
- LLM engineer senior hiện kiếm $200K-$320K/năm và freelance $175-250/giờ - premium 30-60% so với ML engineer thông thường.
- Bài Phần 1 hướng dẫn 3 nền tảng không thể bỏ qua: Python chuyên sâu, Neural Networks và kiến trúc Transformer ra đời từ bài báo lịch sử 'Attention Is All You Need'.
- Không cần PhD, không cần Silicon Valley.
TL;DR
AI không còn là lãnh thổ riêng của các công ty công nghệ lớn. Năm 2026, một developer solo với đúng kỹ năng có thể xây sản phẩm AI, fine-tune model và kiếm thu nhập USD từ xa. LLM engineer senior hiện hưởng mức lương $200K-$320K và freelance $175-$250/giờ - cao hơn 30-60% so với ML engineer thông thường. Bài Phần 1 này tập trung vào 3 nền tảng không thể bỏ qua: Python, Neural Networks và kiến trúc Transformer.
LLM Architecture là gì?
LLM Architecture là thiết kế hệ thống hoàn chỉnh đằng sau một mô hình ngôn ngữ. Nó không chỉ là code - mà là bản thiết kế tổng thể bao gồm:
- Thu thập và xử lý dữ liệu
- Tokenization và Embeddings
- Mạng Transformer và cơ chế Attention
- Pipeline huấn luyện và fine-tuning
- Tối ưu hóa inference và triển khai
- Hệ thống bộ nhớ và truy xuất (RAG)
Nói đơn giản: đây là bản vẽ kỹ thuật giúp AI hiểu ngôn ngữ, dự đoán văn bản và tương tác như con người. Stanford đã nhận ra tầm quan trọng này và ra mắt khóa CS336 - "Language Modeling from Scratch" - dạy sinh viên xây mô hình từ đầu, từ thu thập dữ liệu đến triển khai hoàn chỉnh.
Tại sao kỹ năng này cực kỳ giá trị?
Công ty không chỉ cần người "prompt AI". Họ cần người xây dựng hạ tầng AI, customize model, giảm chi phí API và tạo hệ thống AI riêng. Kết quả là thị trường bùng nổ:
- Cầu về freelance LLM tăng 304% năm 2025 (Upwork Future Workforce Report)
- Mức lương trung bình AI engineer đạt $206K năm 2025, tăng $50K so với năm trước
- LLM senior freelance: $175-$250/giờ; specialist fine-tuning: $350-$700+/giờ
- LLM-specific roles có premium 30-60% so với ML engineer thông thường
- Deep learning - nền tảng của LLM - xuất hiện trong 28.1% tổng số tin tuyển dụng AI engineer
Khoảng cách cung-cầu ngày càng rộng: cung kỹ sư có 2+ năm kinh nghiệm LLM thực tế chỉ tăng 85% trong khi cầu tăng 304%. Đây là cơ hội hiếm có cho những ai học đúng lúc.
Bước 1: Python - nền tảng bắt buộc
Mọi AI engineer nghiêm túc đều bắt đầu với Python. Trước khi chạm vào LLM, bạn cần thành thạo:
- Căn bản vững chắc: functions, classes, async programming, data structures
- Xử lý dữ liệu: file handling, JSON processing, NumPy, Pandas
- Kết nối hệ thống: APIs, HTTP requests, error handling
Lý do không thể bỏ qua: toàn bộ hệ sinh thái LLM - từ PyTorch, HuggingFace đến LangChain - đều chạy trên Python. Khóa CS336 của Stanford yêu cầu sinh viên viết lượng code gấp 10 lần các khóa AI thông thường - và đó hoàn toàn là Python. Kỹ năng Python càng chắc, mọi bước tiếp theo càng dễ dàng.
Bước 2: Neural Networks - hiểu trước khi build
Trước khi xây Transformer, bạn cần nắm vững deep learning cơ bản. Không cần học thuộc lý thuyết, nhưng phải hiểu bản chất hoạt động:
- Neurons và Layers: thông tin truyền qua mạng như thế nào
- Gradient Descent: mô hình học từ sai lầm ra sao
- Loss Functions: cách đo lường mức độ "sai" của mô hình
- Backpropagation: cơ chế cập nhật trọng số tự động
Framework được khuyên dùng: PyTorch - linh hoạt, thân thiện với nghiên cứu và là chuẩn công nghiệp cho hầu hết LLM engineer. TensorFlow vẫn có chỗ đứng trong production, nhưng PyTorch chiếm ưu thế áp đảo trong cộng đồng AI 2026.
Bước 3: Transformer - trái tim của AI hiện đại
Năm 2017, bài báo "Attention Is All You Need" của Google thay đổi toàn bộ ngành NLP. Transformer giải quyết điểm yếu chết người của RNN - xử lý tuần tự, chậm, mất ngữ cảnh khi chuỗi dài - bằng cách phân tích tất cả token song song qua cơ chế self-attention.
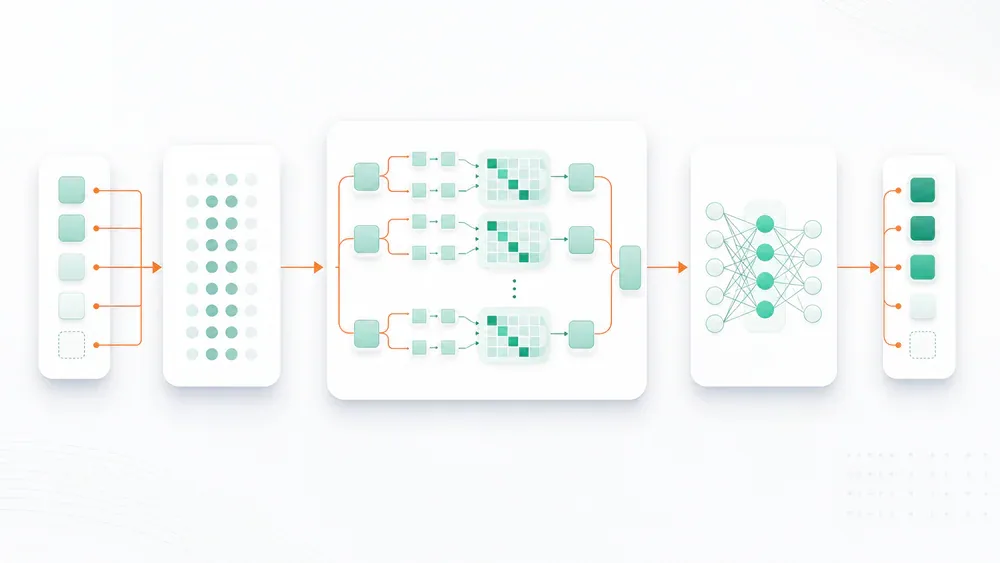
Nhờ đó:
- Tận dụng tối đa GPU cho parallel computing
- Hiểu ngữ cảnh xa tốt hơn nhiều so với RNN/LSTM
- Scale lên hàng tỷ tham số mà vẫn train hiệu quả
Tuy nhiên, Transformer có giới hạn kỹ thuật cần biết: độ phức tạp self-attention tăng theo O(n²) với độ dài chuỗi - nghĩa là context dài = tốn kém hơn theo cấp số nhân. Model cũng dễ "hallucinate" vì không có khả năng suy luận symbolic thực sự. Đây là những vấn đề mà engineer giỏi phải biết thiết kế để giảm thiểu.
Kết - Preview Phần 2
Ba bước đầu - Python, Neural Networks và Transformers - là nền móng của mọi LLM engineer. Không cần PhD, không cần kết nối ở Silicon Valley. Bạn chỉ cần học đúng thứ tự và thực hành liên tục.
Phần 2 sẽ đi sâu vào 4 khái niệm cốt lõi (Tokenization, Embeddings, Attention Mechanism, Fine-tuning) và cách build hệ thống RAG - kỹ năng đáng giá nhất năm 2026 để tạo private AI assistants cho doanh nghiệp - cùng với hướng dẫn deploy lên production bằng FastAPI và Docker.
via Stanford CS336 · Second Talent 2026 · KORE1 Hiring Guide
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ