
- ProgramBench - benchmark mới từ nhóm SWE-Bench - vừa công bố kết quả gây sốc: Claude Opus 4.7, GPT-5.4, Gemini 3.1 Pro đều đạt 0% khi được yêu cầu rebuild phần mềm thực tế từ đầu.
- Lỗi không nằm ở model - mà nằm ở Harness.
- Harness Engineering là kỹ thuật xây dựng "bộ kiểm soát" bao quanh LLM, được tóm gọn bằng công thức: Agent = Model + Harness.
- Bài này giải thích tại sao công thức đó quyết định tất cả.
TL;DR
ProgramBench (tháng 5/2026) yêu cầu 9 mô hình AI rebuild 200 dự án phần mềm thực tế từ đầu - không cho lên mạng, không đo code similarity, chỉ verify hành vi cuối. Kết quả: tất cả đạt 0% success rate. Không phải vì model yếu. Mà vì thiếu Harness.
Harness Engineering là ngành kỹ thuật xây dựng "bộ kiểm soát" bao quanh LLM - bao gồm context management, tool execution, task orchestration, feedback loops, và architectural guardrails. Công thức của ngành: Agent = Model + Harness.
Con số gây sốc từ ProgramBench
Tháng 5/2026, nhóm nghiên cứu đứng sau SWE-Bench công bố bài báo "ProgramBench: Can Language Models Rebuild Programs From Scratch?" (arXiv:2605.03546).
Phương pháp đánh giá khác hoàn toàn các benchmark trước: AI nhận được một chương trình và documentation của nó, sau đó phải tự architect và implement lại codebase sao cho hành vi khớp với chương trình gốc. Không được lên mạng. Không đo code similarity. Chỉ verify final behavior.
200 task được thiết kế, từ CLI tools nhỏ như jq, ripgrep đến các dự án lớn như FFmpeg, SQLite, PHP interpreter.
Kết quả sau khi test 9 mô hình hàng đầu:
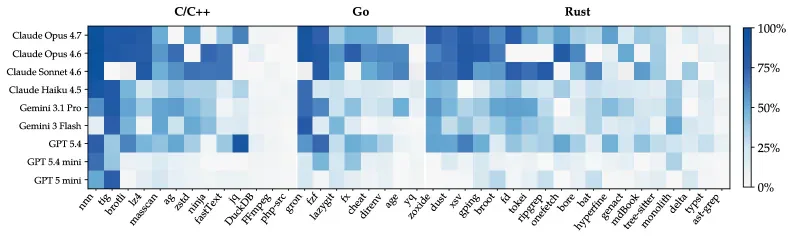
- Claude Opus 4.7, GPT-5.4, Gemini 3.1 Pro: 0% success rate
- Model tốt nhất trong 9 model được test: chỉ pass 95% test trên đúng 3% tasks
- Hành vi chung: model nhồi toàn bộ logic vào 1 file monolithic, không có module hóa, không có kiến trúc, không có kế hoạch dài hạn
Điều này không có nghĩa AI không viết được code. Nó viết rất nhiều code, viết hàm rất đẹp. Nhưng yêu cầu dựng cả một dự án thực chạy được là điều khác hoàn toàn.

Vậy Harness Engineering là gì?
Harness (nghĩa đen: dây cương, yên cương) là tổng hợp mọi thứ bao quanh LLM ngoại trừ bản thân model. Công thức được ngành AI engineering đồng thuận:
Agent = Model + Harness
Một AI agent không có harness giống như một con ngựa thuần chủng không có dây cương - dù mạnh đến đâu cũng không thể đi đúng hướng và chạy đúng đích.
Harness bao gồm: Hooks, Skills, MCP servers, CLAUDE.md / AGENTS.md, sub-agents, plugins, tools - và quan trọng hơn là cách tất cả những thứ đó được thiết kế để hoạt động như một hệ thống.
Bằng chứng hiệu quả của harness không thiếu:
- LangChain experiment: Cùng model gpt-5.2-codex, không đổi một trọng số nào, chỉ tối ưu harness bao quanh - điểm Terminal-Bench 2.0 tăng từ 52.8 lên 66.5, ranking nhảy từ ngoài Top 30 vào Top 5.
- OpenAI Codex experiment: 3 người, 5 tháng, drive Codex tạo ra ~1 triệu dòng code và merge ~1.500 PRs. Mọi thứ là nhờ harness, không phải model mạnh hơn.
OpenAI team tự mô tả: trọng tâm công việc của họ đã không còn là viết code, mà là bốn việc khác - thiết kế môi trường, làm rõ ý định, xây feedback loop, và giúp Agent tự nhìn thấy - tự verify - tự sửa lỗi.
5 chiều cốt lõi của một Harness hoàn chỉnh
Một Harness tốt không phải tập hợp ngẫu nhiên của tools và prompts. Nó cần hoàn chỉnh trên 5 chiều:
- Quản lý ngữ cảnh - Bộ nhớ 3 lớp: đảm bảo AI luôn biết mình đang làm gì, đã làm gì, cần làm gì tiếp theo
- Năng lực thực thi - Tools, MCP, Skills: không chỉ sinh text mà thực sự hành động trong môi trường thực
- Điều phối tác vụ - Ralph Loop: chia nhiệm vụ dài thành bước ngắn, duy trì tiến độ qua nhiều context windows
- Cơ chế phản hồi - Computational và Inferential sensors: AI phải verify và sửa lỗi trước khi con người nhìn thấy
- Kiến trúc bảo hộ - Pre-commit hooks, linter, CI gate: ngăn code tệ đi vào codebase ngay từ đầu
Phần tiếp theo của series sẽ đi sâu vào từng chiều với ví dụ cụ thể từ Anthropic, OpenAI, và Vercel.
Điều bạn có thể áp dụng ngay hôm nay
Trước khi đọc tiếp series, hãy tự kiểm tra:
- Project của bạn có file
CLAUDE.mdhoặcAGENTS.mdkhông? Nó có cập nhật không? - Khi AI làm xong một tác vụ, có gì verify rằng nó thật sự đúng không - hay bạn tự kiểm tra bằng mắt?
- Khi AI bị "quên" (context reset), nó có cách nào biết mình đang làm đến đâu không?
Nếu câu trả lời là "không" cho cả 3, harness của bạn gần như trống rỗng - và ProgramBench 0% là kết quả bạn cũng sẽ nhận được.
Kết
ProgramBench 0% không phải tin xấu về model. Đó là tin về harness - và harness là thứ bạn có thể kiểm soát được.
Phần 2 của series sẽ đi vào chi tiết từng chiều: Context Management với bộ nhớ 3 lớp, Execution với triết lý "ít tool hơn = mạnh hơn", Task Orchestration với Ralph Loop, Feedback Mechanisms, và Architectural Guardrails.
via ProgramBench Paper (arXiv:2605.03546) · Martin Fowler - Harness Engineering · OpenAI - Harness Engineering
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ