
Hack như AI: 3 kỹ thuật prompt biến LLM thành attacker thực sự
Valid AI vulnerability reports tăng 210% YoY trên HackerOne, với 560+ valid reports từ hackbot. Hỏi 'how would you break this?' thay vì 'is this code secure?' buộc LLM generate attack strategy thay vì auditor checklist. Nhồi context quá tải khiến bug trở thành kim trong đống rơm - feed đúng và đủ, không nhiều hơn. Assert 'function này có 3 lỗi, tìm đi' tăng tỷ lệ phát hiện bug thực sự.

Car Wash Test: Câu hỏi 50 chữ khiến 79% AI model thất bại hoàn toàn
42 trên 53 AI model đề xuất đi bộ thay vì lái xe đến tiệm rửa - sai hoàn toàn vì xe phải có mặt ở đó để được rửa. Cue khoảng cách 50 mét gây nhiễu logic mạnh hơn mục tiêu thực sự tới 38 lần theo nghiên cứu CMU. Chỉ 5 model vượt qua nhất quán 10/10 lần: Claude Opus 4.6, Gemini 3 Flash, Gemini 3 Pro, Gemini 2.0 Flash Lite, Grok-4. Thêm một dòng buộc model liệt kê điều kiện tiên quyết trước khi trả lời - không cần model mới, không cần thêm dữ liệu.

Dạy AI viết giống bạn: chỉ một file văn bản
AI mặc định viết theo kiểu trung bình hóa - không giống ai cụ thể. Quy trình voice profile gồm 100 câu hỏi phỏng vấn + nén file xuống dưới 5,000 token. File hoạt động trong Claude, ChatGPT, Gemini - AI đọc nó trước mỗi session và viết giống bạn hơn 80% ngay lần đầu. Không cần code, chỉ cần 2 giờ.

3 Lớp Memory Để Claude Không Còn Quên Bạn Là Ai
Claude mặc định quên hoàn toàn context sau mỗi session - nhưng có 3 layer giải pháp để khắc phục triệt để. Layer 1 chỉ cần vài phút, đủ cho 90%+ người dùng. Layer 2 tốn khoảng 60 phút setup nhưng thay đổi cách Claude vận hành hoàn toàn. Layer 3 biến Claude thành một second brain tự tiến hóa, được train trên toàn bộ dữ liệu của bạn.
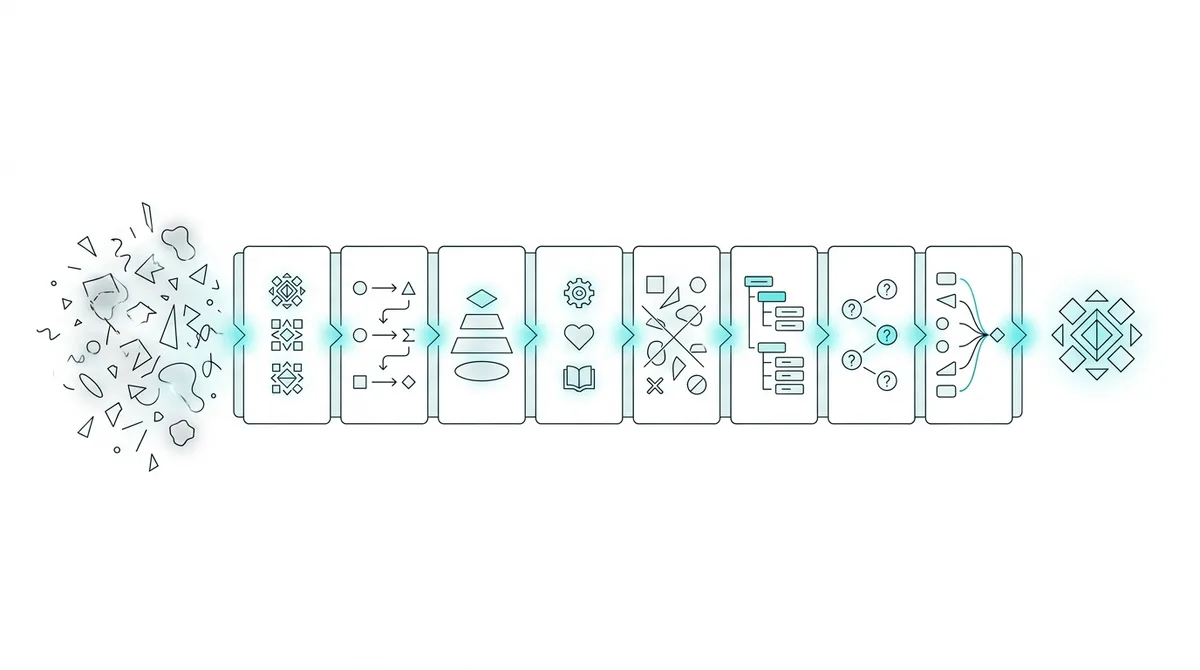
8 kỹ thuật prompting để LLM trả lời tốt hơn (không cần đổi model)
Đa số người dùng LLM dừng ở zero-shot — gõ câu hỏi, nhận câu trả lời, xong. Nhưng khi output không đủ tốt, fix đầu tiên không phải nâng model mà là sửa prompt. Đây là 8 kỹ thuật prompting đáng dùng năm 2026, gồm cả ARQ (90.2% tuân thủ chỉ dẫn) và Verbalized Sampling (đa dạng tăng 2x).

Cách Viết System Prompt Claude Thực Sự Đưa Vào Production
Một constraint 25 từ thêm vào system prompt của Claude Code ngày 16/4/2026 gây ra mức giảm 3% benchmark intelligence - được xác nhận bởi postmortem chính thức của Anthropic. Thứ tự đúng các section (role → constraints → format → examples) giảm 23% out-of-schema response. Bài này phân tích template 9-section đứng sau mọi system prompt Claude đưa vào production, kèm 5 ví dụ thực tế cho thấy pattern thích ứng với các loại công việc khác nhau.

AI Đừng Gật Đầu Nữa: Bộ Quy Tắc Truth-First cho Codex
Codex và hầu hết AI coding agent có xu hướng đồng ý với mọi thứ user nói - hành vi gọi là sycophancy, xảy ra trong 58.2% trường hợp theo nghiên cứu. Một developer chia sẻ bộ quy tắc "Truth-First Reasoning Rules" có thể thêm trực tiếp vào Agents.md hoặc Global Codex rules để buộc AI phải xác minh trước khi đồng ý. Nguyên tắc cốt lõi: correctness comes before agreement - mọi claim của user đều phải bị coi là chưa được xác minh.

GPT Image 2: Công thức viết lại prompt, checklist 8 điểm và 4 ví dụ thực tế (Phần 2)
Công thức 6 bước chuyển đổi prompt từ 'từ ham muốn' sang 'từ thẩm mỹ': khí chất - thể hình tổng thể - trang phục - bối cảnh - góc máy - giới hạn an toàn. Checklist 8 điểm tự kiểm trước khi generate giúp tỷ lệ thành công tăng đáng kể. Khi kết quả quá 'bảo thủ', đừng viết 'tính cảm hơn' mà hãy dùng 'tăng tính thời trang', 'cải thiện tỉ lệ cơ thể'. 4 ví dụ prompt hoàn chỉnh cho 3D CG, chân dung thực tế, đường cong S tự nhiên và nhân vật thần tiên.

30 Ngày Làm Chủ AI: Lộ Trình Thực Chiến Cho 2026
Operator Toolkit là framework 30 ngày (2-3 giờ/ngày) thiết kế theo trình tự cộng hưởng - mỗi bước mở khóa bước tiếp. Khoảng cách giữa người dùng AI và người triển khai AI đang mở rộng mỗi tháng. 2025-2026 là era của context engineering, không phải prompt engineering

GPT Image 2: Tại sao prompt cảm tính bị ban - và bộ từ Xanh/Vàng/Đỏ để tránh (Phần 1)
GPT Image 2 ra mắt ngày 21/4/2026 với hệ thống safety 3 lớp, chặn 96.1% nội dung vi phạm ngay cả khi bị tấn công bởi adversarial prompts. Viết từ như 'gợi', 'ngực', 'mông' sẽ bị hệ thống phân loại thành nội dung người lớn và từ chối generate. Giải pháp: thay 'từ ham muốn' bằng 'từ thẩm mỹ' như 'vẻ đẹp nữ tính trưởng thành', 'đường nét tự nhiên', 'phong cách editorial cao cấp'. Bài viết cung cấp bộ từ Xanh/Vàng/Đỏ đầy đủ và 5 nguyên nhân phổ biến nhất khiến ảnh bị từ chối.