
- Skills trong Hermes Agent là file Markdown YAML mà agent tự tạo ra sau mỗi task phức tạp.
- The Curator dọn dẹp chúng trong background.
- GEPA - được chấp nhận ICLR 2026 Oral - tối ưu skills offline, vượt GRPO 6-20% với ít hơn 35 lần rollouts.
- Chi phí: $2-10/run, không cần GPU.
TL;DR
Hermes Agent không chỉ nhớ fact - nó nhớ cách làm việc. Sau mỗi task phức tạp (5+ tool calls), agent tự tạo một SKILL.md ghi lại procedure đã dùng. The Curator chạy background để archive các skill cũ, không để catalog phình to vô kiểm soát. GEPA (ICLR 2026 Oral, MIT license) là pipeline tối ưu skills offline: đọc execution trace, hiểu tại sao thất bại, đề xuất cải tiến - vượt GRPO 6-20%, dùng ít hơn 35x rollouts, không cần GPU.
Skills là gì trong Hermes?
Nếu memory là những gì agent biết, thì skills là những gì agent biết làm. Skills là Markdown files với YAML frontmatter, đóng vai trò procedural memory: không phải fact mà là procedure.
Anatomy của một skill:
---
name: k8s-pod-debug
description: >
Activate for crashing pods, CrashLoopBackOff,
"why is my pod restarting", container failures.
version: 1.2.0
author: agent
platforms: [linux, macos]
---
## Procedure
1. Get pod status → check events → pull logs
2. Look for OOMKilled, ImagePullBackOff, config errors
## Pitfalls
- Forgetting --previous flag on restarted containers
## Verification
- Pod stays Running with 0 restarts for 5+ minutesĐể giữ token cost thấp, skills dùng progressive disclosure:
- Level 0: Agent thấy names + descriptions (~3k tokens cho toàn catalog)
- Level 1: Load full skill content khi thực sự cần
- Level 2: Drill vào specific reference files trong skill
Vòng lặp tự cải thiện
Đây là differentiator cốt lõi. Skill creation tự động trigger khi:
- Agent hoàn thành task phức tạp (5+ tool calls)
- Nó gặp errors hoặc dead ends và tìm ra working path
- User sửa approach của nó
- Nó discover một non-trivial workflow
Vòng lặp: agent gặp vấn đề → giải quyết bằng trial and error → lưu successful approach dưới dạng SKILL.md → lần sau gặp vấn đề tương tự, load skill và follow proven procedure thay vì reinvent from scratch.
Tool skill_manage hỗ trợ sáu actions: create, patch (targeted fix, token-efficient, preferred), edit (full rewrite), delete, write_file, và remove_file.
The Curator - garbage collection cho skill library
Không có maintenance, agent-created skills sẽ pile up. Bạn sẽ có hàng chục narrow, overlapping playbooks waste tokens và pollute catalog. The Curator là background maintenance system xử lý vấn đề này.
The Curator chạy theo inactivity check (không phải cron daemon): nếu 7 ngày đã qua kể từ lần chạy cuối và agent đã idle 2+ giờ, một background fork của agent spin up với prompt cache riêng, không bao giờ đụng đến active conversation.
Hai phases:
- Automatic transitions (deterministic, không cần LLM): Skills unused 30 ngày → stale. Skills unused 90 ngày → archive vào
~/.hermes/skills/.archive/ - LLM review (tối đa 8 iterations): Forked agent survey tất cả agent-authored skills, quyết định per-skill: keep, patch, consolidate, hoặc archive
Hai ràng buộc quan trọng:
- The Curator không bao giờ đụng đến bundled skills hoặc hub-installed skills. Chỉ agent-authored.
- The Curator không bao giờ auto-delete. Worst case là archival - recoverable bằng một lệnh.
Trước mỗi Curator pass, Hermes tạo tar.gz snapshot toàn bộ skills directory. Rollback là một lệnh duy nhất, và rollback chính nó cũng có thể undo.
GEPA - tối ưu skills offline mà không cần GPU
Vòng lặp tự cải thiện trong Hermes có một điểm yếu đã biết: agent gần như luôn tự đánh giá mình làm tốt, ngay cả khi không phải vậy. Community feedback đã confirm điều này. Cùng system tự generate skills có thể overwrite manual customizations với các phiên bản tệ hơn.
Đây là chỗ GEPA xuất hiện.
GEPA (Genetic-Pareto Prompt Evolution) không build trong Hermes runtime. Nó nằm trong companion repository NousResearch/hermes-agent-self-evolution và hoạt động như một offline optimization pipeline. Đã được chấp nhận là ICLR 2026 Oral paper, MIT licensed.
Core idea: thay vì hỏi agent "bạn làm tốt không?", GEPA đọc execution traces để hiểu tại sao thứ thất bại, sau đó đề xuất targeted improvements thông qua evolutionary search.
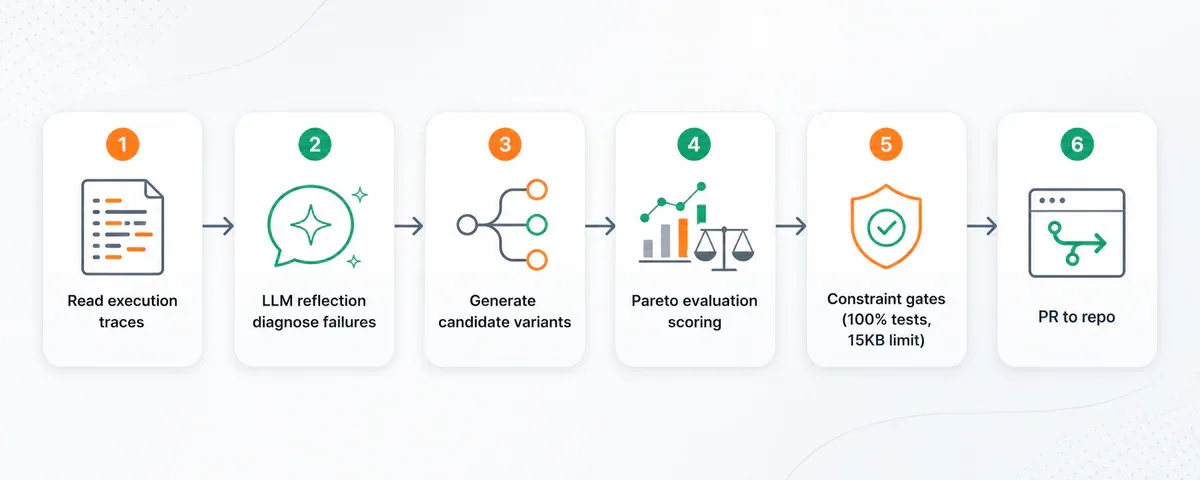
Pipeline:
- Đọc skill hiện tại từ Hermes repo
- Generate evaluation dataset (synthetic test cases via Claude Opus, real session history từ SQLite, hoặc hand-curated golden sets)
- Chạy GEPA optimizer: đọc execution traces → hiểu failure points → generate candidate variants
- Evaluate candidates với LLM-as-judge scoring dùng rubrics (không phải binary pass/fail)
- Apply constraint gates: test suite phải pass 100%, skills ≤15KB, caching compatibility preserved, semantic purpose không drift
- Best variant → PR chống Hermes repo. Không bao giờ direct commit.
Không cần GPU. Mọi thứ chạy qua API calls. Chi phí: khoảng $2-10/optimization run.
GEPA vs GRPO - con số cụ thể
Theo paper ICLR 2026, qua sáu tasks:
- GEPA vượt GRPO trung bình 6%, và lên đến 20% trong các trường hợp tốt nhất
- GEPA dùng ít hơn 35 lần rollouts so với GRPO
- GEPA vượt MIPROv2 (leading prompt optimizer) hơn 10%, bao gồm +12% accuracy trên AIME-2025
GRPO học từ scalar reward - một con số nói lên thành công hay thất bại. GEPA học từ natural language reflection - đọc toàn bộ execution trace, hiểu tại sao thất bại, đề xuất targeted fix. Với LLM, ngôn ngữ tự nhiên là medium phong phú hơn nhiều so với gradient đơn thuần.
Nên thử GEPA khi bạn đạt đến điểm agent không cải thiện được thêm với approach hiện tại, nhưng chưa muốn đầu tư vào full fine-tuning hay RL-based fine-tuning.
Kết
SOUL.md định nghĩa identity. Runtime loop capture experience. The Curator giữ library sạch. GEPA đảm bảo những gì trong library thực sự hoạt động tốt. Đây là full theory của Hermes - một hệ thống compound theo thời gian thay vì chỉ thực thi theo lệnh.
Bài tiếp theo: hướng dẫn cài đặt từ đầu và setup ba agent chuyên biệt - Designer, Programmer, Researcher - mỗi agent với SOUL.md riêng, memory riêng, và Telegram bot riêng.
via Hermes Self-Evolution GitHub - GEPA Paper arXiv:2507.19457 - Curator Docs
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ