
- PageIndex là framework RAG mã nguồn mở của VectifyAI, loại bỏ hoàn toàn vector database và document chunking.
- Mafin 2.5 - hệ thống phân tích tài chính dùng PageIndex - đạt 98.7% trên FinanceBench, so với ~50% của vector RAG truyền thống.
- Thay vì tính cosine similarity, PageIndex xây cây phân cấp từ tài liệu rồi dùng LLM lý luận qua cây để truy xuất đúng section.
- MIT License, 31.5k GitHub stars, hỗ trợ MCP tích hợp trực tiếp vào Claude, Cursor và các AI agent frameworks.
TL;DR
PageIndex là một framework RAG theo kiểu "vectorless, reasoning-based" - tức là không dùng vector database, không chunk tài liệu thành từng mảnh, không tính cosine similarity. Thay vào đó, nó xây một cây phân cấp (như Table-of-Contents thông minh) từ PDF, rồi dùng LLM lý luận qua cây đó để tìm đúng section cần thiết.
Kết quả: Mafin 2.5 - hệ thống phân tích tài chính do VectifyAI xây bằng PageIndex - đạt 98.7% accuracy trên FinanceBench. Vector RAG truyền thống dừng ở ~50%. Khoảng cách gần 49 percentage points không phải do tìm được embedding model tốt hơn - mà vì họ bỏ hẳn embedding đi.
Vấn đề mà vector RAG không thể giải
Bất kỳ ai đã build RAG system trên tài liệu chuyên nghiệp (báo cáo tài chính, hợp đồng pháp lý, thuyết minh kỹ thuật) đều gặp cùng một vấn đề: hỏi câu cụ thể về trang 47 của một SEC filing, nhưng hệ thống trả về chunks semantically similar mà structurally sai hoàn toàn.
Vì sao? Vector RAG có ba điểm yếu cốt tử với tài liệu dài và có cấu trúc:
- Context loss từ chunking. Một bảng tài chính bị cắt đôi. Header row nằm ở chunk 14, data row cần thiết ở chunk 15. Cả hai chunk riêng lẻ đều không trả lời được câu hỏi.
- Semantic ambiguity theo quy mô. Một annual report 200 trang nhắc đến "operating income" 60 lần. Vector similarity xếp hạng 60 instances đó gần như đồng đều - câu trả lời thật sự có thể không bao giờ lọt vào top-3.
- Cross-reference blindness. Trang 12 ghi "see Appendix B for details" nhưng Appendix B ở trang 87. Vector RAG không có cơ chế nào để theo được liên kết đó.
Nguyên nhân gốc rễ: similarity không bằng relevance. Tìm kiếm vector luôn tìm ra đoạn text giống nhất query - nhưng relevance đôi khi đòi hỏi hiểu cấu trúc, theo tham chiếu, và lý luận xuyên section.
PageIndex hoạt động như thế nào
PageIndex thực hiện retrieval theo hai bước:
Bước 1 - Xây cây chỉ mục: Khi nạp tài liệu, thay vì embed từng chunk, PageIndex dùng LLM phân tích cấu trúc document và tạo cây phân cấp - về bản chất là Table-of-Contents thông minh, lưu dưới dạng JSON. Mỗi node trong cây có: tiêu đề section, tóm tắt nội dung, khoảng trang tương ứng, và các node con (subsections). Một SEC filing 50 trang tạo ra cây chỉ khoảng 30-50 nodes - toàn bộ fit vào context window, có thể inspect trực tiếp.
Bước 2 - Lý luận qua cây: Khi có query, PageIndex truyền cây vào LLM và yêu cầu nó lý luận xem node nào nhiều khả năng chứa câu trả lời. LLM đọc tiêu đề và tóm tắt của từng node, áp dụng domain reasoning, và trả về danh sách node ID cần retrieve - kèm đầy đủ reasoning trace cho thấy path đã đi qua.
Điều này cho phép LLM theo được cross-reference ("see Appendix B" → đi thẳng tới node Appendix B), thực hiện multi-hop reasoning (tính year-over-year change đòi hỏi lấy số từ hai section khác nhau), và trả về kết quả với đầy đủ audit trail - biết chính xác answer đến từ trang nào, section nào.
Con số đáng chú ý
Benchmark FinanceBench là tiêu chuẩn ngành để đánh giá LLM trên financial document QA - dùng real SEC filings, yêu cầu câu trả lời chính xác từ 10-K và 10-Q reports phức tạp. Đây là kết quả:
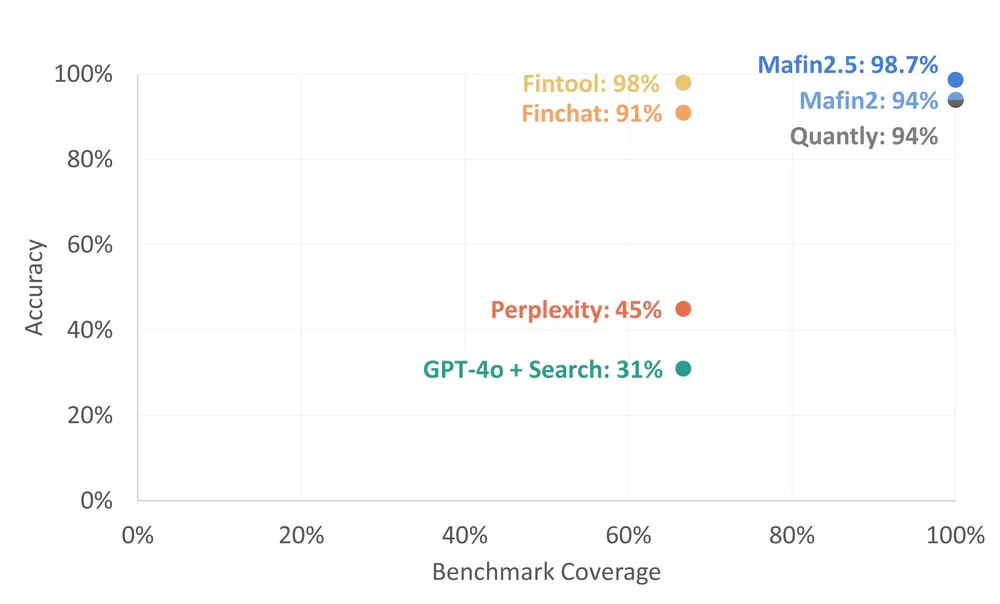
- Mafin 2.5 (PageIndex): 98.7%
- Quantly & Mafin 2: 94%
- Fintool: 98%
- Finchat: 91%
- Perplexity: 45%
- GPT-4o + Search: 31%
Khoảng cách giữa PageIndex (98.7%) và general vector RAG (~50%) là 48.7 percentage points - không phải cải tiến biên, mà là sự khác biệt về hạng mục. Tại sao? Ba lý do: theo được cross-reference, giữ nguyên cấu trúc bảng tài chính (header, footnote, cell relationship), và thực hiện multi-hop reasoning mà vector similarity không thể làm được.
Ai nên thử PageIndex ngay
PageIndex là công cụ chuyên biệt, không phải replacement toàn diện cho vector RAG. Dùng khi:
- Làm việc với tài liệu dài có cấu trúc: annual reports, hợp đồng pháp lý, regulatory filings, technical manuals, academic textbooks
- Accuracy là ưu tiên số một và có thể chấp nhận latency cao hơn
- Query yêu cầu multi-step reasoning hoặc theo cross-reference giữa các section
- Cần full audit trail - biết chính xác answer đến từ đâu (tài chính, pháp lý, y tế)
- Làm trong regulated industries (finance, legal, medical) nơi "gần đúng" không chấp nhận được
Không phù hợp khi cần sub-second response time ở volume cao, document ngắn hoặc unstructured, corpus lớn gồm nhiều document nhỏ (vector search thắng về cost và speed), hoặc consumer chatbot chấp nhận 90% accuracy.
Bắt đầu với PageIndex
Ba cách tùy nhu cầu:
Option 1 - Cloud (nhanh nhất): Truy cập chat.pageindex.ai, upload PDF, chat ngay. Không cần code. Free tier: 1,000 trang miễn phí + unlimited conversations.
Option 2 - Self-hosted (MIT License):
# Clone repo
git clone https://github.com/VectifyAI/PageIndex
# Cài dependencies
pip3 install --upgrade -r requirements.txt
# Tạo .env với LLM API key
OPENAI_API_KEY=your_key_here
# Chạy
python3 run_pageindex.py --pdf_path /path/to/document.pdfOption 3 - MCP integration: Kết nối trực tiếp vào Claude Desktop, Cursor, hoặc bất kỳ agent framework nào hỗ trợ MCP (Claude Agent SDK, Vercel AI SDK, OpenAI Agents SDK, LangChain). Chỉ cần API key từ PageIndex Dashboard - không cần OAuth.
Roadmap đang triển khai: PageIndex File System (scale lên hàng triệu documents thay vì 1 document) và Vision-based RAG (không cần OCR, làm việc trực tiếp trên page images).
Kết
PageIndex không "kill" vector RAG - vector database market vẫn sẽ đạt $10.6 tỷ vào 2032. Hai approach giải quyết hai bài toán khác nhau: vector search tối ưu cho semantic search rộng trên corpus lớn, PageIndex tối ưu cho truy xuất chính xác trong tài liệu dài có cấu trúc.
Điểm cốt lõi của PageIndex là minh chứng thực nghiệm cho một nguyên lý đơn giản: similarity không bằng relevance. Với tài liệu chuyên nghiệp đòi hỏi domain expertise và multi-step reasoning, hướng tiếp cận lý luận qua cấu trúc document vượt trội hơn tìm kiếm gần đúng bằng vector. 98.7% vs 50% là bằng chứng không thể tranh cãi.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ