hơn GPT-5.5 và Gemini 3.1 Pro
- Context window 1 triệu token, adaptive thinking bật mặc định, API id:
claude-sonnet-5 - Default model cho tất cả Free và Pro plan
- ⚠️ Tokenizer mới: cùng text tốn thêm 1.0-1.35x token so với Sonnet 4.6 - cần tính lại cost trước khi migrate
Từ workhorse trở thành agent
Trong lịch sử phát triển của Claude, dòng Sonnet luôn là lựa chọn thực dụng - đủ mạnh để dùng hằng ngày, đủ rẻ để chạy ở scale lớn. Nhưng suốt thời gian qua, nếu bạn muốn AI thực sự tự hành - lên kế hoạch, dùng tool, tự kiểm tra kết quả qua nhiều bước mà không cần nhắc nhở liên tục - bạn phải trả tiền cho Opus.
Claude Sonnet 5 thay đổi điều đó. Anthropic định vị đây là Sonnet agentic nhất từ trước đến nay: có thể điều khiển browser và terminal, thực thi task chuỗi dài mà chỉ vài tháng trước chỉ các model lớn như Opus mới làm được. Trong lineup hiện tại, Sonnet 5 đứng giữa Haiku 4.5 (nhẹ, nhanh) và Opus 4.8 (flagship) - nhưng khoảng cách với Opus đã thu hẹp đáng kể.
Anthropic gọi đây là bằng chứng rằng khả năng agentic không còn là đặc quyền của tier cao nhất. Câu hỏi cạnh tranh giờ không còn là "ai làm được agentic" mà là "ai làm rẻ nhất và đáng tin nhất mà không cần giám sát của người".
Khả năng agentic cốt lõi
Điểm mấu chốt của Sonnet 5 không nằm ở một benchmark duy nhất, mà ở khả năng duy trì task dài hạn mà không bị lạc context. Cụ thể:
- Self-verification tự động: Model tự kiểm tra output mà không cần prompt riêng. Testers mô tả: "Tôi yêu cầu investigate một bug, nó tự viết reproducing test, implement fix, rồi stash lại để confirm bug quay lại khi không có fix - tất cả trong một lần chạy duy nhất."
- Tool use bền vững: Browser, terminal, và các tool khác được điều khiển nhất quán qua session dài, không mất context giữa chừng
- Self-correction khi tool fail: Khi một tool call thất bại, model tự điều chỉnh thay vì dừng lại chờ user
- Adaptive thinking bật mặc định: Model tự điều chỉnh mức độ suy luận theo độ khó của task (có thể tắt bằng
"thinking": {"type": "disabled"})
Anthropic cũng cải thiện safety đáng kể: Sonnet 5 ít hallucinate hơn, ít sycophantic hơn, và tốt hơn trong việc chặn prompt injection attacks so với Sonnet 4.6. Cyber safeguards được bật mặc định - tương tự Opus 4.7/4.8.
Benchmark - con số nói lên tất cả
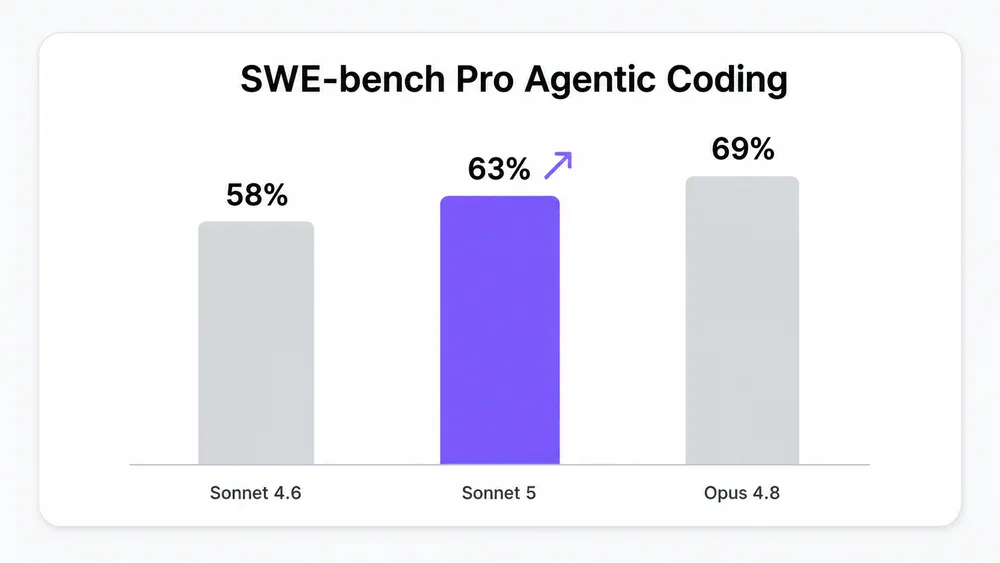
Sonnet 5 cải thiện trên mọi benchmark Anthropic đo, không có ngoại lệ:
| Benchmark | Sonnet 4.6 | Sonnet 5 | Opus 4.8 |
|---|---|---|---|
| SWE-bench Pro (agentic coding) | 58.1% | 63.2% | 69.2% |
| Terminal-Bench 2.1 | 67.0% | 80.4% | - |
| OSWorld-Verified (computer use) | 78.5% | 81.2% | - |
| Humanity's Last Exam (với tools) | 46.8% | 57.4% | 57.9% |
| GDPval-AA v2 (knowledge work) | - | 1,618 | 1,615 |
Đáng chú ý nhất là Terminal-Bench: từ 67% lên 80.4% - bước nhảy lớn nhất trong lần release này. Trên GDPval-AA v2 (knowledge work), Sonnet 5 thậm chí nhỉnh hơn Opus 4.8 một chút (1,618 vs 1,615), điều chưa từng xảy ra với một Sonnet model trước đây.
So sánh với Opus 4.8 và đối thủ
Vs Opus 4.8: Sonnet 5 thu hẹp khoảng cách đáng kể. Ở hầu hết task agentic coding, tool use, và knowledge work, hiệu năng của hai model gần tương đương - nhưng giá Sonnet 5 rẻ hơn nhiều (xem phần pricing). Opus 4.8 vẫn là lựa chọn tốt hơn cho các task yêu cầu độ chính xác cao nhất và công việc cybersecurity được cấp phép.
Một caveat: ở mức effort xhigh (extra high), Sonnet 5 có thể tốn chi phí tương đương hoặc cao hơn Opus 4.8 trong khi chất lượng tương đương - không có lợi thế kinh tế ở mức này.
Vs đối thủ:
- GPT-5.6 Sol (OpenAI, vừa preview): cũng định vị agentic, cho phép split tasks across subagents. Sonnet 5 rẻ hơn GPT-5.5 trên mỗi token.
- Gemini 3.5 Flash (Google, ra mắt tháng 5): cũng pitch agentic planning. Gemini Flash rẻ hơn Sonnet 5 trên mỗi token, nhưng Sonnet 5 đắt hơn Gemini 3.1 Pro.
Điểm chung của tất cả: agentic capability đã trở thành table stakes. Cuộc đua tiếp theo là ai chạy agent rẻ nhất và đáng tin nhất mà không cần giám sát.
Giá cả và tokenizer mới - quan trọng hơn bạn nghĩ
Pricing của Sonnet 5 có hai lớp cần chú ý:
Giá niêm yết:
- Introductory (đến 31/8/2026): $2/M input token, $10/M output token
- Standard (từ 1/9/2026): $3/M input, $15/M output
- So sánh: Opus 4.8 = $5/M input, $25/M output
Tokenizer mới - caveat quan trọng: Sonnet 5 dùng tokenizer mới, cùng loại được giới thiệu với Opus 4.7. Cùng một đoạn text có thể tốn 1.0 đến 1.35 lần token nhiều hơn so với Sonnet 4.6. Trong thực tế:
- Văn bản tiếng Anh: ~1.42x nhiều token hơn
- Văn bản tiếng Tây Ban Nha: ~1.33x
- Python code: ~1.28x
- Tiếng Hoa (Simplified Mandarin): ~1.0x (hầu như không đổi)
Anthropic giải thích introductory pricing được thiết kế để bù lại mức tăng này - về cơ bản là cost-neutral khi migrate từ Sonnet 4.6. Nhưng khi giá về mức standard từ tháng 9, chi phí thực tế trên mỗi task sẽ cao hơn.
Thực tế cần nhớ: Nếu bạn đang tính toán budget cho production workload, đừng so sánh giá per-token thuần túy. Hãy benchmark với task thực tế của bạn để đo token count thực trước khi migrate.
Ai nên dùng ngay
Feedback từ early access partners của Anthropic vẽ ra bức tranh khá rõ về những use case phù hợp nhất:
Developer và engineering team - đây là nhóm hưởng lợi rõ nhất. Sonnet 5 đặc biệt mạnh ở "brownfield code" - những phần codebase cũ, phức tạp, có race conditions và hidden tests. Thay vì chỉ patch symptom, model trace được root cause và ship durable fix. Lovable đã test với hàng chục pull request thực tế: "Nó tự carry từng PR đến kết quả đã được test và verify - giải phóng engineer tập trung vào judgment và sign-off cuối cùng."
Business automation - Zapier là ví dụ điển hình: giao cho Sonnet 5 task hai bước (cập nhật Salesforce account tiers, sau đó gửi email launch cho enterprise contacts), nó hoàn thành từ đầu đến cuối - trong khi các model Sonnet trước thường stall giữa chừng.
Operations team với computer-use agents - Pace dùng Sonnet 5 để chạy insurance workflows: submission intake, FNOL, loss runs - trực tiếp trên các hệ thống operational đang dùng.
Data analyst - ClickHouse dùng agents query live data và sinh insights theo yêu cầu: "Sonnet 5 reason trong ít bước hơn và đưa người dùng đến câu trả lời nhanh hơn rõ rệt."
Legal tech - Eve (legal AI platform): "Sonnet 5 nằm trên Pareto frontier cho plaintiff-law tasks - rõ nhất ở legal research và analysis, với price-to-performance ratio khiến việc migrate dễ quyết định."
Routing policy đơn giản Anthropic gợi ý:
- Sonnet 5: hầu hết agentic coding, tool use, knowledge work, business automation
- Opus 4.8: task yêu cầu độ chính xác cao nhất, deep research phức tạp, cybersecurity được cấp phép
- Haiku 4.5: high-volume, latency-sensitive calls không cần reasoning sâu
Kết
Claude Sonnet 5 là dấu mốc cho thấy agentic capability đang "trickle down" nhanh chóng từ flagship model xuống mid-tier. Những gì Opus làm được cách đây vài tháng, Sonnet làm được hôm nay với chi phí thấp hơn nhiều.
Điều quan trọng hơn benchmark là câu hỏi mà mọi AI lab đang đặt ra: không chỉ ai làm được agentic, mà ai làm nó đáng tin, rẻ, và không cần human-in-the-loop liên tục. Sonnet 5 là câu trả lời hiện tại của Anthropic - và tokenizer gotcha là lời nhắc nhở rằng số token trên giấy không bao giờ là toàn bộ câu chuyện.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ