
- Multi-agent RAG bị silent failure khoảng 30% thời gian theo dữ liệu nội bộ Q4/2025 trên 1.500 multi-hop queries.
- Khoảng 60% hallucination đến từ unhandled execution errors, không phải LLM suy luận sai.
- Kiến trúc hierarchical với reflective retry giảm hallucination rate từ 28.5% xuống 7.1%.
- Context Engineering - treat context như compiled view thay vì giant prompt - là hướng giải quyết đúng đắn.
TL;DR
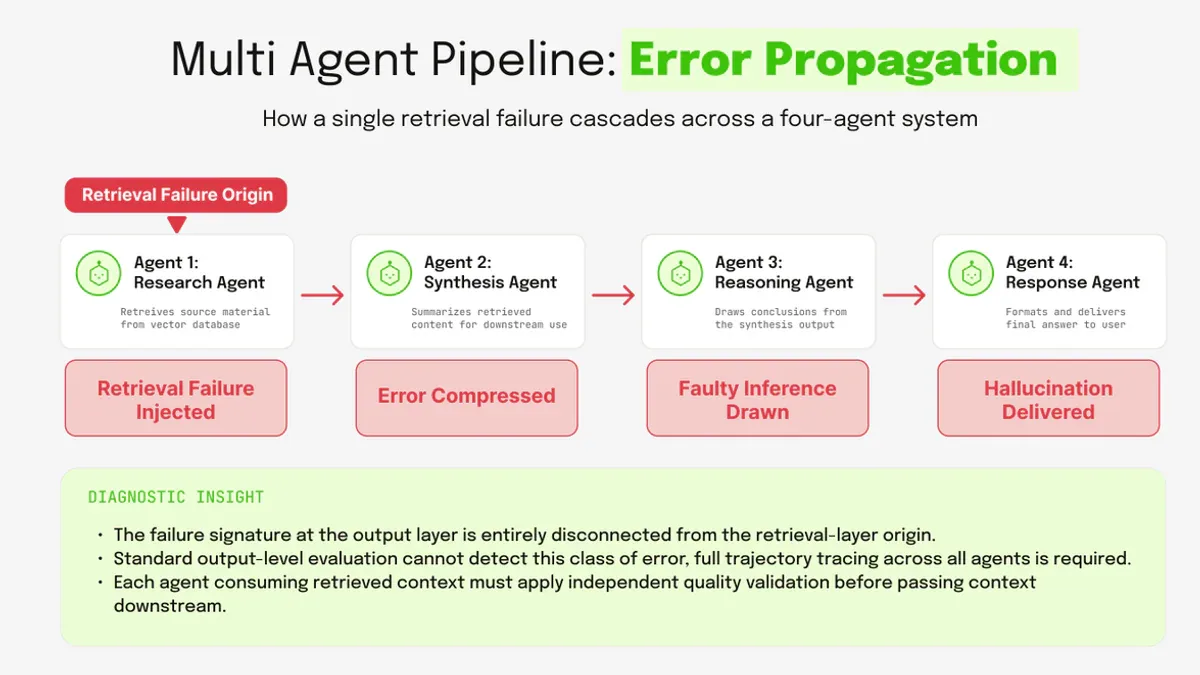
Multi-agent RAG systems đang được triển khai rộng rãi. Nhưng có một lỗ hổng thiết kế ngầm đang phá hoại độ chính xác: khi bước retrieval đầu tiên sai, lỗi đó không dừng lại ở agent đó - nó lan ra, bị khuếch đại, và trở thành "sự thật" với mọi agent tiếp theo. Kết quả cuối cùng là câu trả lời tự tin nhưng sai hoàn toàn, với nguồn gốc lỗi gần như không thể truy ngược.
Theo dữ liệu nội bộ Q4/2025 trên ~1.500 multi-hop queries, khoảng 30% câu trả lời của standard RAG bị silent failure - trả lời nghe có vẻ authoritative nhưng thiếu hơn 20% data quan trọng. Và ~60% hallucination không đến từ LLM suy luận sai, mà từ unhandled execution errors được pass tiếp xuống như thể chúng là dữ liệu hợp lệ.
Trò chơi điện thoại của AI agents
Hãy hình dung một pipeline 4 agent: Research Agent thu thập nguồn, Synthesis Agent tóm tắt, Reasoning Agent kết luận, Response Agent định dạng câu trả lời cuối. Mỗi agent chuyên biệt, nghe có vẻ chắc chắn.
Nhưng nếu Research Agent vô tình retrieves một document hơi lệch chủ đề - chẳng hạn một bài về bệnh có triệu chứng tương tự nhưng không cùng loại - thì sao? Synthesis Agent nhìn vào context hỗn hợp đó và cố dung hòa cả hai, tạo ra một summary blend hai bệnh lại với nhau. Reasoning Agent nhận summary này và tin đó là sự thật, rồi đưa ra conclusions. Response Agent trình bày tất cả một cách tự tin.
Hệ thống vừa thất bại theo kiểu progressive và confident - mỗi bước khuếch đại lỗi của bước trước. Điều đáng sợ hơn là nguồn gốc lỗi hoàn toàn bị ngắt kết nối với output layer. Bạn không thể chỉ nhìn câu trả lời cuối để phát hiện vấn đề. Để trace được phải xem toàn bộ agent trajectory.
Đây là pattern mà Weaviate gọi là Inter-Agent Miscommunication: retrieval failure ở upstream agent lan và khuếch đại qua tất cả downstream agents, tạo ra compounding degradation vô hình ở output layer.
Ba kẻ phá hoại trong context window
Có 3 failure mode cụ thể xảy ra khi context trong multi-agent systems phình to mất kiểm soát:
Context Distortion (Poisoning): Thông tin sai hoặc hallucinated lọt vào context. Vì các agent tiếp theo reuse và build on đó, lỗi compound theo thời gian - mỗi agent đều treat error như sự thật.
Context Distraction: Agent bị chôn vùi trong quá nhiều lịch sử - tool outputs, summaries, retrieval results cũ - và bắt đầu rely vào việc lặp lại behavior cũ thay vì reasoning mới về query hiện tại.
Context Confusion: Quá nhiều irrelevant tools hoặc documents lấp đầy context window, khiến model dùng sai tool hoặc đi theo instructions không phù hợp.
Multi-agent systems khuếch đại tất cả những điều này. Nếu root agent pass toàn bộ history cho sub-agent, và sub-agent lại làm vậy với agent kế tiếp, bạn kích hoạt một "context explosion" - token count tăng vọt, mỗi sub-agent bị confused bởi lịch sử conversation không liên quan của agent trước.
Vì sao prompt tốt hơn không giúp được
Đây là điều nhiều người hiểu nhầm: đây không phải vấn đề của prompt engineering hay context window size. Đây là vấn đề thiết kế kiến trúc cơ bản của multi-agent systems.
Khi agents chain với nhau, context của họ trở thành trò chơi điện thoại - mỗi bước có thể introduce lỗi, và lỗi compound theo cấp số nhân. Throwing more tokens at the problem không giải quyết được hình dạng của vấn đề.
Benchmark từ Protocol-H (kiến trúc hierarchical supervisor-worker với autonomous error recovery) cho thấy mức độ chênh lệch rõ ràng:
Approach | Accuracy (Multi-hop) | Hallucination Rate | Latency p95 |
|---|---|---|---|
Standard RAG | 45.2% | 28.5% | 0.8s |
Flat Agent | 62.8% | 18.2% | 1.4s |
Hierarchical (Protocol-H) | 84.5% | 7.1% | 2.1s |
Hierarchical approach với reflective retry: 89% error recovery rate trên error-prone queries, so với chỉ 12% với flat agents. Đánh đổi là latency cao hơn (2.1s vs 0.8s) - nhưng với enterprise analytics, độ chính xác thường quan trọng hơn tốc độ vài giây.
Context Engineering - hướng đi đúng
Ngành đang dịch chuyển sang một discipline mới: Context Engineering - treat context như một first-class system với architecture, lifecycle, và constraints riêng, thay vì chỉ append mọi thứ vào một giant prompt.
Ba nguyên tắc cốt lõi từ Google ADK (Agent Development Kit):
Tách storage khỏi presentation: Full session log lưu riêng; working context là một "compiled view" được tạo ra cho mỗi LLM call - ephemeral và configurable.
Explicit transformations: Context được build qua ordered processor pipelines, không phải ad-hoc string concatenation.
Scope by default: Mỗi agent chỉ nhận context tối thiểu cần thiết. Muốn thêm thì phải explicit request qua tools.
Ở tầng retrieval: hybrid search (dense vector + BM25 keyword matching), cross-encoder re-ranking, và quan trọng nhất - relevance thresholding: chỉ pass document vào context window nếu similarity score vượt threshold tối thiểu. Một hệ thống nói "tôi không tìm thấy gì liên quan" đáng tin hơn rất nhiều so với hệ thống silently generate từ irrelevant material.
Trong multi-agent architecture, rule quan trọng nhất: gate context tại mỗi retrieval point. Mỗi agent cần apply independent relevance validation trước khi incorporate context từ upstream agent vào reasoning của mình.
Ai cần quan tâm ngay
AI engineers đang build production multi-agent systems với LangGraph, CrewAI, LlamaIndex hay Google ADK
Compliance & audit teams trong regulated industries (tài chính, y tế, pháp lý) - EU AI Act Article 12 yêu cầu full decision traceability từ AI systems
Enterprise analysts đang rely vào AI-generated insights cho high-stakes business decisions - 30% silent failure rate là con số đủ để lo lắng
Tiếp theo
Frontier tiếp theo bao gồm adaptive routing bằng lightweight RL để tối ưu supervisor routing policy, human-readable explainability cho compliance audits (critical nhất cho enterprise adoption theo Weaviate), và semantic caching để reduce redundant embeddings.
MCP (Model Context Protocol của Anthropic) - được ví như "USB-C cho AI" - đang standardize cách AI applications kết nối với external data sources, biến M x N integration problem thành M + N.
Retrieval quality và validation layers vẫn là foundation quan trọng nhất. AI agents cần access đúng thông tin, đúng thời điểm - và validation phải xảy ra tại mỗi bước, không chỉ ở output cuối.
Via: Weaviate - Retrieval Quality RAG Overview, Weaviate - Context Engineering, InfoQ - Hierarchical Agentic RAG Systems, Google Developers Blog - ADK.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ