
- LangChain tăng 13.7 điểm trên TerminalBench 2.0 mà không đổi model - chỉ thay harness.
- Agent harness là toàn bộ cơ sở hạ tầng bao quanh LLM: orchestration loop, tools, memory, context management, guardrails.
- 12 thành phần phân biệt chatbot demo với agent production-grade.
TL;DR
LangChain thay đổi chỉ infrastructure xung quanh model - giữ nguyên model weights - và nhảy từ ngoài Top 30 lên Top 5 trên TerminalBench 2.0 (+13.7 điểm). Stanford Meta-Harness đạt 76.4% pass rate bằng cách để LLM tự tối ưu infrastructure của mình, vượt mọi hệ thống thiết kế tay. Kết luận không thể phủ nhận: harness là sản phẩm, không phải model.
Harness là gì - và tại sao bạn đang bỏ qua nó
Khi bạn nói "tôi đã xây một agent", thực ra bạn đã xây một harness rồi trỏ nó vào một model. Agent là hành vi nổi lên - khả năng tự định hướng, dùng tool, tự sửa lỗi. Harness là cỗ máy tạo ra hành vi đó.
Vivek Trivedy (LangChain) tóm gọn trong một câu: "If you're not the model, you're the harness."
Beren Millidge làm rõ hơn trong bài "Scaffolded LLMs as Natural Language Computers" (2023): LLM thô là CPU không có RAM, disk, hay I/O. Context window = RAM. External databases = disk. Tool integrations = device drivers. Harness = hệ điều hành. Chúng ta đã tái phát minh kiến trúc Von Neumann cho LLM.
Thuật ngữ "agent harness" được định nghĩa chính thức đầu 2026, nhưng khái niệm đã tồn tại từ trước. Anthropic nói thẳng trong tài liệu Claude Code: "The SDK is the agent harness that powers Claude Code." OpenAI dùng cùng framing cho Codex.
Ba tầng kỹ thuật - từ prompt đến harness
Phần lớn developer dừng lại ở tầng 1 hoặc 2:
- Prompt engineering - soạn instructions cho model nhận vào.
- Context engineering - kiểm soát model thấy gì và khi nào.
- Harness engineering - bao gồm cả hai tầng trên, cộng toàn bộ application infrastructure: tool orchestration, state persistence, error recovery, verification loops, safety enforcement, lifecycle management.
Harness không phải wrapper quanh prompt. Đây là toàn bộ hệ thống làm cho hành vi agent tự động trở nên khả thi.
12 thành phần của một production harness
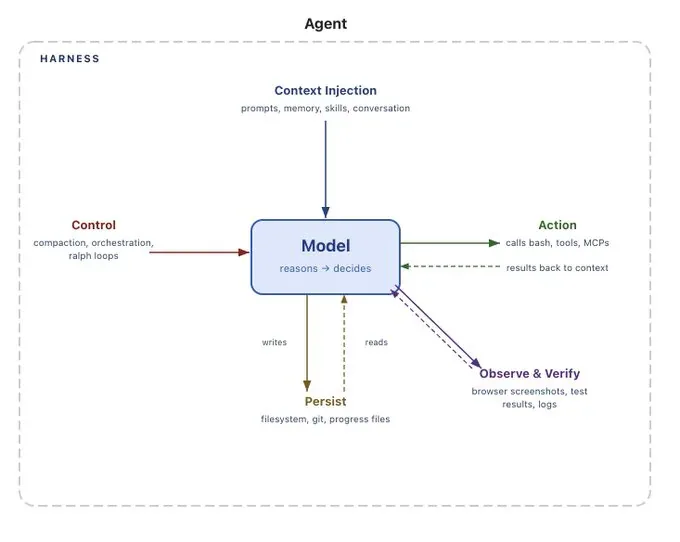
Tổng hợp từ Anthropic, OpenAI, LangChain và cộng đồng practitioner, một production agent harness có 12 thành phần riêng biệt:
- Orchestration Loop - nhịp đập của harness; triển khai vòng Thought-Action-Observation (TAO/ReAct). Anthropic gọi runtime là "dumb loop" - mọi intelligence nằm trong model.
- Tools - định nghĩa dưới dạng schema inject vào context. Claude Code có 6 danh mục: file operations, search, execution, web access, code intelligence, subagent spawning.
- Memory - short-term (conversation history) và long-term (CLAUDE.md, MEMORY.md; LangGraph JSON Stores; OpenAI Sessions với SQLite/Redis). Claude Code dùng 3-tier hierarchy: index nhẹ ~150 chars/entry, topic files chi tiết, transcripts thô.
- Context Management - chống context rot: performance giảm 30%+ khi key content nằm ở giữa window. Chiến lược: Compaction, Observation masking, Just-in-time retrieval, Sub-agent delegation.
- Prompt Construction - phân cấp: system prompt → tool definitions → memory files → conversation history → user message hiện tại.
- Output Parsing - modern harnesses dùng native tool calling (structured
tool_callsobjects) thay vì parse free-text. - State Management - LangGraph: typed dict qua graph nodes. OpenAI: 4 chiến lược (application memory, SDK sessions, Conversations API, response chaining). Claude Code: git commits làm checkpoints.
- Error Handling - lỗi compound nhanh: 10 bước x 99% success/bước = 90.4% end-to-end. LangGraph phân 4 loại: transient, LLM-recoverable, user-fixable, unexpected.
- Guardrails & Safety - OpenAI: input/output/tool guardrails + tripwire halt ngay. Anthropic gate ~40 tool capabilities độc lập, 3 giai đoạn: trust establishment, permission check, user confirmation.
- Verification Loops - rules-based (tests, linters), visual feedback (Playwright screenshots), LLM-as-judge. Boris Cherny (creator Claude Code): cho model cách verify work của mình cải thiện chất lượng 2-3x.
- Subagent Orchestration - Claude Code: Fork, Teammate, Worktree. OpenAI: agents-as-tools, handoffs. LangGraph: nested state graphs.
- Lifecycle Management - cách agent khởi động, persist qua sessions, và kết thúc.
Vòng lặp trong thực tế - 7 bước
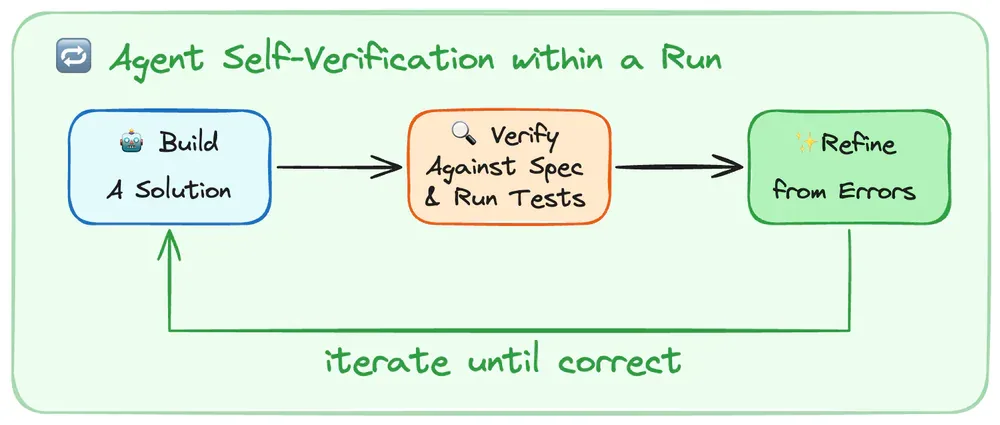
Mỗi chu kỳ orchestration loop diễn ra qua 7 bước: (1) Prompt Assembly - ghép system prompt + tool schemas + memory + history; (2) LLM Inference - gửi tới model API; (3) Output Classification - có tool calls thì execute, không có thì final answer; (4) Tool Execution - validate, check permissions, chạy trong sandbox, capture results; (5) Result Packaging - format thành LLM-readable, lỗi trả về dưới dạng error results; (6) Context Update - append results, trigger compaction nếu gần limit; (7) Loop - quay lại bước 1.
Điều kiện dừng: không có tool calls, đạt max turn limit, hết token budget, guardrail tripwire kích hoạt, user interrupt, hoặc safety refusal. Task đơn giản: 1-2 turns. Task refactoring phức tạp: hàng chục tool calls qua nhiều turns.
Benchmark và so sánh framework
LangChain cải thiện deepagents-cli từ 52.8% lên 66.5% trên Terminal Bench 2.0 (+13.7 điểm) chỉ bằng cách thay harness, giữ nguyên model GPT-5.2-Codex. Bí quyết: PreCompletionChecklistMiddleware (force self-verification trước khi exit) và LoopDetectionMiddleware (phát hiện doom loops, inject "hãy xem lại approach" sau N lần edit cùng file).
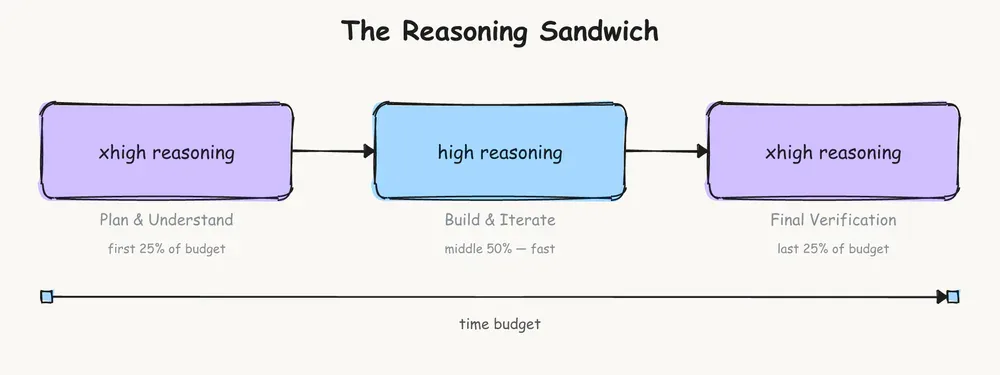
Chiến lược phân bổ compute: "Reasoning Sandwich" xhigh-high-xhigh - tối đa reasoning ở planning và final verification, tiết kiệm ở giữa để tránh timeout. Chạy xhigh toàn bộ: 53.9% vì agent bị timeout. Reasoning Sandwich: 66.5%.
So sánh 3 framework lớn:
- Anthropic Claude Agent SDK - "dumb loop" runtime, Gather-Act-Verify cycle, ~40 tool capabilities gated độc lập, git commits làm checkpoints.
- OpenAI Agents SDK - code-first Python, Runner class (async/sync/streamed), Tripwire mechanism halt ngay khi vi phạm safety.
- LangGraph - explicit state graph với conditional edges, tracing-first để debug failure modes ở scale, 4 loại lỗi có chiến lược xử lý riêng.
Kết - Harness là sản phẩm
Hai sản phẩm dùng cùng model có thể có hiệu năng khác biệt hoàn toàn chỉ vì harness khác nhau. Bằng chứng TerminalBench: thay harness = nhảy 20+ hạng. Đây là nơi engineering thực sự xảy ra - quản lý context như tài nguyên khan hiếm, thiết kế verification loops bắt lỗi trước khi compound, xây memory systems tạo continuity không hallucinate.
Xu hướng đang đi về harnesses mỏng hơn khi model cải thiện. Nhưng harness sẽ không biến mất - ngay cả model mạnh nhất vẫn cần gì đó quản lý context window, execute tool calls, persist state, và verify work.
Lần tới agent của bạn fail - đừng đổ lỗi cho model. Hãy nhìn vào harness.
via Akshay Pachaar - LangChain Blog - Anthropic Engineering - Harness Engineering
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ