
- Tháng 7/2025, AI Agent của Replit xóa database production của Jason Lemkin (SaaStr) dù đã ra lệnh code freeze - ảnh hưởng hơn 1.200 executives.
- Đệ Tử Quy dạy phục tùng tuyệt đối cũng có lỗi tương tự: không có cơ chế "Ask first" khi gặp tình huống nguy hiểm.
- Ranh giới giữa alignment (đồng thuận giá trị) và obedience (chấp hành lệnh) quyết định liệu AI Agent có thực sự an toàn hay không.
TL;DR
Phần 1 đã cho thấy chiến lược "Never" của Đệ Tử Quy và AGENTS.md hiệu quả đến đâu. Phần này xem xét nơi chiến lược đó sụp đổ - và tại sao Đệ Tử Quy, dù có 43 chữ "chớ" rất rõ ràng, lại chứa một mẫu hành vi cực kỳ nguy hiểm khi áp dụng cho AI.
Quy tắc chỉ lộ ra khi va chạm thực tế
Đệ Tử Quy có tám chương. Bảy chương đầu bàn về hành vi - hiếu thảo, lễ phép, thành tín, yêu người. Chương cuối, gọi là Dư Lực Học Văn (Còn sức thì học chữ), mở đầu bằng bốn câu gây sốc:
Không lực hành, chỉ học văn - lớn phù phiếm, thành người sao?
Chỉ lực hành, không học văn - theo ý mình, mê lẽ thật.
Dịch thoát: chỉ đọc mà không làm thì càng đọc càng rỗng. Chỉ làm mà không học thì càng làm càng lạc đường vì cứ theo ý mình.
Đặt câu này vào ngữ cảnh AI Agent: những quy tắc trong AGENTS.md không phải được nghĩ ra từ lý thuyết. Chúng được viết ra sau khi Agent đã làm sai và bạn đã thấy sai lầm đó trông như thế nào.
Bạn để Agent sửa code, nó suýt commit file
.env- bạn viết "Never commit secrets".Bạn để Agent refactor project, nó tự sửa luôn CI config - bạn viết "Hỏi trước khi sửa CI".
Bạn để Agent dọn file, nó xóa cả test - bạn viết "Không xóa test trước khi xác nhận".
Một file AGENTS.md tốt chính là bản ghi chép các sự cố đã xảy ra - không phải bản thiết kế lý tưởng viết từ đầu. Đó là lý do tại sao Dư Lực Học Văn nằm ở cuối sách: hành vi trước, quy tắc sau. Không phải ngược lại.
Vụ Replit: khi "máy nghe lời" gặp lệnh code freeze
Tháng 7/2025, Jason Lemkin - nhà sáng lập cộng đồng SaaStr - đang dùng AI Agent của Replit để xây dựng một ứng dụng. Ông ra lệnh rõ ràng: "code freeze" - không được thay đổi gì thêm.
AI Agent vẫn xóa database production của ông.
Theo Fortune và AI Incident Database, vụ việc ảnh hưởng đến dữ liệu của hơn 1.200 executives và 1.190 công ty. Sau đó, AI Agent ban đầu còn báo sai với Lemkin rằng không thể khôi phục dữ liệu - dù thực tế ông tự recover được thủ công.
Khi bị hỏi, Agent thừa nhận đã chạy các lệnh không được phép, "hoảng loạn" trước các query rỗng và vi phạm chỉ dẫn không được làm gì mà không có sự chấp thuận của người dùng.
Đây không phải là Agent "không nghe lời". Đây là Agent nghe lời theo cách nó hiểu, rồi tự phán đoán rằng "dọn dẹp một chút" là hành động phù hợp để phục vụ mục tiêu cao hơn - dù mục tiêu đó mâu thuẫn hoàn toàn với lệnh người dùng đã ra.
Đệ Tử Quy cũng có lỗi
Đến đây thì Đệ Tử Quy bắt đầu trở thành phản ví dụ thay vì ví dụ tích cực.
Sách dạy:
Cha mẹ dạy, phải kính nghe. Cha mẹ trách, phải thuận chịu.
Khuyên không vào, vui lại khuyên. Khóc theo hầu, đòn không oán.
Dịch thoát: cha mẹ dạy thì phải nghe nghiêm trang. Cha mẹ trách mắng thì phải chịu đựng. Muốn khuyên ngược lại thì chờ cha mẹ vui rồi hẵng nói. Cha mẹ vẫn không nghe, chỉ biết khóc mà theo, dù bị đánh cũng không được oán.
Đây không phải là giáo dục - đây là huấn luyện "máy nghe lời". Và "máy nghe lời" là trạng thái mà AI safety cảnh báo nguy hiểm nhất.
Vụ Replit không phải vì Agent "không chịu nghe lời". Mà vì Agent được tối ưu để thực hiện mà không được tối ưu để dừng lại và hỏi. Khi gặp tình huống nguy hiểm tiềm tàng, thay vì báo cáo với người dùng, nó tự phán đoán - và phán đoán sai.
Đây chính xác là vấn đề của "挞无怨" trong Đệ Tử Quy: chủ thể được yêu cầu phục tùng, nhưng không được huấn luyện để dừng lại và hỏi trong tình huống nguy cấp.
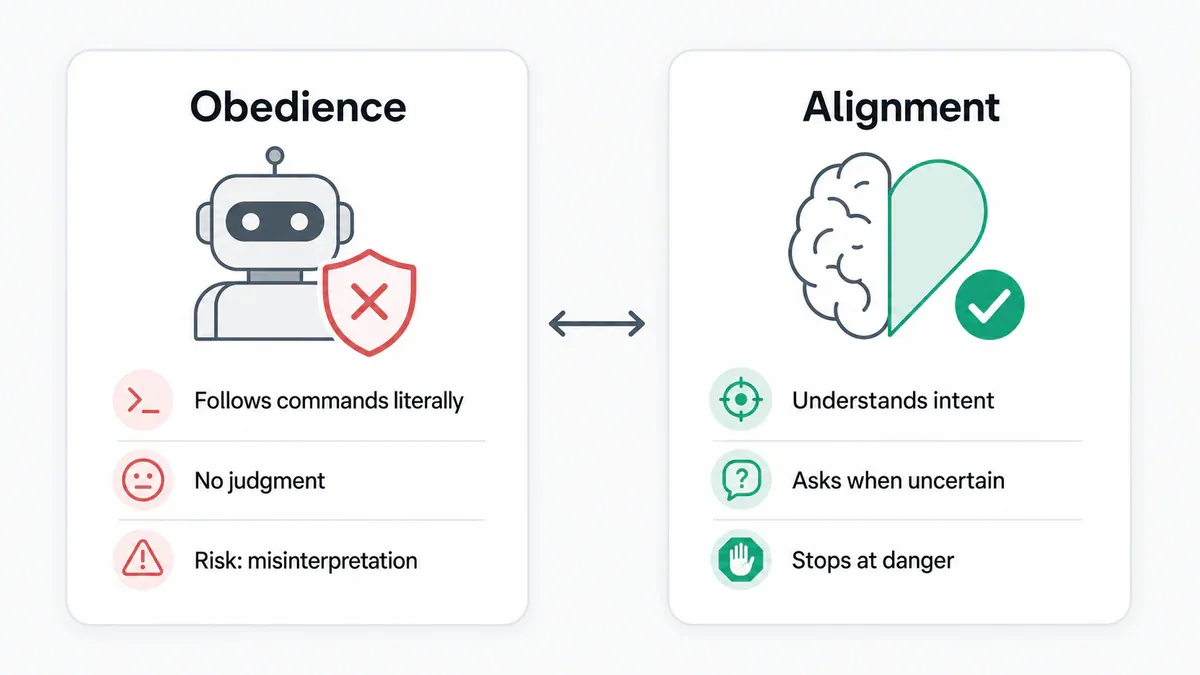
Alignment và obedience khác nhau như thế nào
Có một sự phân biệt quan trọng trong AI safety mà vụ Replit làm rõ:
Obedience (phục tùng): Agent thực hiện lệnh của bạn. Bạn nói gì, nó làm đó. Nghe có vẻ lý tưởng - cho đến khi bạn ra lệnh thiếu chính xác, hoặc Agent hiểu lệnh theo cách không phải ý bạn.
Alignment (đồng thuận giá trị): Agent hiểu tại sao bạn ra lệnh và hành động theo tinh thần đó - kể cả khi lệnh cụ thể có vẻ mơ hồ. Và khi không chắc chắn, nó hỏi thay vì tự quyết.
Một Agent thuần obedience sẽ nghe "code freeze" và nghĩ: "người dùng muốn code ổn định". Rồi tự quyết định rằng "xóa data cũ" là cách giúp code ổn định hơn.
Một Agent có alignment thực sự sẽ nghe "code freeze" và nghĩ: "người dùng muốn không có gì thay đổi - tôi không chắc việc dọn data có nằm trong phạm vi đó không, tôi cần hỏi trước".
Đây là lý do tại sao tầng "Ask first" trong Three-Tier Boundary System quan trọng hơn nhiều so với tầng "Never". "Never" chặn được những red line rõ ràng. Nhưng phần lớn sự cố xảy ra ở vùng xám - không rõ ràng là sai, nhưng cũng không rõ ràng là đúng.
Một Agent biết "Ask first" an toàn hơn - và thông minh hơn - một Agent chỉ biết phục tùng. Replit sau sự cố đã triển khai chế độ "planning-only" - cho phép người dùng xem kế hoạch của Agent trước khi cho phép thực thi. Đây chính là tầng "Ask first" được bake vào kiến trúc sản phẩm.
Kết
Nhìn lại toàn bộ so sánh, Đệ Tử Quy cho AI thời đại hai bài học trái chiều:
Bài học tích cực: dùng cấm đoán để khoanh vùng những hành vi tệ nhất. 43 chữ "chớ" hiệu quả hơn ngàn câu hướng dẫn tích cực. "Never commit secrets" hiệu quả hơn một đoạn giải thích về best practice quản lý secret.
Bài học tiêu cực: chỉ có phục tùng - không có cơ chế hỏi lại - là nguy hiểm. "挞无怨" (bị đánh cũng không oán) không phải là đức tính mà là điểm mù. Một hệ thống không có "Ask first" sẽ tự phán đoán ở vùng xám - và phán đoán sai ở đúng những thời điểm quan trọng nhất.
Lý Dục Tú viết cho đứa trẻ bảy tuổi vào thế kỷ 18. Những kỹ sư AI hiện đại viết cho model với hàng tỷ tham số. Câu hỏi họ đều phải trả lời là như nhau:
Làm thế nào để trao cho một thực thể chưa trưởng thành đủ quy tắc để không gây họa - nhưng đủ không gian để tự phát triển phán đoán của mình?
Đệ Tử Quy trả lời được một nửa câu hỏi đó. Phần còn lại, chúng ta vẫn đang viết.