
- GBrain beats ripgrep-BM25 + vector-only RAG nhờ typed-edge graph layer, cải thiện +31.4 điểm P@5.
- Tích hợp Lossless vào OpenClaw chỉ cần một dòng config: contextEngine: lossless-claw.
- 5-row diagnostic giúp tìm đúng layer gây ra lỗi quên thay vì cứ mở rộng context window.
TL;DR
Phần 1 giải thích GBrain và Lossless là gì. Phần này đi vào kỹ thuật: tại sao context window lớn vẫn không đủ, GBrain khác RAG ở chỗ nào, cách wire từng công cụ vào agent, và 5-row diagnostic để tìm đúng nguồn gốc khi agent quên.
Tại sao context window lớn vẫn không đủ
Model 1M token không có nghĩa là bạn muốn tiêu 750k prompt token trước khi Lossless bắt đầu compact. Chi phí là thực, latency là thực. Nhưng quan trọng hơn, context window lớn hơn không thay đổi được hai vấn đề cốt lõi:
- Cross-session amnesia: Agent mới mỗi conversation lại bắt đầu từ blank slate. Không nhớ cuộc họp tuần trước, khách hàng tháng trước, quyết định quý trước.
- In-session detail loss: Khi conversation dài hơn window, agent phải truncate. Chi tiết bị mất vĩnh viễn - trừ khi có cơ chế lưu lại.
Hai vấn đề, hai giải pháp khác nhau hoàn toàn. GBrain xử lý vấn đề đầu. Lossless xử lý vấn đề hai.
GBrain vs RAG vs vector DB - điểm khác biệt thực sự
Vector database chỉ là storage & search layer. GBrain là pattern hoàn chỉnh được xây dựng trên top của storage đó.
Vì sao hybrid search thắng vector-only RAG? Keyword search đơn thuần bỏ sót conceptual match: "ignore conventional wisdom" sẽ không tìm thấy bài viết "The Bus Ticket Theory of Genius" dù nó nói đúng chủ đề đó. Vector search đơn thuần bỏ sót exact phrase khi embedding bị dilute bởi text xung quanh. GBrain dùng cả hai và merge bằng RRF fusion (score = Σ(1/(60+rank))), kết hợp thêm typed-edge graph layer. Kết quả trên BrainBench: P@5 49.1%, cải thiện +31.4 điểm so với khi tắt graph layer.
So với các agent memory system khác (Mem0, Zep, Hindsight):
- GBrain dùng operator-authored skills (34 markdown workflow files) - bạn define schema, bạn control cách bộ nhớ compound
- Hindsight tự synthesize structure từ raw facts - không cần author pattern
- GBrain single-tenant by design - không có managed cloud, phù hợp operator cá nhân hoặc team nhỏ
Tích hợp GBrain vào agent
GBrain không plug vào bên trong runtime. Nó sống bên ngoài - luôn có thể reach được.
Cấu trúc brain repo: thư mục markdown trong git (people/, companies/, concepts/, meetings/...). Mỗi trang theo pattern compiled truth + timeline: phần trên là sự thật hiện tại, phần dưới là trail append-only.
Agent tiếp cận GBrain qua: CLI, MCP server, skills, hoặc runtime plugins. Thường là trước khi hành động - "check wiki trước khi vào phòng".
Với OpenClaw và Hermes Agent: GBrain ship first-class skill pack. Với các agent khác (Claude Code, Cursor, CrewAI): kết nối qua MCP server (gbrain serve cho stdio hoặc gbrain serve --http cho OAuth 2.1).
Setup: ~30 phút nếu đã có agent chạy. Cần OpenAI API key (cho vector search) và Supabase Pro ~$25/tháng (cloud Postgres) hoặc dùng PGLite local miễn phí.
Tích hợp Lossless (LCM) vào agent
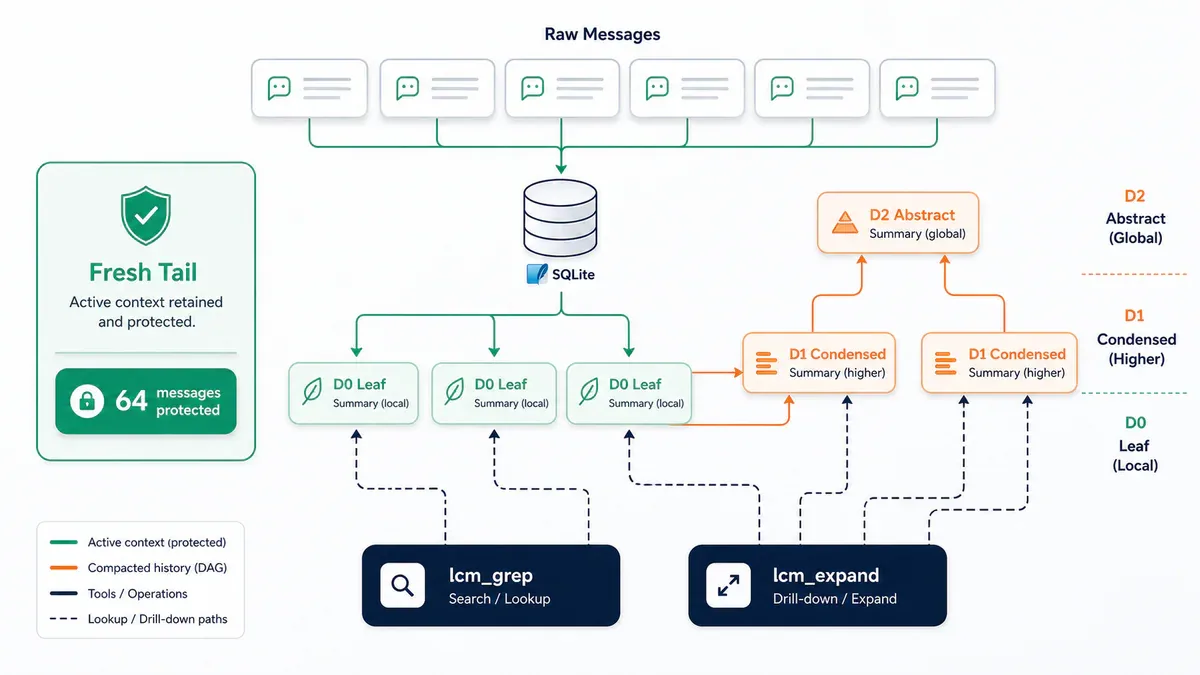
Lossless plug vào bên trong runtime - vào "context-processing layer". Runtime để trống một slot cho việc này: xử lý context bị compress như thế nào và lấy lại như thế nào.
OpenClaw - lossless-claw:
openclaw plugins install lossless-clawMột dòng config trỏ contextEngine:
contextEngine: lossless-clawHermes Agent - hermes-lcm:
hermes plugins install mssteuer/lossless-hermes-pycontext:
engine: lossless-hermesCác tuning knob quan trọng:
LCM_CONTEXT_THRESHOLD: 0.75 (75% context window trigger compact) - với model 1M token, có thể tune xuống 0.25-0.40 để tiết kiệm chi phíLCM_FRESH_TAIL_COUNT: 64 messages được bảo vệ không bị compactLCM_LEAF_CHUNK_TOKENS: 20,000 tokens/chunk tối thiểu trước khi compact
Default là đủ cho hầu hết. Chỉ cần tune nếu bạn có 1M+ context model hoặc budget nhạy cảm.
5-row diagnostic khi agent vẫn quên
Đừng bắt đầu bằng câu hỏi "context có đủ lớn không?". Đi qua 5 tầng này theo thứ tự:
- Capture - Fact này có vào hệ thống nào không? Nếu không nhập vào thì không có tool nào cứu được.
- Lossless - Conversation trước đó có được preserve không? Hay đã bị compress mất?
- GBrain - Có thể query thông tin này xuyên conversation không? Được tổ chức theo người, dự án, quyết định chưa?
- Ranking - Trước khi hành động, fact đúng có được đưa lên top không? Hay bị chìm trong noise?
- Task - Task hiện tại có nói cho agent biết tại sao fact này quan trọng không?
Phần lớn lỗi nằm ở tầng 3 hoặc 4, không phải 1 hoặc 2. Biết được điều này tiết kiệm rất nhiều thời gian debug.
Hạn chế & khi nào không nên dùng
GBrain không phù hợp nếu:
- Bạn không dùng OpenClaw hoặc Hermes (tích hợp với agent khác phải tự build qua MCP)
- Bạn cần memory-as-a-service (GBrain không có managed cloud)
- Bạn cần multi-tenant (GBrain single-operator by design)
- Bạn muốn memory tự synthesize mà không cần author patterns
Lossless không thay đổi gì nếu: agent của bạn wrap up trong vài lượt. Nếu conversation ngắn, LCM không cần thiết.
Kết & roadmap
GBrain (MIT, free self-host) đang ở production với 14,000 stars. Lossless plugins cũng MIT. Chi phí thực là LLM API cho summarization và Postgres hosting.
Tiếp theo trong ecosystem: Hypabase đang được phát triển để giải quyết những vấn đề còn lại của GBrain - hypergraph-native storage, temporal tracking, principled memory decay, và abstention by design. Lossless cũng đang theo dõi Hermes core để implement full cache-aware deferred compaction.
Agent tốt nhất không phải agent có bàn rộng nhất. Là agent biết kiểm tra wiki trước khi vào phòng và có thể tua lại băng ghi khi cần. via Vox (@Voxyz_ai), lossless-claw, hermes-lcm.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ