
Giảm 87% Chi Phí Token AI Agent trong 7 Ngày - Từ $4,800 Xuống $620/Tháng
AI agent tiêu tốn token 10-100x nhiều hơn chatbot vì re-send toàn bộ context mỗi bước - 70% trong số đó là waste. Playbook 7 ngày giúp giảm bill từ $4,800 xuống $620/tháng (87%) mà không giảm chất lượng output. Prompt caching Anthropic giảm 90% chi phí token cached, chỉ cần 1 cache hit để hoà vốn. Model routing Haiku/Sonnet/Opus theo task complexity - một team finance tiết kiệm $365,000/năm nhờ thay đổi này.

Dùng Claude đúng cách - Phần 2: 8 kỹ thuật nâng cao và tối ưu chi phí
8 kỹ thuật nâng cao sau khi đã thiết lập workspace: clone giọng văn bằng 3-5 mẫu text, dùng Claude như đối thủ tranh luận để phá vỡ giả định, bật Extended Thinking cho bài toán phức tạp, và giảm 40-60% token usage chỉ bằng một instruction.

Đang đốt 80% context window? 10 tool giúp bạn cắt hóa đơn Claude Code xuống còn một phần nhỏ
Code Review Graph giảm token tới 49x trên monorepo lớn, Token Savior đạt điểm 100% benchmark với -77% active tokens/task. Claude Token Optimizer kéo 11,000 tokens startup xuống còn 1,300 tokens. Claude Token Efficient giảm 63% output chỉ bằng một file CLAUDE.md.

Router architecture và 30-day plan để cắt 80% hóa đơn AI coding - kinh nghiệm thực tế
Kimi K2.6 đạt SWE-Bench Pro 58.6% - ngang GPT-5.5 - với giá chỉ $0.60/MTok input (so với Sonnet 4.6 $3/MTok). Vòng lặp agentic 30 bước trên Opus tốn $18-24/lần; cùng workflow với Kimi K2.6 chỉ $1.40/lần. Bài này có config YAML copy-paste và 30-day plan cụ thể.

Tại sao hóa đơn AI coding của bạn đang bùng nổ - và 5 cái bẫy token bạn đang mắc phải
Vibe coder đang ship hàng ngày có thể đốt $2,000-5,000/tháng mà không nhận ra phần lớn là lãng phí thuần túy. Bài đầu trong series 2 phần phân tích chi tiết kinh tế token và 5 cái bẫy phổ biến nhất. Token caching từ Anthropic có thể giảm 90% chi phí input - nhưng 95% vibe coder chưa bật lên.
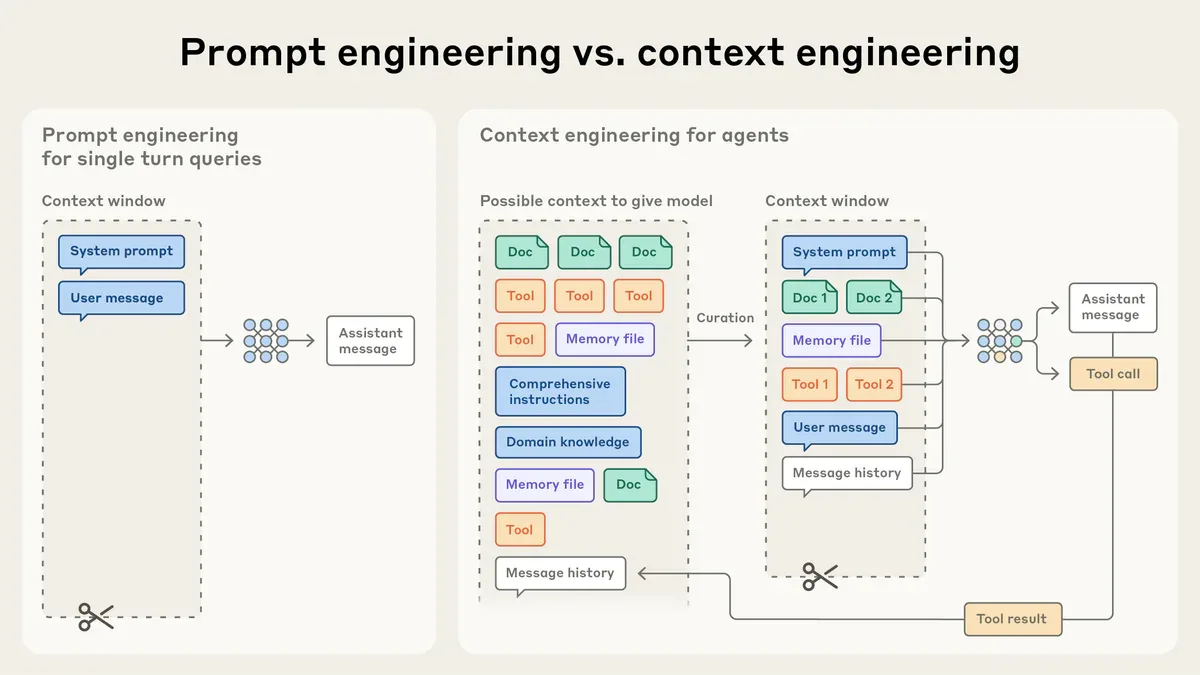
90% hóa đơn AI coding của bạn là tiền trả cho context bạn không cần gửi
70-87% tokens trong một coding agent session là waste - không phải code generation. Kỹ thuật context engineering đúng có thể giảm chi phí từ $6-8 xuống $1.50-2.70 mỗi session. Model routing 3 tầng tiết kiệm 51% so với chạy đồng nhất Opus 4.6. Kimi K2.6 vượt GPT-5.4 trên SWE-Bench Pro với chi phí input thấp hơn 8.3 lần.

Claude Context: MCP Plugin giúp Claude Code tiết kiệm 39% token bằng semantic search
Claude Context là MCP plugin open-source của Zilliz, thay thế grep-only bằng hybrid BM25 + vector search trên toàn codebase. Benchmark chính thức: 44.4K token so với 73.4K (-39.4%) và 5.3 tool calls so với 8.3 (-36.3%). Monorepo 12,000 file được index trong 3-6 phút, hỗ trợ OpenAI, VoyageAI, Ollama và Gemini. MIT license, self-host hoàn toàn được với Milvus + Ollama, không cần trả thêm gì ngoài ops cost.

10 Repos Giảm Token Bill AI Agent Tới 80% - Không Ai Kiểm Tra Cái Đang Gửi Đi
Hầu hết AI agent tốn kém không phải vì model đắt, mà vì không ai kiểm soát lượng token gửi đi. 10 open-source repos này giải quyết vấn đề đó ở 7 layer khác nhau. LLMLingua nén prompt tới 20x trước khi gọi API với gần như không mất chất lượng. mem0 cô đọng 10,000 token conversation history xuống còn 200 token per agent. LiteLLM route tác vụ đơn giản sang Haiku thay vì Sonnet - tiết kiệm 20x chi phí trên cùng một output.

5 Bước Dùng Claude Không Bị Sớm Hết Limit
Claude Pro giới hạn ~44,000 token mỗi 5 tiếng, Max 20x chỉ có 200-800 prompt/window. Chỉ cần 5 thay đổi nhỏ trong workflow, bạn có thể tiết kiệm 60-70% token mà không cần nâng cấp plan. Chiến lược "escalate model" - dùng Haiku brainstorm rồi mới chuyển Opus - tiết kiệm ~67% chi phí mỗi tác vụ. Từ Plan Mode trong Claude Code đến bộ nhớ markdown, đây là framework đã được kiểm chứng qua thực tế.

Router Architecture: Giảm 80% Bill AI Coding Mà Không Mất Chất Lượng
Routing 80% task coding thông thường sang model rẻ hơn giúp tiết kiệm 70-97% chi phí API. DeepSeek V3 qua OpenRouter chỉ $0.14/M token, rẻ hơn Claude Sonnet 100 lần. RouteLLM (ICLR 2025) chứng minh đạt 95% chất lượng GPT-4 với chỉ 14% GPT-4 calls. Kiến trúc 3 tier Fast-Smart-Power giúp phân luồng task tự động mà không cần thay đổi code.