
- Hermes Agent vừa thêm Mixture of Agents - preset cho phép ghép 2 model bất kỳ thành một virtual model duy nhất.
- Trên HermesBench, combo Opus 4.8 + GPT-5.5 đạt 0.8202, cao hơn Opus đơn lẻ 8% và GPT-5.5 đơn lẻ 11%.
- Reference model lo phân tích, aggregator giữ độc quyền tool call và viết câu trả lời cuối.
- Hỗ trợ trộn provider OpenAI, Anthropic, OpenRouter, local model thoải mái.
TL;DR
Nous Research vừa rollout Mixture of Agents (MoA) cho Hermes Agent: tính năng cho phép user ghép 2 hoặc nhiều LLM lại thành một virtual model duy nhất, đặt tên tuỳ ý và chọn từ model picker như bất kỳ model thường nào. Mỗi turn, các model chạy song song theo 2 vai - reference đưa phân tích, aggregator giữ độc quyền tool call và viết câu trả lời cuối. Trên HermesBench, combo Opus 4.8 + GPT-5.5 đạt 0.8202 điểm, cao hơn Opus đơn lẻ 8% và GPT-5.5 đơn lẻ 11%.

Mixture of Agents trong Hermes Agent là gì
Trong Hermes Agent, MoA được expose như một virtual model provider. Khi bạn cấu hình xong preset, nó xuất hiện trong dropdown chọn model y hệt GPT-5.5 hoặc Opus 4.8 đơn lẻ - chỉ khác là dưới mui xe có nhiều model chạy cùng lúc.
Cách dùng đơn giản tới mức gần như không cần học. Vào Dashboard → Models → Mixture of Agents, chọn 2 model bất kỳ (một làm reference, một làm aggregator), đặt tên preset, save. Hoặc dùng terminal lệnh hermes moa configure. User Vaibhav Sisinty diễn tả ngắn gọn: "You pick any two models. GPT-5.5 and Claude Opus for example. Name the combo anything you want."
Toàn bộ feature gốc của Hermes vẫn hoạt động bình thường khi user chọn MoA preset: persistent memory, tool use, custom skills, session dài, cross-channel messaging (CLI, Telegram, Discord, Slack, WhatsApp). Không có gì bị tắt, không có chỗ phải đụng config.yaml nếu không muốn.
Cách hoạt động: reference và aggregator
Mỗi khi user gửi prompt, Hermes Agent dispatch hội thoại tới các model song song theo 2 vai khác nhau.
Reference model chạy trước, nhận text hội thoại trần (không có schema của tool nào hết). Vai trò: đọc context, đưa ra phân tích, gợi ý cách tiếp cận. Reference không gọi tool, không reply trực tiếp user. Theo official docs, thiết kế này "keep calls cheap and avoid strict-provider rejections" - tức là tránh việc một provider khắt khe (như Anthropic) reject request vì tool schema không khớp.
Aggregator chạy sau, nhận đồng thời 2 input: hội thoại gốc, và output của các reference được append như private context. Aggregator mới là model có quyền tool call, thực thi action thực tế, và viết câu trả lời cuối user thấy. Output user nhận về vẫn sạch một dòng - không thấy bất kỳ trace nào của reference output.
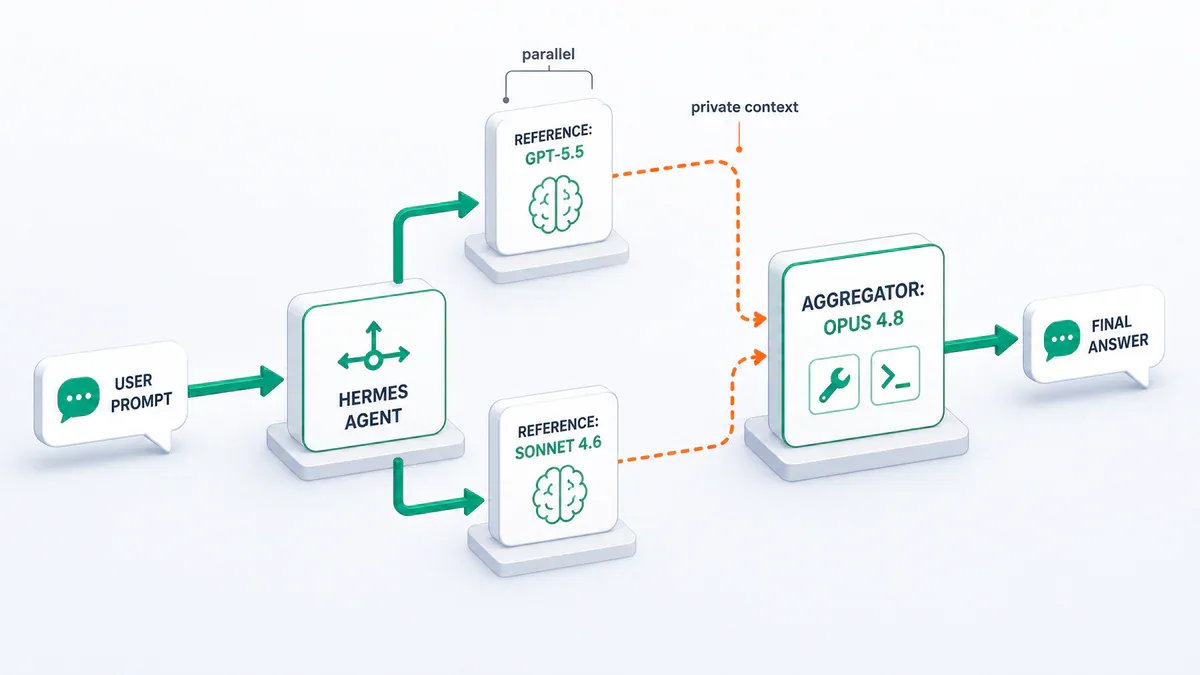
Tách vai như vậy giải quyết được một vấn đề kỹ thuật khó: ép 2 model phải agree trên cùng một tool call schema gần như không bao giờ chạy ổn, vì mỗi provider format khác nhau, version khác nhau. Hermes chọn cách cho aggregator độc quyền - một model duy nhất chịu trách nhiệm tool, nhưng vẫn được nhận lời khuyên từ các model còn lại.
Số liệu HermesBench: cao hơn cả thành phần mạnh nhất
Nous Research dùng benchmark nội bộ tên HermesBench để đo. Đây là benchmark agentic sắp publish full leaderboard. Trong tweet, Nous công bố:
- MoA cao hơn Opus 4.8 đơn lẻ 8%
- MoA cao hơn GPT-5.5 đơn lẻ 11%

Number chi tiết trong docs khớp khít: combo Opus 4.8 + GPT-5.5 đạt 0.8202, Opus 4.8 đơn lẻ 0.7607, GPT-5.5 đơn lẻ 0.7412. Tức MoA cao hơn component mạnh nhất (Opus) khoảng 6 điểm tuyệt đối - rất hiếm khi một ensemble đơn giản beat được model mạnh nhất, vì đa số trường hợp aggregator chỉ lặp lại câu trả lời của model giỏi nhất chứ không synthesize được gì mới.
Với SWE-bench Pro - benchmark coding agentic phổ biến - baseline của 2 model gốc là Opus 4.8 69.2% và GPT-5.5 58.6%. Nous chưa publish điểm SWE-bench Pro cho MoA, nhưng tỉ lệ cải thiện trên HermesBench cho thấy gain không chỉ là margin of error.
Khác gì so với MoA paper truyền thống
MoA gốc trong arxiv 2409.07487 stack nhiều layer reference rồi mới tới aggregator - giống deep network. Phiên bản Hermes chọn variant đơn giản hơn: 1 layer reference, 1 aggregator. Trade-off rõ ràng:
- Đỡ phức tạp setup: user không cần hiểu khái niệm layer, chỉ chọn 2 model rồi save.
- Latency thấp hơn: wall-clock = max(reference latency) + aggregator latency, không phải sum-of-layers.
- Vẫn beat strongest component: điểm HermesBench chứng minh kiến trúc 1-layer cũng đủ tạo gain ý nghĩa.
Một KOL Hermes là witcheer test setup mở rộng hơn: 3 reference (GPT-5.5, DeepSeek-V4-Pro, Sonnet 4.6) + 1 aggregator (Opus 4.8) chạy ngay trong 1 Hermes box bình thường. Tức kiến trúc không bị fix cứng 2 model - user muốn add nhiều reference cũng được, miễn chấp nhận trả tiền cho từng model call.
Trộn provider thoải mái: OpenAI, Anthropic, OpenRouter, local
Một trong những điểm nổi nhất: MoA không phân biệt provider. Default example trong docs dùng đồng thời openai-codex, openrouter (chạy DeepSeek), và anthropic. Bạn có thể:
- Mix close-source (Opus 4.8 từ Anthropic) với open-source (DeepSeek-V4-Pro qua OpenRouter) để cân cost.
- Trộn frontier với local model (Ollama, vLLM) để xử lý private data nhạy cảm.
- Dùng Nous Portal - subscription có 300+ model - làm pool chính.
Tweet Vaibhav nhấn: "You can mix any providers too. OpenAI, Anthropic, OpenRouter, local models. Whatever you have access to." Đây cũng là lý do Hermes đặt MoA dưới dạng virtual provider - ổ cắm chung cho mọi backend.
Ai nên thử ngay
MoA không phải tính năng dành cho mọi task. Sweet spot:
- Hard agentic task: planning nhiều bước, refactor codebase dài, debug session lặp nhiều turn. Đây là môi trường ensemble thực sự phát huy giá trị.
- Người không có gated access: nếu bạn không phải early-access list của Anthropic hay OpenAI, MoA mở ra một virtual model mạnh hơn cả frontier publicly available. Theo Nous: "capabilities beyond the publicly available frontier."
- Power user CLI/chatops: Hermes Agent vốn mạnh ở CLI, Telegram, Discord, Slack. MoA cộng thêm 1 lớp synthesis mà không phá vỡ luồng quen.
Giới hạn cần biết trước khi bật
- Cost scale theo số reference: mỗi turn = N model call song song + 1 aggregator call. Token bill nhân lên trực tiếp. Nếu budget eo hẹp, chỉ nên bật MoA cho task khó.
- Latency cao hơn single model: dù song song, wall-clock vẫn dài hơn 1 model đơn. Real-time chat nhanh không phải target.
- Block recursive MoA: aggregator không được là một MoA preset khác. Quy tắc cố tình chặn để tránh loop chi phí mất kiểm soát.
- Reference không tool call: nếu task buộc reference tự gọi tool (ví dụ pattern multi-agent có specialized worker), kiến trúc hiện tại không cover. Aggregator độc quyền tool.
Tóm lại
MoA trong Hermes Agent là cách hợp lý để khai thác fact đơn giản: 2 model frontier suy luận song song rồi tổng hợp thường tốt hơn 1 model đơn. Điểm khéo của Nous là biến kỹ thuật này thành một virtual model dropdown - user không phải code framework riêng, không phải orchestrate prompt thủ công, không phải lo tool schema xung đột.
Cộng với fact Hermes Agent là open-source MIT và hỗ trợ trộn mọi provider, MoA hạ ngưỡng để test ensemble model một cách thực tế. Nếu bạn đang xài Hermes cho dev workflow, đặt một preset Opus + GPT-5.5 chạy thử vài task khó - rồi so điểm output với từng model đơn lẻ là cách tốt nhất để biết MoA có đáng cho usecase của bạn không.
via Hermes Agent Docs - Mixture of Agents · via Nous Research · via Vaibhav Sisinty
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ