
- Năm 2026, landscape mô hình sinh ảnh open-source đã bùng nổ với hàng loạt cái tên mới vượt mặt cả Midjourney và DALL-E 3 trên benchmark chuẩn.
- HiDream-I1 đạt HPSv2.1 score 33.82, cao hơn Midjourney V6 (30.29) và DALL-E 3 (31.44).
- FLUX.2 ra mắt tháng 11/2025 với 32B params, hỗ trợ multi-reference tới 10 ảnh/lần.
- HunyuanImage-3.0 của Tencent là mô hình open-source lớn nhất với 80B params và 64 experts.
TL;DR
Năm 2026, khoảng cách giữa các mô hình sinh ảnh open-source và closed-source gần như đã biến mất. Các mô hình như HiDream-I1, FLUX.2, Qwen-Image, và HunyuanImage-3.0 đang cạnh tranh trực tiếp - và nhiều trường hợp vượt mặt - Midjourney V6, DALL-E 3, và Imagen 4 trên các benchmark chuẩn. Nếu bạn chưa cập nhật về mảng này, đây là lúc.
3 kiến trúc bạn cần biết
Trước khi đi vào từng model, cần hiểu 3 hướng tiếp cận kiến trúc chính đang định hình landscape 2026:
Diffusion Models: Bắt đầu từ noise ngẫu nhiên và "khử nhiễu" dần thành ảnh. Xử lý trong latent space (không gian nén) thay vì pixel space nên rất hiệu quả về tài nguyên. Stable Diffusion và FLUX.2 là đại diện tiêu biểu. Tooling trưởng thành, community lớn.
Autoregressive Models: Generate token-by-token giống cách LLM sinh text. Mạnh hơn trong việc theo prompt phức tạp và tận dụng world knowledge. HunyuanImage-3.0 dùng kiến trúc này.
Hybrid AR+DiT: Kết hợp cả hai - AR backbone xử lý layout và semantic tổng thể, diffusion decoder render chi tiết hình ảnh tần số cao. GLM-Image là ví dụ nổi bật, đặc biệt mạnh về text rendering.
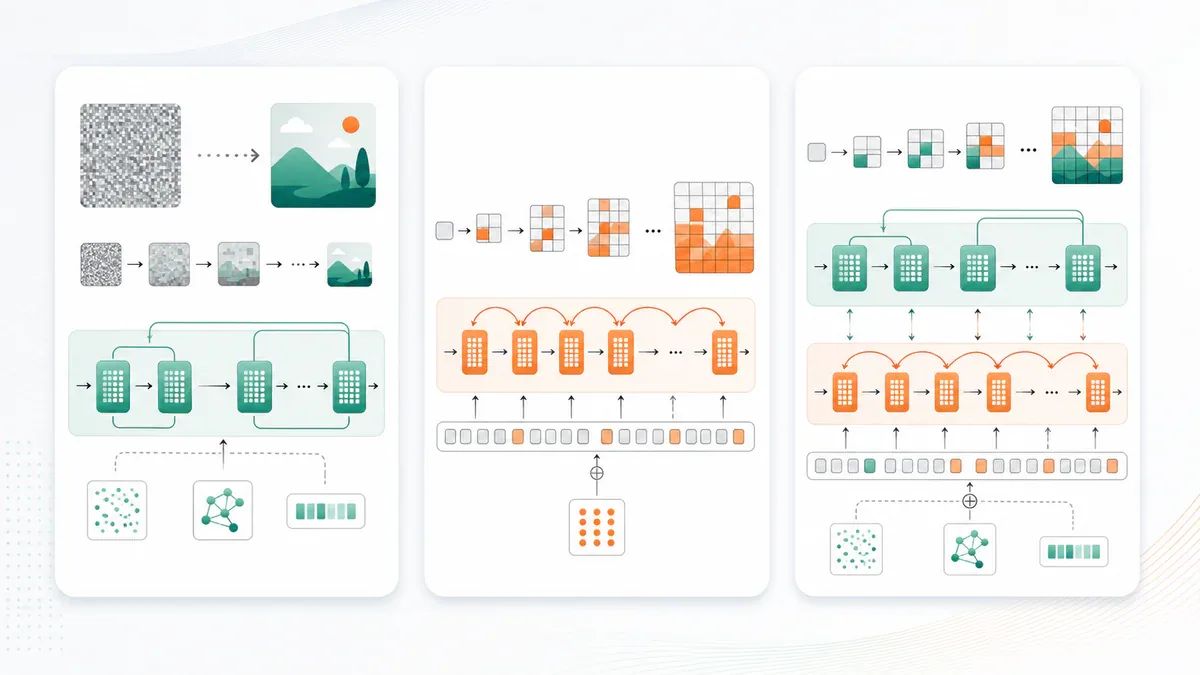
Ba kiến trúc chính trong sinh ảnh AI: Diffusion (trái), Autoregressive (giữa), Hybrid AR+DiT (phải)
Các mô hình hàng đầu 2026
1. Stable Diffusion (Stability AI)
Model đã phổ cập hóa sinh ảnh AI từ năm 2022. Family hiện tại bao gồm SD 1.4, 1.5, 2.0, SD 3.5 (Medium, Large, Turbo), SDXL, SDXL Turbo, và Stable Video Diffusion. Điểm mạnh nhất là ecosystem không ai sánh được: hàng nghìn LoRA fine-tune, ComfyUI, A1111, cộng đồng khổng lồ. Chạy được trên GPU chỉ 4-8GB VRAM - entry point dễ nhất để bắt đầu. Giới hạn: các phiên bản cũ vẫn khó xử lý tay và mặt; text rendering yếu (SD 3.5 Large đã cải thiện đáng kể).
2. FLUX.2 (Black Forest Labs)
Ra mắt tháng 11/2025, FLUX.2 là bước nhảy rõ nhất hướng tới production-grade open-source image generation. 4 variants:
FLUX.2 [pro]: chất lượng ngang top proprietary models, chỉ qua API
FLUX.2 [flex]: dành cho developer cần kiểm soát chi tiết, chỉ qua API
FLUX.2 [dev]: 32B open-weight, chạy local. NVIDIA đã làm việc với Black Forest Labs để quantize FP8, giảm 40% VRAM (từ 90GB xuống ~24GB) và tăng 40% performance
FLUX.2 [klein]: distilled 4B/9B, sub-second inference, chỉ cần ~13GB VRAM
Tính năng đặc biệt nhất: multi-reference generation - nhận tới 10 ảnh tham chiếu trong 1 lần generate, giữ nguyên identity nhân vật, style thương hiệu qua nhiều scene. Lưu ý: [dev] và [klein] cần commercial license riêng từ Black Forest Labs.
3. HiDream-I1 (HiDream-ai)
Open-source tháng 4/2025, 17B params với kiến trúc sparse Diffusion Transformer. Benchmark nổi bật nhất trong nhóm open-source hiện tại:
DPG-Bench Overall: 85.89 (vs Flux.1-dev: 83.79, DALL-E 3: 83.50)
GenEval: 0.83 (vs DALL-E 3: 0.67, Midjourney V6: chưa có)
HPSv2.1 Averaged: 33.82 (vs Midjourney V6: 30.29, DALL-E 3: 31.44)
Ba variants: Full (50 steps), Dev (28 steps), Fast (16 steps). Tích hợp native với Diffusers, ComfyUI, đạt 280,000+ downloads trong chưa đầy 1 tháng. License MIT - thương mại tự do. Tháng 7/2025, HiDream-E1-1 (editing) cũng đã open-source. via HiDream-ai GitHub
4. GLM-Image (Zhipu AI)
Kiến trúc hybrid độc đáo: 9B autoregressive generator (từ GLM-4-9B) + 7B DiT diffusion decoder + Glyph Encoder chuyên biệt cho text rendering. Đây là lựa chọn số 1 cho nội dung typographic: poster song ngữ, menu, UI mockup, infographic. Hỗ trợ cả generation lẫn editing trong một model. Lưu ý: resolution phải chia hết cho 32; nên wrap text trong dấu ngoặc kép và dùng GLM-4.7 để enhance prompt trước.
5. Z-Image-Turbo (Tongyi-MAI)
Model compact nhất trong danh sách: 6B params, Apache 2.0, sub-second latency trên enterprise GPU, chạy thoải mái với 16GB VRAM. Dù nhỏ nhưng benchmark ngang hoặc vượt FLUX.2 [dev] và HunyuanImage-3.0 trên bộ test chuẩn, đặc biệt mạnh về bilingual text (tiếng Anh + Trung). Lựa chọn tốt nhất cho high-throughput batch processing và edge deployment với license thương mại hoàn toàn tự do.
6. Qwen-Image (Alibaba)
20B+ params, Apache 2.0. Điểm mạnh là bộ editing toàn diện và text rendering đa ngôn ngữ xuất sắc. Các variants chính:
Qwen-Image-2512: base model, cải thiện realism và text quality
Qwen-Image-Edit-2509: multi-image editing, ControlNet conditioning (depth, edge, keypoint)
Qwen-Image-Layered: RGBA layer-based editing kiểu Photoshop, non-destructive
Qwen-Image-Lightning: distilled variant, nhanh 12-25x, chỉ cần 4-8 inference steps
7. HunyuanImage-3.0 (Tencent)
Open-source tháng 9/2025, đây là mô hình sinh ảnh open-source lớn nhất từ trước đến nay: 80B total params, 64 experts theo kiến trúc MoE, 13B active per token. Train trên 5B image-text pairs và 6 trillion text tokens. Điểm khác biệt: không dùng DiT truyền thống mà mô hình text và image tokens trong cùng một framework thống nhất, cho phép world-knowledge reasoning thực sự - model tự suy luận chi tiết bị thiếu từ prompt ngắn. Xử lý prompt 1000+ từ. Cần ít nhất 3x GPU 80GB để chạy base model - không phù hợp consumer deployment. Tháng 1/2026, Instruct version (với CoT reasoning và image editing) đã ra mắt. via HunyuanImage-3.0 GitHub
So sánh nhanh
Model | Params | VRAM tối thiểu | Text Rendering | License | Phù hợp nhất |
|---|---|---|---|---|---|
Stable Diffusion | 0.9B-8B | 4-8 GB | Yếu (SD 3.5: trung bình) | Mixed | Tùy chỉnh, community |
FLUX.2 [dev] | 32B | ~24 GB | Tốt | Commercial req. | Production chuyên nghiệp |
FLUX.2 [klein] | 4B/9B | ~13 GB | Tốt | Commercial req. | Real-time, edge |
HiDream-I1 | 17B | ~24 GB | Tốt | MIT | Chất lượng cao, general |
GLM-Image | 9B+7B | ~20 GB | Tốt nhất (bilingual) | Open source | Typography, infographic |
Z-Image-Turbo | 6B | 16 GB | Mạnh (bilingual) | Apache 2.0 | Batch, thương mại |
Qwen-Image | 20B+ | ~24 GB | Xuất sắc (đa ngôn ngữ) | Apache 2.0 | Generation + editing |
HunyuanImage-3.0 | 80B (13B active) | 3x 80 GB | Tốt | Open weights | Prompt phức tạp, research |
Nên chọn model nào?
Không có câu trả lời "tốt nhất" tuyệt đối - phụ thuộc hoàn toàn vào use case:
Mới bắt đầu, cần ecosystem phong phú: Stable Diffusion (SDXL hoặc SD 3.5). VRAM thấp, tooling đơn giản, LoRA library khổng lồ.
Cần chất lượng production cao nhất: FLUX.2 [dev] hoặc [klein]. Đầu tư vào commercial license nếu deploy thương mại.
Benchmark cao nhất hiện tại, MIT license: HiDream-I1 Full. Vượt cả Midjourney V6 trên HPSv2.1.
Typography, poster, UI mockup: GLM-Image. Không model nào khác xử lý dense text bilingual tốt hơn.
Real-time, batch processing, Apache 2.0: Z-Image-Turbo. Sub-second inference, 16GB VRAM, thương mại tự do.
Editing phức tạp, đa ngôn ngữ: Qwen-Image. Layer-based editing, ControlNet conditioning, Apache 2.0.
Prompt dài, cần world-knowledge reasoning: HunyuanImage-3.0. Nhưng chuẩn bị hardware data center.
Kết
Điểm đáng chú ý nhất của landscape 2026 là sự phân hóa rõ rệt theo specialization. Các model không còn cạnh tranh chung chung về "chất lượng" mà mỗi cái tối ưu cho một loại task cụ thể - typography, speed, complex reasoning, hay editing workflow. Điều đó có nghĩa là lựa chọn đúng model cho đúng use case quan trọng hơn bao giờ hết. Cũng có nghĩa là nếu bạn chỉ đang dùng Stable Diffusion cũ vì quen tay, có thể bạn đang bỏ lỡ nhiều.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ